Flatiron School NYC에서 제 연구의 첫 번째 모듈을 마친 후 Seaborn과 Matplotlib를 사용하여 플롯 사용자 정의 및 디자인을 시작했습니다. 수업 중 낙서와 마찬가지로, 저는 jupyter 노트북에 다른 스타일의 플롯을 코딩하기 시작했습니다.
이 기사를 읽고 나면 모든 노트북에 대해 최소한 하나의 빠른 스타일의 플롯 코드를 염두에 두어야합니다.
더 이상 기본값, 상점 브랜드, 기본 플롯,부디!
아무것도 할 수 없다면 Seaborn을 사용하십시오.
괜찮아 보이는 플롯을 만드는 데 5 초가 주어지지 않으면 세상이 붕괴 될 것입니다. Seaborn을 사용하십시오!
Matplotlib를 사용하여 빌드 된 Seaborn은 즉각적인 디자인 업그레이드가 될 수 있습니다. x 및 y 값의 레이블과 기본이 아닌 기본 색 구성표를 자동으로 할당합니다. (— IMO : 좋은, 명확하고, 잘 포맷 된 열 레이블링과 데이터 정리를 통해 보상합니다.) Matplotlib는이를 자동으로 수행하지 않지만 플롯하려는 항목에 따라 항상 x와 y를 정의하도록 요청하지 않습니다.
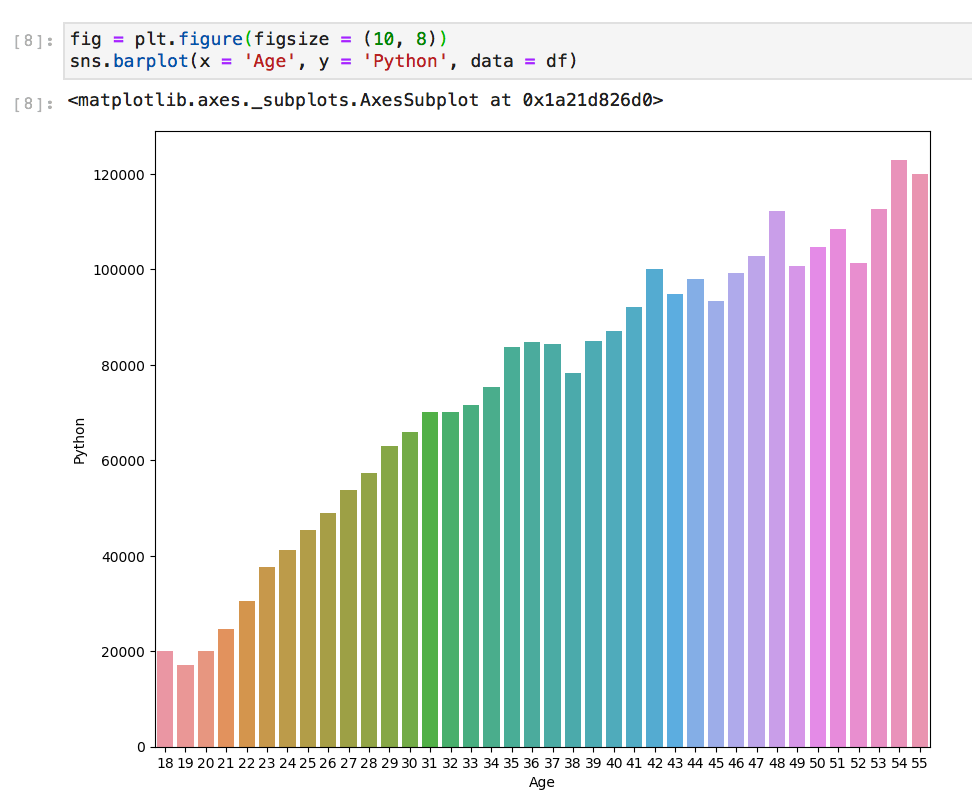
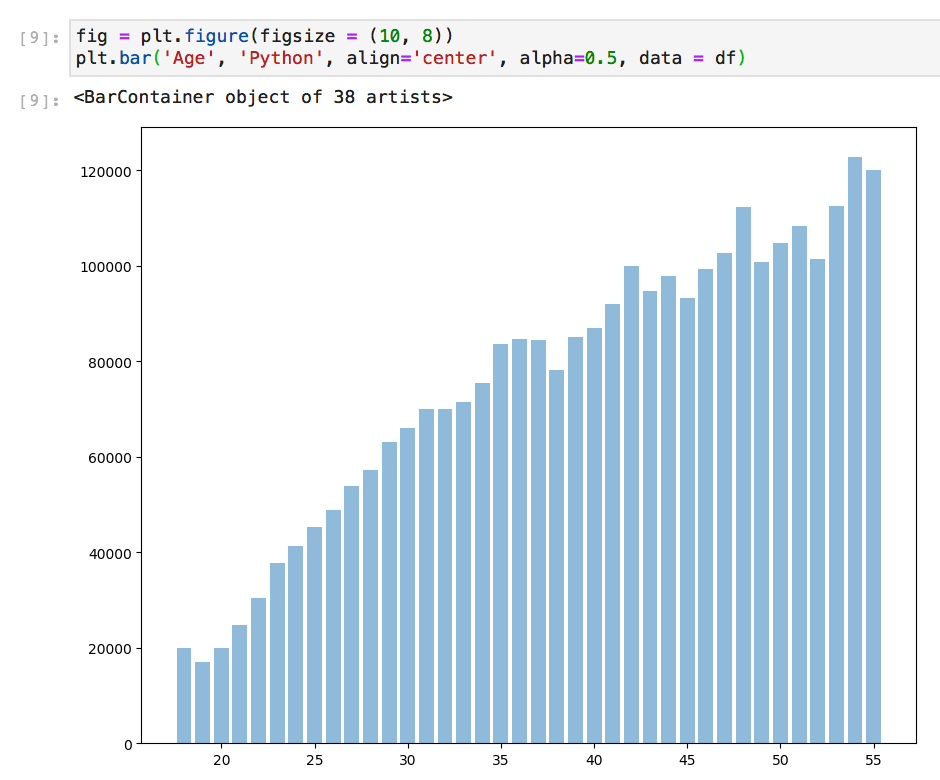
다음은 Seaborn을 사용하는 것과 사용자 정의가없는 Matplotlib를 사용하는 동일한 플롯입니다.
After completing the first module in my studies at Flatiron School NYC, I started playing with plot customizations and design using Seaborn and Matplotlib. Much like doodling during class, I started coding other styled plots in our jupyter notebooks.
After reading this article, you’re expected to have at least one quick styled plot code in mind for every notebook.
No more default, store brand, basic plots, please!
If you can do nothing else, use Seaborn.
You have five seconds to make a decent looking plot or the world will implode; use Seaborn!
Seaborn, which is build using Matplotlib can be an instant design upgrade. It automatically assigns the labels from your x and y values and a default color scheme that’s less… basic. ( — IMO: it rewards good, clear, well formatted column labeling and through data cleaning) Matplotlib does not do this automatically, but also does not ask for x and y to be defined at all times depending on what you are looking to plot.
Here are the same plots, one using Seaborn and one Matplotlib with no customizations.
Depending on the data you are visualizing, changing the style and backgrounds may increase interpretability and readability. You can carry this style throughout by implementing a style at the top of your code.
There is a whole documentation page on styline via Matplotlib.
Styling can be as simple as setting the style with a simple line of code after your imported libraries. GGPlot changed the background to grey, and has a specific font. There are many more styles you can tryout.
Using plot styling, Matplotlib (top) Seaborn (bottom) Notice that Seaborn automatically labeled the plot.
XKCD; a cheeky little extra
Fun. Not professional. But so fun.
Be aware that if you use this XKCD style it will continue until you reset the defaults by running plt.rcdefaults()…
PRETTY COLORS OMG!
- Seaborn single color names. These can also be used in Matplot Lib. Image from Matplotlib.org
Make your plots engaging. Color theory comes into play here. Seaborn has a mix of palettes which can also be used in Matplot lib, plus you can also make your own.
Single Colors: One and Done
Above is a list of single color names you can call to change lines, scatter plots, and more.
Lazy? Seaborn’s Default Themes
has six variations of default
deep, muted, pastel, bright, dark, and colorblind
use color as an argument after passing in x, y, and data
color = ‘colorblind’
Work Smarter Not Harder: Pre-Fab Palettes
color_palette() accepts any seaborn palette or matplotlib colormap
create a kind and add in specifics, play around with the parameters for more customized palettes
Many ways to choose a color palette.
Everything Should Have a Label
Here we are using Matplotlib, but we have added a single color for each line, a title, x and y labels, and a legend for clear concise interpretation.
Every variable has a home, and it sparks joy now, right? — Think how would Marie Kondo code.
Simple, but clear.
Overall, pretty simple right? Well, now you have no excuses for those ugly basic plots. I hope you found this helpful and mayb a little bit fun. There’s so much more on color and design in the documentation, so once you’ve mastered these quick tips, dive in on the documentation below!
In this post I would like to describe in detail our setup and development environment (hardware & software) and how to get it, step by step.
저는 많은 회사에서 거의 변경 (주로 하드웨어 개선)없이이 설정을 5 년 이상 사용해 왔으며 수십 개의 데이터 프로젝트 개발에 도움을주었습니다. 사용하는 동안 하나의 기능을 놓치지 않았습니다. 이것은 표준 설정입니다.페드로과나를사용WhiteBox.
왜이 가이드인가? 시간이 지남에 따라 몇 가지 기본 기능을 갖춘 견고한 환경을 찾고있는 많은 학생과 동료 데이터 과학자를 발견했습니다.
Python, R 및 해당 라이브러리와 같은 표준 데이터 과학 도구는 설치 및 유지 관리가 쉽습니다.
대부분의 라이브러리는 추가 구성없이 바로 작동합니다.
스몰 데이터에서 빅 데이터까지, 그리고 표준 머신 러닝 모델에서 딥 러닝 프로토 타이핑에 이르기까지 데이터 관련 작업의 전체 스펙트럼을 다룰 수 있습니다.
값 비싼 하드웨어와 소프트웨어를 구입하기 위해 은행 계좌를 깰 필요가 없습니다.
하드웨어
노트북에는 다음이 있어야합니다.
최소 16GB RAM. 이는 Dask 또는 Spark와 같은 도구를 사용하지 않고 메모리에서 쉽게 처리 할 수있는 데이터의 양을 제한하므로 가장 중요한 기능입니다. 많을수록 좋습니다. 여유가 있다면 32GB를 사용하십시오.
강력한 프로세서. 코어가 4 개인 Intel i5 또는 i7 이상. 명백한 이유로 데이터를 처리하는 동안 많은 시간을 절약 할 수 있습니다.
최소 4GB RAM의 NVIDIA GPU. 간단한 딥 러닝 모델을 프로토 타입하거나 미세 조정해야하는 경우에만 가능합니다. 해당 작업에 대해 거의 모든 CPU보다 훨씬 빠릅니다.랩톱에서 처음부터 심각한 딥 러닝 모델을 훈련 할 수는 없습니다..
좋은 냉각 시스템. 최소한 몇 시간 동안 워크로드를 실행합니다. 노트북이 녹지 않고 처리 할 수 있는지 확인하십시오.
256GB 이상의 SSD이면 충분합니다.
더 큰 SSD, 더 많은 RAM을 추가하거나 배터리를 쉽게 교체하는 등의 기능을 업그레이드 할 수 있습니다.
개인적으로 추천하는 것은 중고 Thinkpad 워크 스테이션 노트북입니다. 나는 초침이있다P50위에 나열된 모든 기능을 충족하는 500 유로에 구입했습니다.
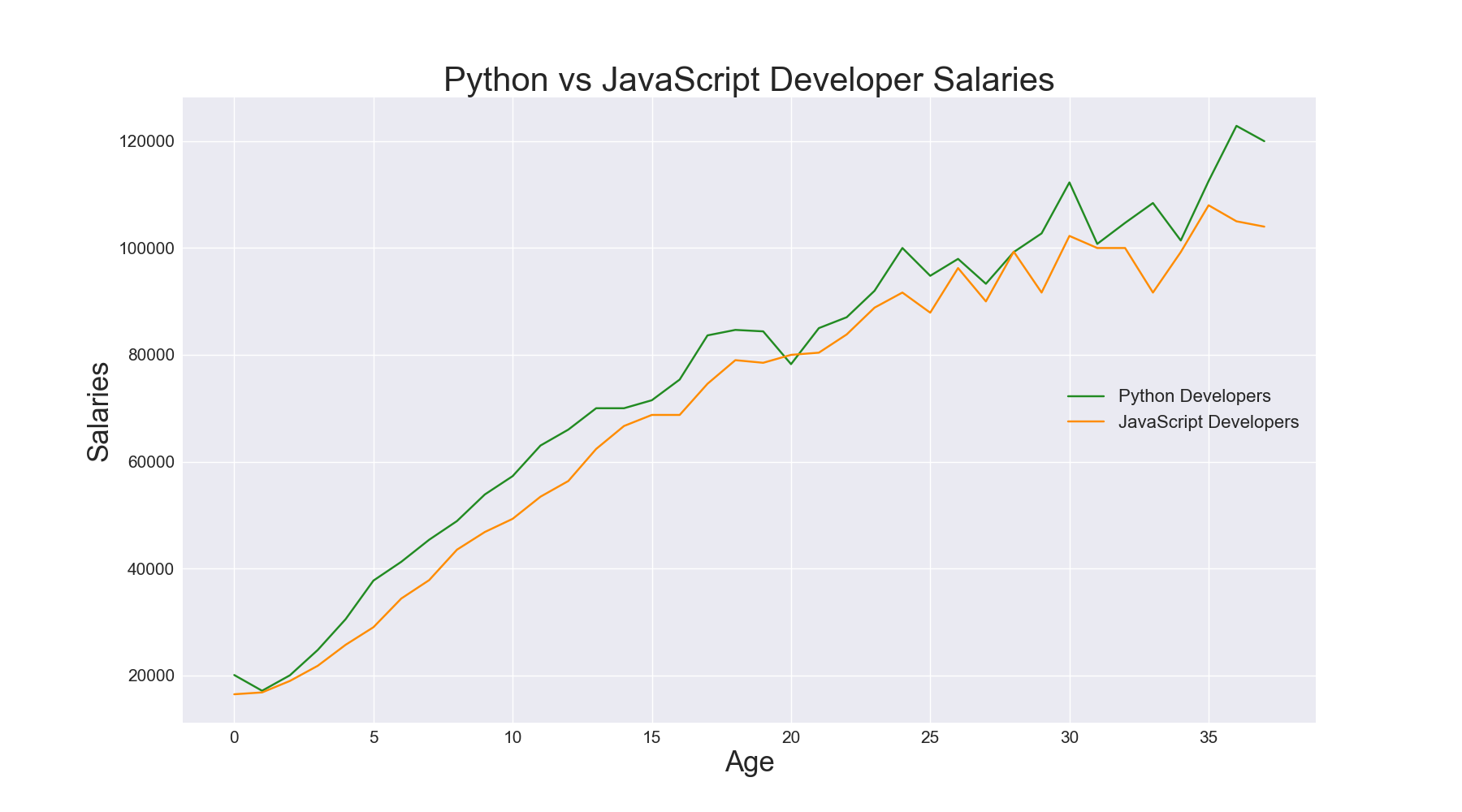
david-laptop 사양
Thinkpad는 우리가 수년 동안 사용해 왔지만 결코 실패한 적이없는 뛰어난 전문가 용 노트북입니다. 핸디캡은 가격이지만 많은 대기업이 임대 계약을 맺고 2 년마다 랩톱을 폐기하므로 사용 조건이 매우 좋은 중고 씽크 패드를 많이 찾을 수 있습니다. 이러한 노트북 중 상당수는 중고 시장에서 끝납니다. 다음에서 검색을 시작할 수 있습니다.
이러한 중고 시장의 대부분은 보증 및 송장을 제공 할 수 있습니다 (귀하가 회사 인 경우). 이 게시물을 읽고 중대형 조직에 속한 경우 가장 좋은 방법은 제조업체와 직접 임대 계약에 도달하는 것입니다.
Lenovo Thinkpad P52
Apple MacBook을 피하십시오:
여러 가지 이유로 OSX를 정말 좋아하지 않는 한 Apple 노트북을 피해야합니다. 그들은디자인 분야의 전문가와 음악 제작자를위한, 사진 작가, 동영상 및 사진 편집자, UX / UI, 웹 개발자와 같이 무거운 작업을 실행할 필요가없는 개발자도 마찬가지입니다. 2011 년부터 2016 년까지 제 주 노트북은 맥북 이었기 때문에 그 한계를 잘 알고 있습니다. 하나를 사지 않는 주된 이유는 다음과 같습니다.
동일한 하드웨어에 대해 훨씬 더 많은 비용을 지불하게됩니다.
끔찍한 공급 업체 종속으로 인해 다른 대안으로 변경하는 데 막대한 비용이 듭니다.
NVIDIA GPU를 사용할 수 없으므로 랩톱에서 딥 러닝 프로토 타이핑은 잊어 버리십시오.
마더 보드에 납땜되어 있으므로 하드웨어를 업그레이드 할 수 없습니다. 더 많은 RAM이 필요한 경우 새 노트북을 구입해야합니다.
울트라 북 (일반)을 피하십시오:
대부분의 울트라 북은 가벼운 워크로드, 웹 브라우징, 사무 생산성 소프트웨어 등을 위해 설계되었습니다. 대부분은 위에 나열된 냉각 시스템 요구 사항을 충족하지 못하며 수명이 짧습니다. 또한 업그레이드 할 수 없습니다.
운영 체제
데이터 과학 용으로 사용되는 운영 체제는 Ubuntu의 최신 LTS (장기 지원)입니다. 이 글을 쓰는 시점에서Ubuntu 20.04 LTS최신입니다.
Ubuntu 20.04 LTS
Ubuntu는 데이터 과학자로서 다른 운영 체제 및 기타 Linux 배포판에 비해 몇 가지 이점을 제공합니다.
가장 성공적인 데이터 과학 도구는 오픈 소스이며 무료 오픈 소스 인 Ubuntu에서 설치 및 사용하기 쉽습니다. 이러한 도구의 대부분의 개발자는 아마도 Linux를 사용하고있을 것입니다. TensorFlow, PyTorch 등과 같은 GPU를 지원하는 딥 러닝 프레임 워크의 경우 특히 그렇습니다.
데이터 작업을 할 때 보안은 설정의 핵심이되어야합니다. Linux는 기본적으로 Windows 또는 OS X보다 더 안전하며 소수의 사람들이 사용하기 때문에 대부분의 악성 소프트웨어는 Linux에서 실행되도록 설계되지 않았습니다.
데스크탑과 서버 모두에서 가장 많이 사용되는 Linux 배포판이며 훌륭하고 지원적인 커뮤니티입니다. 제대로 작동하지 않는 문제를 발견하면 도움을 받거나 문제 해결 방법에 대한 정보를 찾는 것이 더 쉽습니다.
대부분의 서버는 Linux 기반입니다., 해당 서버에 코드를 배포하고 싶을 것입니다. 프로덕션에 배포 할 환경에 가까울수록 좋습니다. 이것이 Linux를 플랫폼으로 사용하는 주된 이유 중 하나입니다.
운이 좋으면 전용 GPU를 사용할 수있는 경우 그래픽 전용 드라이버를 설치하지 마십시오 (설치하는 동안 확인란이 선택되지 않음). 기본 드라이버가 버그가 있고 특정 GPU (제 경우와 같이)에서 외부 모니터가 제대로 작동하지 않을 수 있으므로 나중에 설치할 수 있습니다.
설치하는 동안 타사 소프트웨어 선택 취소
설치 USB를 올바르게 만드십시오. Linux에 액세스 할 수 있으면 사용할 수 있습니다.시동 디스크 작성기, Windows 또는 OSX의 경우balenaEtcher확실한 선택입니다.
NVIDIA 드라이버
NVIDIA Linux 지원은 수년 동안 커뮤니티의 불만 중 하나였습니다. 유명한 것을 기억하십시오.
NVIDIA: 젠장!
Linus Torvalds가 NVIDIA에 대해 이야기
운 좋게도 상황이 바뀌었고 지금은 여전히 엉덩이에 통증이 있지만 모든 것이 더 쉽습니다.
conda를 초기화했는지 확인하십시오.예설치 스크립트가 물어볼 때!) 해당 줄이.bashrc파일:
# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$('/home/david/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__conda_setup" else if [ -f "/home/david/miniconda3/etc/profile.d/conda.sh" ]; then . "/home/david/miniconda3/etc/profile.d/conda.sh" else export PATH="/home/david/miniconda3/bin:$PATH" fi fi unset __conda_setup # <<< conda initialize <<<
콘다 앱이 추가됩니다.통로언제든지 액세스 할 수 있습니다. conda가 제대로 설치되었는지 확인하려면 다음을 입력하십시오.콘다터미널에서 :
콘다 도움말
conda 가상 환경에서 원하는 Python 버전은 물론 R, Java, Julia, Scala 등을 설치할 수 있습니다.
conda 및 pip 패키지 관리자 모두에서 라이브러리를 설치할 수도 있으며 동일한 가상 환경에서 완벽하게 호환되므로 둘 중 하나를 선택할 필요가 없습니다.
conda에 대해 한 가지 더 :
conda는 코드 배포를위한 고유 한 기능을 제공합니다. 라는 도서관입니다콘다 팩그리고 그것은절대로 필요한 것우리를 위해. 여러 번 액세스 할 수없는 인터넷 격리 클러스터에 라이브러리를 배포하는 데 도움이되었습니다.씨, 아니python3필요한 것을 설치하는 간단한 방법이 없습니다.
이 라이브러리를 사용하면.tar.gz원하는 곳에서 압축을 풀 수 있습니다. 그런 다음 환경을 활성화하고 평소처럼 사용할 수 있습니다.
Jupyter는 대화 형 프로그래밍 환경이 필요한 개발을 위해 데이터 과학자에게 필수입니다.
제가 몇 년 동안 배운 비결은 로컬 JupyterHub 서버를 만들고 시스템 서비스로 구성하여 매번 서버를 시작할 필요가 없도록하는 것입니다 (노트북이 시작 되 자마자 서버가 항상 가동되고 대기합니다). 또한 모든 환경에서 Python / R 커널을 감지하고 Jupyter에서 자동으로 사용할 수 있도록하는 라이브러리를 설치합니다.
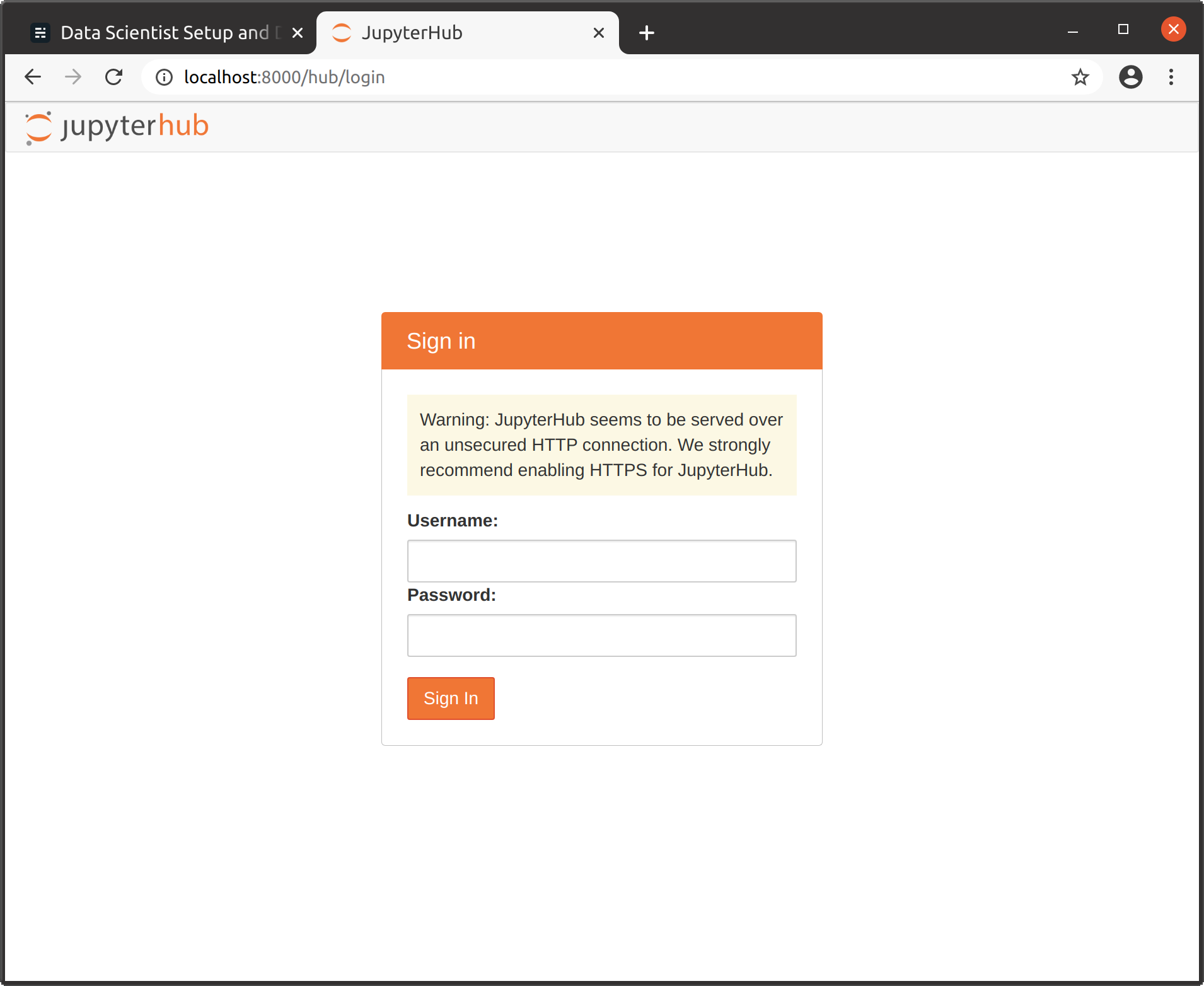
9. 이제 다음으로 이동할 수 있습니다.localhost : 8000및 로그인Linux 사용자 및 비밀번호로:
JupyterHub 로그인 페이지
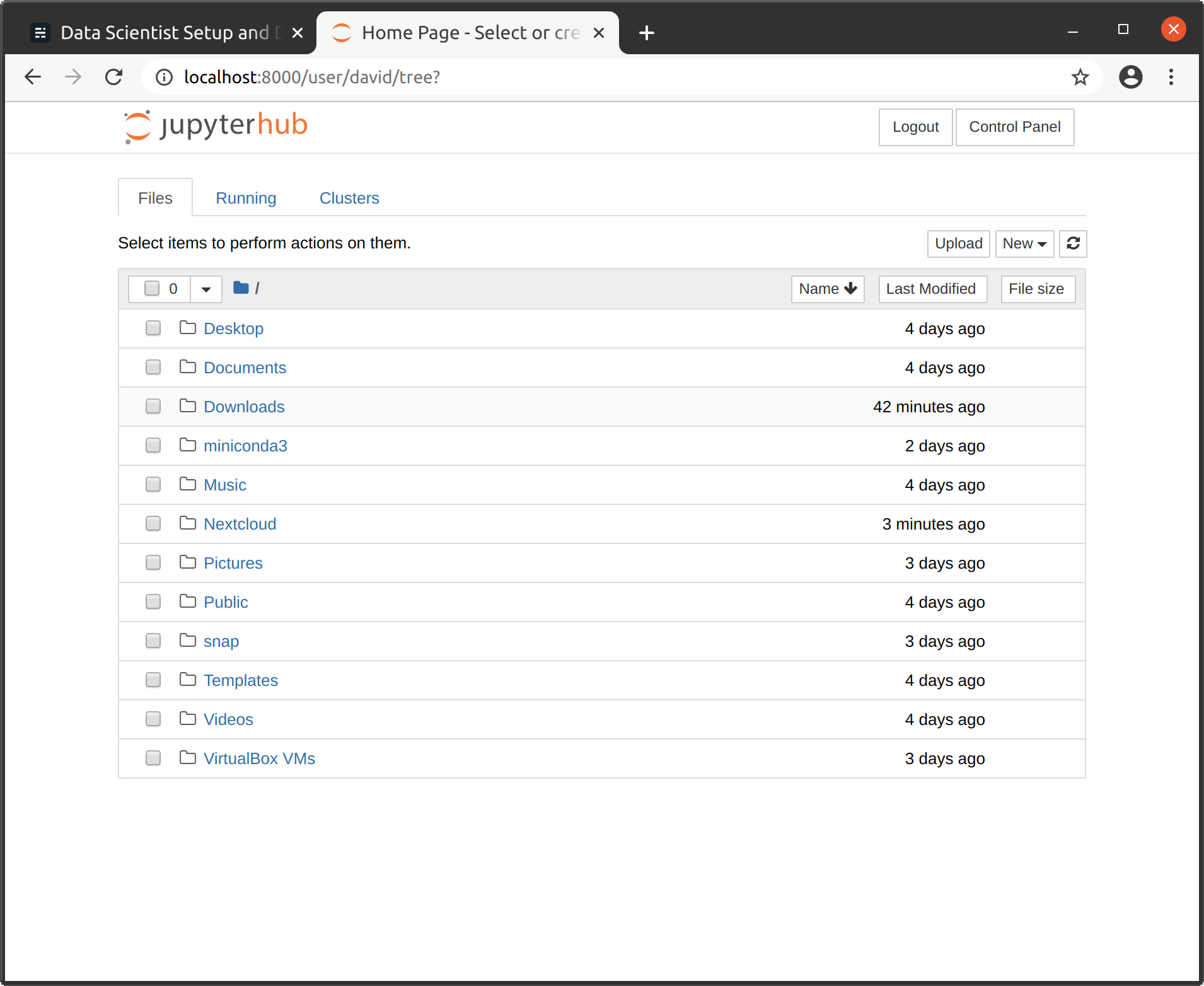
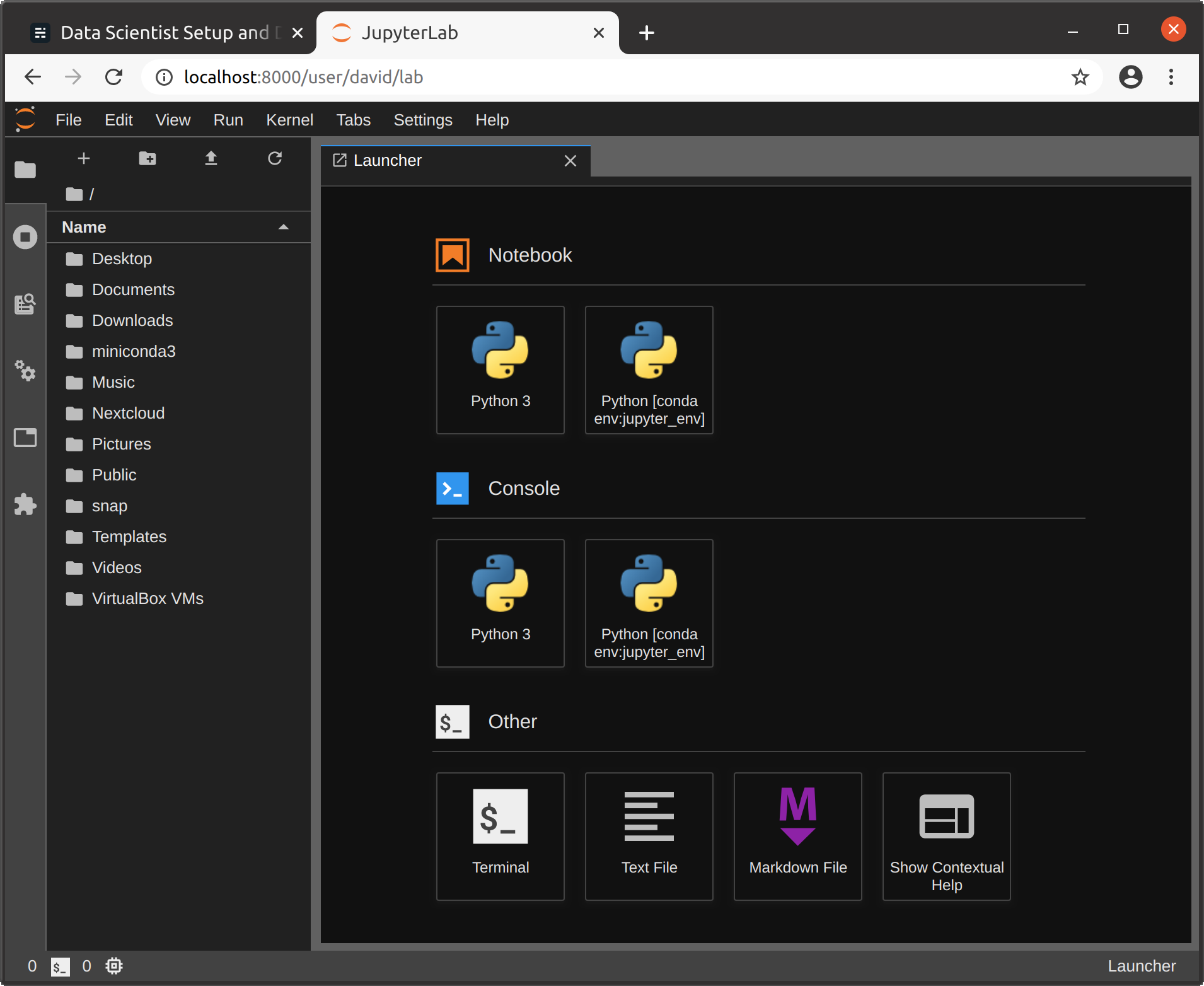
10. 로그인 후 클래식 모드에서 본격적인 Jupyter 서버에 액세스 할 수 있습니다 (/나무) 또는 최신 JupyterLab (/랩) :
Jupyter (클래식)
Jupyter (실험실)
이 Jupyter 설정의 가장 흥미로운 기능은 모든 conda 환경에서 커널을 감지하므로 여기에서 번거 로움없이 해당 커널에 액세스 할 수 있다는 것입니다. 해당 커널을 설치하십시오.원하는 환경에서(conda 설치 ipykernel, 또는conda 설치 irkernel) 및 JupyterHub 제어판에서 Jupyter 서버를 다시 시작합니다.
JupyterHub 제어판
커널을 설치하려는 환경을 이전에 활성화해야합니다! (conda activate <env_name>).
아시다시피 저는FOSS특히 데이터 생태계의 솔루션입니다. 소수 중 하나소유권여기서 추천 할 소프트웨어는 우리가 사용하는 소프트웨어입니다.IDE:PyCharm. 코드에 대해 진지하게 생각한다면 PyCharm과 같은 IDE를 사용하고 싶을 것입니다.
코드 완성 및 환경 검사.
네이티브 conda 지원을 포함한 Python 환경.
디버거.
Docker 통합.
Git 통합.
과학 모드 (pandas DataFrame 및 NumPy 배열 검사).
PyCharm Professional
다른 인기있는 선택에는 Pycharm의 안정성과 기능이 없습니다.
Visual Studio Code : IDE보다 텍스트 편집기에 가깝습니다. 플러그인을 사용하여 확장 할 수 있다는 것을 알고 있지만 PyCharm만큼 강력하지는 않습니다. 여러 언어로 된 프로젝트가있는 웹 개발자라면 Visual Studio Code가 좋은 선택 일 수 있습니다. 웹 개발자이고 Python이 백엔드 용으로 선택한 언어라면 데이터에 있지 않더라도 Pycharm을 사용하십시오.
Jupyter: if you have doubts about when you should be using Jupyter or PyCharm and call yourself a Data <whatever>, please attend 부트 캠프 중 하나우리는 최대한 빨리 가르칩니다.
PyCharm 설치에 대한 우리의 조언은스냅이므로 설치가 자동으로 업데이트되고 나머지 시스템과 격리됩니다. 커뮤니티 (무료) 버전 :
sudo snap install pycharm-community --classic
스칼라
Scala는 기본 Spark로 빅 데이터 프로젝트에 사용하는 언어이지만 PySpark로 전환하고 있습니다.
여기에서 우리의 추천은IntelliJ IDEA. PyCharm 개발자 (JetBrains)의 JVM 기반 언어 (Java, Kotlin, Groovy, Scala) 용 IDE입니다. 가장 좋은 기능은 Scala에 대한 기본 지원과 PyCharm과의 유사점입니다. Eclipse에서 온 경우 키 바인딩 및 단축키를 수정하여 Eclipse를 복제 할 수 있습니다.
Dask: 일을 많이 단순화하는 Dask는 일종의 Python 용 기본 Spark입니다. pandas 및 NumPy API에 더 가깝지만 경험상 Spark만큼 강력하지는 않습니다. 우리는 때때로 그것을 사용합니다.
모딘: 멀티 코어 및 아웃 오브 코어 계산을 지원하는 Pandas API를 복제합니다. 많은 코어 (32, 64)가있는 강력한 분석 서버에서 작업하고 pandas를 사용하려는 경우 특히 유용합니다. 일반적으로 코어 당 성능이 좋지 않기 때문에 Modin을 사용하면 계산 속도를 높일 수 있습니다.
데이터베이스 도구
때로는 다양한 DB 기술과 연결하고 쿼리를 만들고 데이터를 탐색 할 수있는 도구가 필요합니다. 우리의 선택은DBeaver:
DBeaver 커뮤니티
DBeaver는 다양한 데이터베이스의 드라이버를 자동으로 다운로드하는 도구입니다. 다음을 지원합니다.
데이터베이스, 스키마, 테이블 및 열 이름 완성.
연결을위한 고급 네트워킹 요구 사항 (예 : SSH 터널 등)
다음과 같이 DBeaver를 설치할 수 있습니다.
sudo snap install dbeaver-ce
가작 :
DataGrip: JetBrains의 데이터베이스 IDE는 때때로 DBeaver와 매우 유사하며 지원되는 기술은 적지 만 매우 안정적입니다.sudo snap install datagrip --classic
In this post I would like to describe in detail our setup and development environment (hardware & software) and how to get it, step by step.
I have been using this setup for more than 5 years with little changes (mainly hardware improvements), in many companies, and helped me in the development of dozens of Data projects. Never missed a single feature while using it. This is the standard setup both Pedro and me use at WhiteBox.
Why this guide? Over time, we found many students and fellow Data Scientists looking for a solid environment with some fundamental features:
Standard Data Science tools like Python, R, and its libraries are easy to install and maintain.
Most libraries just work out of the box with little extra configuration.
Allows to cover the full spectrum of Data related tasks, from Small to Big Data, and from standard Machine Learning models to Deep Learning prototyping.
Do not need to break your bank account to buy expensive hardware and software.
Hardware
Your laptop should have:
At least 16GB of RAM. This is the most important feature as it will limit the amount of data you can easily process in memory (without using tools like Dask or Spark). The more the better. Go with 32GB if you can afford it.
A powerful processor. At least an Intel i5 or i7 with 4 cores. It will save you a lot of time while processing data for obvious reasons.
A NVIDIA GPU of at least 4GB of RAM. Only if you need to prototype or fine-tune simple Deep Learning models. It will be orders of magnitude faster than almost any CPU for that task. Remember that you can’t train serious Deep Learning models from scratch in a laptop.
A good cooling system. You are going to run workloads for at least hours. Make sure your laptop can handle it without melting.
A SSD of at least 256GB should be enough.
Possibility to upgrade its capabilities, like adding a bigger SSD, more RAM, or easily replace battery.
My personal recommendation is getting a second hand Thinkpad workstation laptop. I have an second hand P50 I bought for 500€ which meets all features listed above:
david-laptop specs
Thinkpads are excellent professional laptops we have been using for years and never failed us. Its handicap is the price, but you can find lots of second hand Thinkpads in very good using conditions as many big corporations have leasing agreements and dispose laptops every 2 years. Many of these laptops end in the second hand market. You can start your search in:
Many of these second hand markets can provide warranty and an invoice (in case you are a company). If you are reading this post and belong to a middle to big sized organization, the best option for you is probably reaching a leasing agreement directly with the manufacturer.
Lenovo Thinkpad P52
Avoid Apple MacBooks:
For a variety of reasons, you should avoid an Apple laptops unless you really (and I mean, really) love OSX. They are intended for professionals from the design field and music producers, like photographers, video and photo editors, UX/UI, and even developers who don’t need to run heavy workloads, like Web Developers. My main laptop from 2011 to 2016 was a MacBook, so I know its limitations very well. Main reasons not to buy one are:
You are going to pay much more for the same hardware.
You will suffer a terrible vendor lock-in, which means a huge cost to change to other alternative.
You can’t have a NVIDIA GPU, so forget about Deep Learning prototyping in your laptop.
Can not upgrade its hardware as it is soldered to the motherboard. In case you need more RAM, you have to buy a new laptop.
Avoid Ultrabooks (in general):
Most ultrabooks are designed for light workloads, web browsing, office productivity software and similar. Most of them does not meet the cooling system requirement listed above, and its life will be short. They are also not upgradable.
Operating System
Our go-to operating system for Data Science is the latest LTS (Long Term Support) of Ubuntu. At the time of writing this post, Ubuntu 20.04 LTS is the latest.
Ubuntu 20.04 LTS
Ubuntu offers some advantages over other operating systems and other Linux distros for you as a Data Scientist:
Most successful Data Science tools are open-source and are easy to install and use in Ubuntu, which is also free an open-source. It makes sense as most developers of those tools are probably using Linux. It is specially true when it comes to Deep Learning frameworks with GPU support, like TensorFlow, PyTorch, etc.
As you are going to be working with Data, security must be at the core of your setup. Linux is by default, more secure than Windows or OS X, and as it is used by a minority of people, most malicious software is not designed to run on Linux.
It is the most used Linux distro, both for desktops and servers, with a great and supportive community. When you find something is not working well, it will be easier to get help or find info about how to fix it.
Most servers are Linux based, and you probably want to deploy your code in those servers. The closer you are to the environment you are going to deploy to production, the better. This is one of the main reasons to use Linux as your platform.
It has a great package manager you can use to install almost everything.
Some caveats to install Ubuntu:
If you are lucky enough to have a dedicated GPU, do not install proprietary drivers for graphics (unchecked box while installation). You can install later as default drivers are buggy and may cause external monitors to not work properly for certain GPU’s (like in my case):
Uncheck third-party software while installation
Create your installation USB properly, if you have access to Linux, can use Startup Disk Creator, for Windows or OSX, balenaEtcher is a solid choice.
NVIDIA Drivers
NVIDIA Linux support has been one of the complaints of the community for years. Remember that famous:
NVIDIA: FUCK YOU!
Linus Torvalds talking about NVIDIA
Luckily, things have changed and now, although still a pain in the ass sometimes, everything is easier.
2. Install latest available drivers (440 at the time of writing this post, use TAB key to check for available options):
sudo apt install nvidia-driver-440
Wait for the installation to finish and reboot your PC.
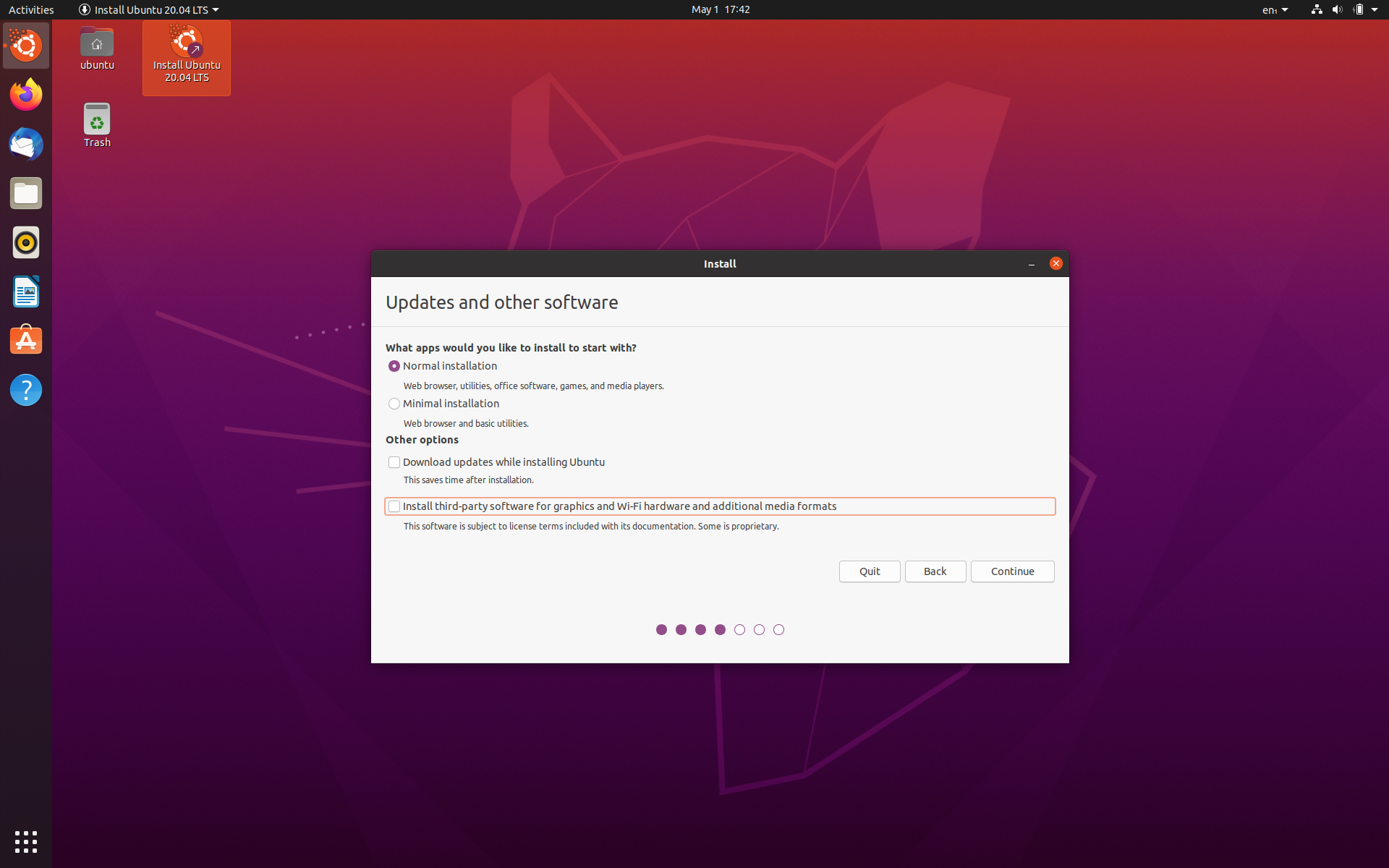
You should be able now to access NVIDIA X Server Settings:
You can use this to switch between Power Saving Mode (useful if you are not going to do any Deep Learning Stuff) and Performance Mode (allows you to use GPU, but drains your battery). Avoid On-Demand mode as it is still not working properly.
NVIDIA X Server Settings
You should also be able to run nvidia-smi application, which displays information about GPU workloads (usage, temperature, memory). You are going to use it a lot while training Deep Learning models on GPU.
nvidia-smi
Terminal
While default GNOME Terminal is OK, I prefer using Terminator, a powerful terminal emulator which allows you to split the terminal window vertically ctr + shift + e and horizontally ctr + shift + o, as well as broadcasting commands to several terminals at the same time. This is useful to setup various servers or a cluster.
Terminator
Install Terminator like this:
sudo apt install terminator
VirtualBox
VirtualBox is a software that allows you to run virtually other machines inside your current operating system session. You can also run different operating systems (Windows inside Linux, or the other way around).
It is useful in case you need a specific software which is not available for Linux, like BI and Dashboarding tools like:
VirtualBox is also useful to test new libraries and software without compromising your system, as you can just create a VM (Virtual Machine), test whatever you need and delete it.
To install VirtualBox, open your terminal and write:
sudo apt install virtualbox
Although its usage is fairly simple, it is hard to master. For an extensive tutorial of VirtualBox, check this.
Python, R and more (with Miniconda)
Python is already included with Ubuntu. But you should never use system Python or install your analytics libraries system-wide. You can break system Python doing that, and fixing it is hard.
I prefer creating isolated virtual environments I can just delete and create again in case something goes wrong. The best tool you can use to do that is conda:
Package, dependency and environment management for any language-Python, R, Ruby, Lua, Scala, Java, JavaScript, C/ C++, FORTRAN, and more.
Although many people uses conda, few people really understand how it works and what it does. It may lead to frustration.
conda is shipped in two flavors:
Anaconda: includes conda package manager and a lot of libraries (500Mb) installed. You are not going to use all those libraries and moreover will be outdated in a few days. I do not recommend going with this flavor.
Miniconda: includes just conda package manager. You still have access to all existing libraries through conda or pip, but those libraries will be downloaded and installed when they are needed. Go with this option, as it will save you time and memory.
Download Miniconda install script from here and run it:
bash Miniconda3-latest-Linux-x86_64.sh
Make sure you initialize conda (so answer yes when install script asks!) and those lines are added to your .bashrc file:
# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$('/home/david/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__conda_setup" else if [ -f "/home/david/miniconda3/etc/profile.d/conda.sh" ]; then . "/home/david/miniconda3/etc/profile.d/conda.sh" else export PATH="/home/david/miniconda3/bin:$PATH" fi fi unset __conda_setup # <<< conda initialize <<<
This will add the conda app to your PATH so you can access it anytime. To check conda is properly installed, just type conda in your terminal:
conda help
Remember that in a conda virtual environment you can install whatever Python version you want, as well as R, Java, Julia, Scala, and more…
Remember that you can also install libraries from both conda and pip package managers and don’t have to choose one of them as they are perfectly compatible in the same virtual environment.
One more thing about conda:
conda offers a unique feature for deploying your code. It is a library called conda-pack and it is a must for us. It helped us many times to get our libraries deployed in internet isolated clusters with no access to pip, no python3 and no simple way to install anything you need.
This library allows you to create a .tar.gz file with your environment you can just uncompress wherever you want. Then you can just activate the environment and use it as usual.
This is the ultimate weapon against lazy IT guys who don’t give you the right permissions to work in a given environment and don’t have time to configure it to suit your project needs. Have ssh access to a server? Then you have the environment you want and need.
Jupyter is a must for a Data Scientist, for developments where you need an interactive programming environment.
A trick I learned over the years is to create a local JupyterHub server and configure as a system service so I don’t have to launch the server every time (it is always up and waiting as soon as the laptop starts). I also install a library that detects Python/R kernels in all my environments and automatically make them available in Jupyter.
To do this:
1. First create a conda virtual environment (I usually call it jupyter_env):
8. Enable jupyterhub service, so it starts automatically at boot time:
sudo systemctl enable jupyterhub
9. Now you can go to localhost:8000 and login with your Linux user and password:
JupyterHub login page
10. After login you have access to a fully fledged Jupyter server at classic mode (/tree) or the more recent JupyterLab (/lab):
Jupyter (Classic)
Jupyter (Lab)
The most interesting feature of this Jupyter setup is that it detects kernels in all conda environments, so you can access those kernels from here with no hassle. Just install the corresponding kernel in the desired environment ( conda install ipykernel, or conda install irkernel) and restart Jupyter server from JupyterHub control panel:
JupyterHub control panel
Remember to previously activate the environment where you want to install the kernel! ( conda activate <env_name>).
As you probably know I am a supporter of FOSS solutions, specially in the Data ecosystem. One of the few proprietary software I am going to recommend here, is the one we use as IDE: PyCharm. If you are serious about your code, you want to use an IDE like PyCharm:
Code completion and environment introspection.
Python environments, including native conda support.
Debugger.
Docker integration.
Git integration.
Scientific mode (pandas DataFrame and NumPy arrays inspection).
PyCharm Professional
Other popular choices does not have the stability and features of Pycharm:
Visual Studio Code: is more a Text Editor than an IDE. I know you can extend it using plugins, but is not as powerful as PyCharm. If you are a Web Dev with projects in multiple languages, Visual Studio Code may be a good choice for you. If you are a Web Developer and Python is your language of choice for back-end, go with Pycharm even if you are not in Data.
Jupyter: if you have doubts about when you should be using Jupyter or PyCharm and call yourself a Data <whatever>, please attend one of the bootcamps we teach asap.
Our advice for installing PyCharm is using Snap, so your installation will be automatically updated and isolated from the rest of the system. For community (free) version:
sudo snap install pycharm-community --classic
Scala
Scala is a language we use for Big Data projects with native Spark, although we are shifting to PySpark.
Our recommendation here is IntelliJ IDEA. It is an IDE for JVM based languages (Java, Kotlin, Groovy, Scala) from PyCharm developers (JetBrains). It best feature is its native support for Scala and its similarities to PyCharm. If you came from Eclipse, can adapt key bindings and shortcuts to replicate Eclipse ones.
Okay, you are not going to really do Big Data in your laptop. In case you are in a Big Data project, your company or client is going to provide you with a proper Hadoop cluster.
But there are situations where you may want to analyze or make a model with data that doesn’t fit easily in your laptop memory. In those cases, a local Spark installation is very helpful. Using my humble laptop, I have crushed datasets sized GB on disk, which on memory translates in much more.
This is our recommendation to get Spark up and running in your laptop:
Dask: simplifying things a lot, Dask is some kind of native Spark for Python. It is closer to pandas and NumPy APIs, but in our experience, it is not as robust as Spark by far. We use it from time to time.
Modin: replicates pandas API with support for multi-core and out-of-core computations. It is specially useful when you are working in a powerful analytics server with lots of cores (32, 64) and want to use pandas. As per-core performance is usually poor, Modin will allow you to speed your computation.
Database Tools
Sometimes you need a tool able to connect with a variety of different DB technologies, make queries and explore data. Our choice is DBeaver:
DBeaver Community
DBeaver is a tool that automatically downloads drivers for lots of different databases. It supports:
Database, schema, table and column name completion.
Advanced networking requirements to connect, like SSH tunnels and more.
You can install DBeaver like this:
sudo snap install dbeaver-ce
Honorable mention:
DataGrip: a database IDE by JetBrains we use sometimes, very similar to DBeaver, with less technologies supported, but very stable: sudo snap install datagrip --classic
Others
Other specific tools and apps that are important for us are:
And this is all. Those are a lot of tools and we probably forgot something. In case you miss some category here or need some advice, leave a comment and we will try to extend the post.
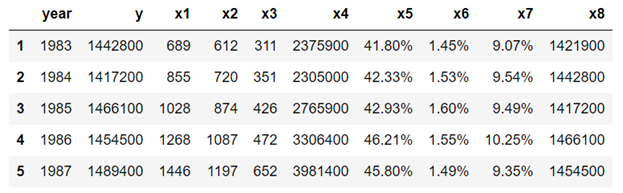
데이터는 추론 분석, 예측 분석 또는 규범 분석과 같은 데이터 과학의 모든 분석에서 핵심입니다. 모델의 예측력은 모델 구축에 사용 된 데이터의 품질에 따라 달라집니다. 데이터는 텍스트, 표, 이미지, 음성 또는 비디오와 같은 다양한 형태로 제공됩니다. 대부분의 경우 분석에 사용되는 데이터는 추가 분석에 적합한 형식으로 렌더링하기 위해 마이닝, 처리 및 변환되어야합니다.
대부분의 분석에 사용되는 가장 일반적인 유형의 데이터 세트는 쉼표로 구분 된 값 (csv) 테이블. 그러나 휴대용 문서 형식 (pdf)파일은 가장 많이 사용되는 파일 형식 중 하나입니다. 모든 데이터 과학자는pdf파일을 만들고 데이터를 "csv”그런 다음 분석 또는 모델 구축에 사용할 수 있습니다.
에서 데이터 복사pdf줄 단위 파일은 너무 지루하며 프로세스 중 인적 오류로 인해 종종 손상 될 수 있습니다. 따라서 데이터를 가져 오는 방법을 이해하는 것이 매우 중요합니다.pdf효율적이고 오류없는 방식으로.
이 기사에서는 데이터 테이블을 추출하는 데 초점을 맞출 것입니다.pdf파일. 텍스트 또는 이미지와 같은 다른 유형의 데이터를 추출하기 위해 유사한 분석을 수행 할 수 있습니다.pdf파일. 이 기사는 pdf 파일에서 숫자 데이터를 추출하는 데 중점을 둡니다. pdf 파일에서 이미지를 추출하기 위해 python에는 다음과 같은 패키지가 있습니다.광산 수레PDF에서 이미지, 텍스트 및 모양을 추출하는 데 사용할 수 있습니다.
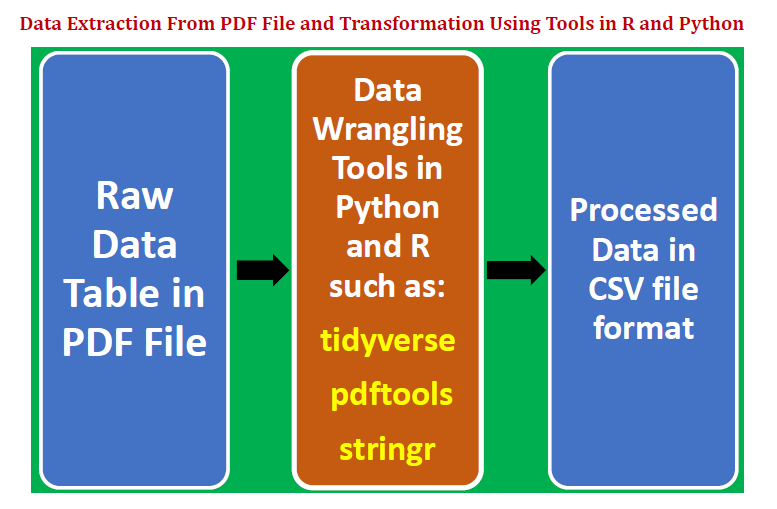
데이터 테이블을pdf파일을 추가 분석 및 모델 구축에 적합한 형식으로 변환합니다. 하나는 Python을 사용하고 다른 하나는 R을 사용하는 두 가지 예를 제시합니다.이 기사에서는 다음 사항을 고려합니다.
에서 데이터 테이블 추출pdf파일.
데이터 랭 글링 및 문자열 처리 기술을 사용하여 데이터를 정리, 변환 및 구조화합니다.
깨끗하고 깔끔한 데이터 테이블을csv파일.
R에서 데이터 랭 글링 및 문자열 처리 패키지를 소개합니다."순수한",“pdftools”, 및"스트링거".
예제 1 : Python을 사용하여 PDF 파일에서 테이블 추출
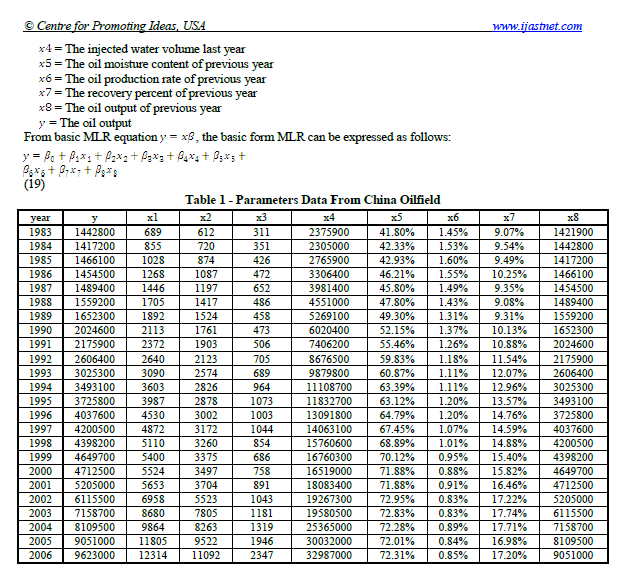
아래 표를 a에서 추출한다고 가정 해 보겠습니다.pdf파일.
— — — — — — — — — — — — — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — — — — — — — — — —
a) 테이블을 복사하여 Excel에 붙여넣고 파일을 table_1_raw.csv로 저장합니다.
Data is key for any analysis in data science, be it inferential analysis, predictive analysis, or prescriptive analysis. The predictive power of a model depends on the quality of the data that was used in building the model. Data comes in different forms such as text, table, image, voice or video. Most often, data that is used for analysis has to be mined, processed and transformed to render it to a form suitable for further analysis.
The most common type of dataset used in most of the analysis is clean data that is stored in a comma-separated value (csv) table. However because a portable document format (pdf) file is one of the most used file formats, every data scientist should understand how to extract data from a pdf file and transform the data into a format such as “csv” that can then be used for analysis or model building.
Copying data from a pdf file line by line is too tedious and can often lead to corruption due to human errors during the process. It is therefore extremely important to understand how to import data from a pdf in an efficient and error-free manner.
In this article, we shall focus on extracting a data table from a pdf file. A similar analysis can be made for extracting other types of data such as text or an image from a pdf file. This article focuses on extracting numerical data from a pdf file. For extraction of images from a pdf file, python has a package called minecart that can be used for extracting images, text, and shapes from pdfs.
We illustrate how a data table can be extracted from a pdf file and then transformed into a format appropriate for further analysis and model building. We shall present two examples, one using Python, and the other using R. This article will consider the following:
Extract a data table from a pdf file.
Clean, transform and structure the data using data wrangling and string processing techniques.
Store clean and tidy data table as a csv file.
Introduce data wrangling and string processing packages in R such as “tidyverse”, “pdftools”, and “stringr”.
Example 1: Extract a Table from PDF File Using Python
Let us suppose we would like to extract the table below from a pdf file.
— — — — — — — — — — — — — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — — — — — — — — — —
a) Copy and past table to Excel and save the file as table_1_raw.csv
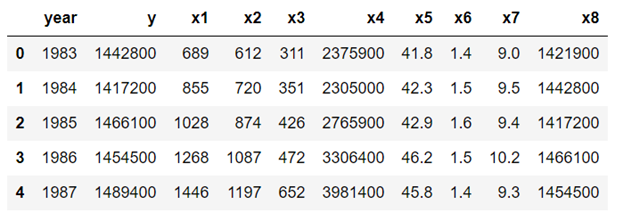
Data is stored in one-dimensional format and has to be reshaped, cleaned, and transformed.
We note that column values for columns x5, x6, and x7 have data types of string, so we need to convert these to numeric data as follows:
df4['x5']=[float(x) for x in df4['x5'].values]df4['x6']=[float(x) for x in df4['x6'].values]df4['x7']=[float(x) for x in df4['x7'].values]
f) View final form of the transformed data
df4.head(n=5)
g) Export final data to a csv file
df4.to_csv('table_1_final.csv',index=False)
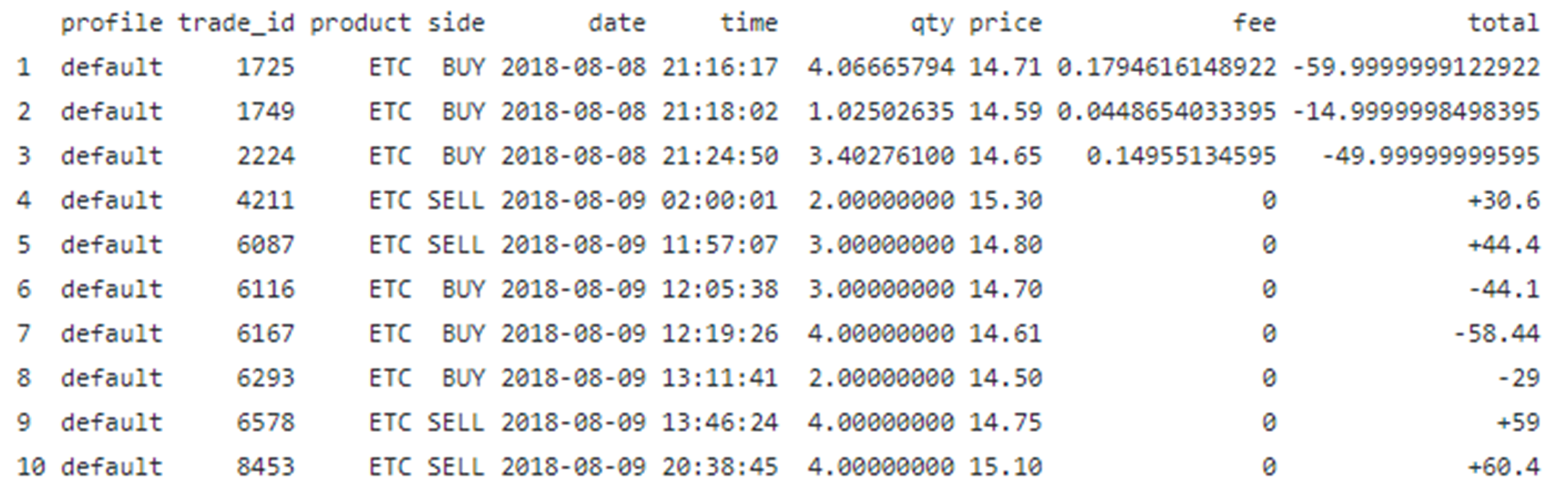
Example 2: Extract a Table From PDF File Using R
This example illustrates how to extract a table from a pdf file using data wrangling techniques in R. Let us suppose we have the following table from a pdf file name trade_report.pdf:
— — — — — — — — — — — — — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — — — — — — — — —
We would like to extract the table, wrangle the data, and convert it to a data frame table ready for further analysis. The final data table can then be easily exported and stored in a “csv” file. In particular, we would like to accomplish the following:
i) On the column Product, we would like to get rid of USD from the product ETC-USD.
ii) Split the Date column into two separate columns, namely, date and time.
In summary, we’ve shown how a data table can be extracted from a pdf file. Since a pdf file is a very common file type, every data scientist should be familiar with techniques for extracting and transforming data stored in a pdf file.
안반복자는__다음__방법. 상태가 있습니다. 상태는 반복 중에 실행을 기억하는 데 사용됩니다. 따라서 반복기는 현재 상태를 알고 있으며 이는 메모리를 효율적으로 만듭니다. 이것이 반복기가 메모리 효율적이고 빠른 애플리케이션에서 사용되는 이유입니다.
무한한 데이터 스트림 (파일 읽기 등)을 열고 다음 항목 (예 : 파일의 다음 줄)을 가져올 수 있습니다. 그런 다음 항목에 대한 작업을 수행하고 다음 항목으로 진행할 수 있습니다. 이것은 현재 항목 만 인식하면되므로 무한한 수의 요소를 반환하는 반복기를 가질 수 있음을 의미 할 수 있습니다.
반복에서 다음 값을 반환하고 다음 항목을 가리 키도록 상태를 업데이트하는 __next__ 메서드가 있습니다. 반복자는 우리가 실행할 때 항상 스트림에서 다음 항목을 가져옵니다.다음 (반복자)
반환 할 다음 항목이 없으면 반복기가 StopIteration 예외를 발생시킵니다.
결과적으로 반복자를 사용하여 린 애플리케이션을 구현할 수 있습니다.
목록, 문자열, 파일 행, 사전, 튜플 등과 같은 컬렉션은 모두 이터레이터입니다.
참고 : 반복 가능이란 무엇입니까?
안반복 가능반복자를 반환 할 수있는 개체입니다. 그것은__iter__반환하는 메서드반복자.
iterable은 반복 할 수 있고 iter ()를 호출 할 수있는 객체입니다. 그것은__getitem__0부터 시작하는 순차 인덱스를 가져 와서IndexError인덱스가 더 이상 유효하지 않을 때).
이 섹션에서는 반복 종료의 강력한 기능을 설명합니다. 이러한 기능은 다음과 같은 여러 가지 이유로 사용할 수 있습니다.
여러 반복 가능 항목이있을 수 있으며 단일 시퀀스에서 모든 반복 가능 항목의 요소에 대해 하나씩 작업을 수행하려고합니다.
또는 iterable의 모든 단일 요소에 대해 수행하려는 여러 함수가있을 때
또는 때로는 술어가 참인 한 iterable에서 요소를 삭제하고 다른 요소에 대해 조치를 수행하려고합니다.
체인
이 메서드를 사용하면 남은 요소가 없을 때까지 시퀀스의 모든 입력 이터 러블에서 요소를 반환하는 이터레이터를 만들 수 있습니다. 따라서 연속 시퀀스를 단일 시퀀스로 처리 할 수 있습니다.
chain = it.chain([1,2,3], ['a','b','c'], ['End']) for i in chain: print(i)
다음과 같이 인쇄됩니다.
1 2 삼 ㅏ 비 씨 종료
동안 드롭
이터 러블을 조건과 함께 전달할 수 있으며이 메서드는 조건이 요소에 대해 False를 반환 할 때까지 각 요소에 대한 조건 평가를 시작합니다. 조건이 요소에 대해 False로 평가 되 자마자이 함수는 이터 러블의 나머지 요소를 반환합니다.
예를 들어 작업 목록이 있고 요소를 반복하고 조건이 충족되지 않는 즉시 요소를 반환하려고한다고 가정합니다. 조건이 False로 평가되면 반복기의 나머지 요소를 반환 할 것으로 예상됩니다.
jobs = ['job1', 'job2', 'job3', 'job10', 'job4', 'job5'] dropwhile = it.dropwhile(lambda x : len(x)==4, jobs) for i in dropwhile: print(i)
이 메서드는 다음을 반환합니다.
직업 10 직업 4 직업 5
이 메소드는 job10 요소의 길이가 4자가 아니므로 job10 및 나머지 요소가 리턴되기 때문에 위의 세 항목을 리턴했습니다.
입력 조건과 이터 러블도 복잡한 객체가 될 수 있습니다.
잠시
이 메서드는 dropwhile () 메서드와 반대입니다. 기본적으로 첫 번째 조건이 False를 반환하고 다른 요소를 반환하지 않을 때까지 iterable의 모든 요소를 반환합니다.
예를 들어, 작업 목록이 있고 조건이 충족되지 않는 즉시 작업 반환을 중지하려고한다고 가정합니다.
jobs = ['job1', 'job2', 'job3', 'job10', 'job4', 'job5'] takewhile = it.takewhile(lambda x : len(x)==4, jobs) for i in takewhile: print(i)
이 메서드는 다음을 반환합니다.
직업 1 직업 2 job3
이는‘job10’의 길이가 4자가 아니기 때문입니다.
GroupBy
이 함수는 이터 러블의 연속 요소를 그룹화 한 후 이터레이터를 생성합니다. 이 함수는 키, 값 쌍의 반복자를 반환합니다. 여기서 키는 그룹 키이고 값은 키로 그룹화 된 연속 요소의 컬렉션입니다.
다음 코드 스 니펫을 고려하십시오.
iterable = 'FFFAARRHHHAADDMMAAALLIIKKK' my_groupby = it.groupby(iterable) for key, group in my_groupby: print('Key:', key) print('Group:', list(group))
그룹 속성은 반복 가능하므로 목록으로 구체화했습니다.
결과적으로 다음과 같이 인쇄됩니다.
키 : F 그룹 : [‘F’,‘F’,‘F’] 키 : A 그룹 : [‘A’,‘A’] 키 : R 그룹 : [‘R’,‘R’] 키 : H 그룹 : [‘H’,‘H’,‘H’] 키 : A 그룹 : [‘A’,‘A’] 키 : D 그룹 : [‘D’,‘D’] 키 : M 그룹 : [‘M’,‘M’] 키 : A 그룹 : [‘A’,‘A’,‘A’] 키 : L 그룹 : [‘L’,‘L’] 키 : I 그룹 : [‘I’,‘I’] 키 : K 그룹 : [‘K’,‘K’,‘K’]
복잡한 논리로 그룹화하려는 경우 키 함수를 두 번째 인수로 전달할 수도 있습니다.
티
이 메소드는 이터 러블을 분할하고 입력에서 새 이터 러블을 생성 할 수 있습니다. 출력은 주어진 항목 수에 대한 반복 가능 항목을 반환하는 반복기이기도합니다. 더 잘 이해하려면 아래 스 니펫을 검토하세요.
iterable = 'FM' tee = it.tee(iterable, 5) for i in tee: print(list(i))
An iterator is an object with a __next__ method. It has a state. The state is used to remember the execution during iteration. Therefore an iterator knows about its current state and this makes it memory efficient. This is the reason why an iterator is used in memory efficient and fast applications.
We can open an infinite stream of data (such as reading a file) and get the next item (such as the next line from the file). We can then perform an action on the item and proceed to the next item. This could mean that we can have an iterator that returns an infinite number of elements as we only need to be aware of the current item.
It has a __next__ method that returns the next value in the iteration and then updates the state to point to the next item. The iterator will always get us the next item from the stream when we execute next(iterator)
When there is no next item to be returned, the iterator raises a StopIteration exception.
As a result, a lean application can be implemented by using iterators
Note, collections such as a list, string, file lines, dictionary, tuples, etc. are all iterators.
Quick Note: What Is An Iterable?
An iterable is an object that can return an iterator. It has an __iter__ method that returns an iterator.
An iterable is an object which we can loop over and can call iter() on. It has a __getitem__ method that can take sequential indexes starting from zero (and raises an IndexError when the indexes are no longer valid).
Itertools is a Python module that is part of the Python 3 standard libraries. It lets us perform memory and computation efficient tasks on iterators. It is inspired by constructs from APL, Haskell, and SML.
Essentially, the module contains a number of fast and memory-efficient methods that can help us build applications succinctly and efficiently in pure Python.
Python’s Itertool is a module that provides various functions that work on iterators to produce iterators. It allows us to perform iterator algebra.
The most important point to take is that the itertools functions can return an iterator.
This brings us to the core of the article. Let’s understand how infinite iterators work.
1. Infinite Iterators
What if we want to construct an iterator that returns an infinite evenly spaced values? Or, what if we have to generate a cycle of elements from an iterator? Or, maybe we want to repeat the elements of an iterator?
The itertools library offers a set of functions which we can use to perform all of the required functionality.
The three functions listed in this section construct and return iterators which can be a stream of infinite items.
Count
As an instance, we can generate an infinite sequence of evenly spaced values:
start = 10 stop = 1 my_counter = it.count(start, stop) for i in my_counter: # this loop will run for ever print(i)
This will print never-ending items e.g.
10 11 12 13 14 15
Cycle
We can use the cycle method to generate an infinite cycle of elements from the input.
The input of the method needs to be an iterable such as a list or a string or a dictionary, etc.
my_cycle = it.cycle('Python') for i in my_cycle: print(i)
This will print never-ending items:
P y t h o n P y t h o n P
Repeat
To repeat an item (such as a string or a collection), we can use the repeat() function:
to_repeat = 'FM' how_many_times = 4 my_repeater = it.repeat(to_repeat, how_many_times) for i in my_repeater: print(i)#Prints FM FM FM FM
This will repeat the string ‘FM’ 4 times. If we do not provide the second parameter then it will repeat the string infinite times.
In this section, I will illustrate the powerful features of terminating iterations. These functions can be used for a number of reasons, such as:
We might have a number of iterables and we want to perform an action on the elements of all of the iterables one by one in a single sequence.
Or when we have a number of functions which we want to perform on every single element of an iterable
Or sometimes we want to drop elements from the iterable as long as the predicate is true and then perform an action on the other elements.
Chain
This method lets us create an iterator that returns elements from all of the input iterables in a sequence until there are no elements left. Hence, it can treat consecutive sequences as a single sequence.
chain = it.chain([1,2,3], ['a','b','c'], ['End']) for i in chain: print(i)
This will print:
1 2 3 a b c End
Drop While
We can pass an iterable along with a condition and this method will start evaluating the condition on each of the elements until the condition returns False for an element. As soon as the condition evaluates to False for an element, this function will then return the rest of the elements of the iterable.
As an example, assume that we have a list of jobs and we want to iterate over the elements and only return the elements as soon as a condition is not met. Once the condition evaluates to False, our expectation is to return the rest of the elements of the iterator.
jobs = ['job1', 'job2', 'job3', 'job10', 'job4', 'job5'] dropwhile = it.dropwhile(lambda x : len(x)==4, jobs) for i in dropwhile: print(i)
This method will return:
job10 job4 job5
The method returned the three items above because the length of the element job10 is not equal to 4 characters and therefore job10 and the rest of the elements are returned.
The input condition and the iterable can be complex objects too.
Take While
This method is the opposite of the dropwhile() method. Essentially, it returns all of the elements of an iterable until the first condition returns False and then it does not return any other element.
As an example, assume that we have a list of jobs and we want to stop returning the jobs as soon as a condition is not met.
jobs = ['job1', 'job2', 'job3', 'job10', 'job4', 'job5'] takewhile = it.takewhile(lambda x : len(x)==4, jobs) for i in takewhile: print(i)
This method will return:
job1 job2 job3
This is because the length of ‘job10’ is not equal to 4 characters.
GroupBy
This function constructs an iterator after grouping the consecutive elements of an iterable. The function returns an iterator of key, value pairs where the key is the group key and the value is the collection of the consecutive elements that have been grouped by the key.
Consider this snippet of code:
iterable = 'FFFAARRHHHAADDMMAAALLIIKKK' my_groupby = it.groupby(iterable) for key, group in my_groupby: print('Key:', key) print('Group:', list(group))
Note, the group property is an iterable and therefore I materialised it to a list.
As a result, this will print:
Key: F Group: [‘F’, ‘F’, ‘F’] Key: A Group: [‘A’, ‘A’] Key: R Group: [‘R’, ‘R’] Key: H Group: [‘H’, ‘H’, ‘H’] Key: A Group: [‘A’, ‘A’] Key: D Group: [‘D’, ‘D’] Key: M Group: [‘M’, ‘M’] Key: A Group: [‘A’, ‘A’, ‘A’] Key: L Group: [‘L’, ‘L’] Key: I Group: [‘I’, ‘I’] Key: K Group: [‘K’, ‘K’, ‘K’]
We can also pass in a key function as the second argument if we want to group by a complex logic.
Tee
This method can split an iterable and generate new iterables from the input. The output is also an iterator that returns the iterable for the given number of items. To understand it better, review the snippet below:
iterable = 'FM' tee = it.tee(iterable, 5) for i in tee: print(list(i))
This method returned the entire iterable FM, 5 times:
This article explained the uses of the Itertools library. In particular, it explained:
Infinite Iterators
Terminating Iterators
Combinatoric Iterators
The itertools methods can be used in combination to serve a powerful set of functionality in our applications. We can use the Itertools library to implement precise, memory efficient and stable applications in a shorter time.
I recommend potentially evaluating our applications to assess whether we can use the Itertools library.
For more detailed information, please visit the Python official documentation here
고객이 회사에 투자하도록 설득하려고한다고 상상해보십시오. 모든 직원의 기록과 성과를 막대 차트 나 원형 차트가 아닌 엑셀 시트 형식으로 표시합니다. 고객의 입장에서 자신을 상상해보십시오. 그러면 어떻게 반응할까요? (너무 많은 데이터가 그렇게 압도적이지 않을까요?). 여기에서 데이터 시각화가 등장합니다.
데이터 시각화는 원시 데이터를 시각적 플롯과 그래프로 변환하여 인간의 두뇌가 더 쉽게 해석 할 수 있도록하는 방법입니다. 주요 목표는 연구 및 데이터 분석을 더 빠르게 수행하고 추세, 패턴을 효과적으로 전달하는 것입니다.
티인간의 두뇌는 긴 일반 텍스트보다 시각적으로 매력적인 데이터를 더 잘 이해하도록 프로그래밍되어 있습니다.
이 기사에서는 데이터 세트를 가져 와서 요구 사항에 따라 데이터를 정리하고 데이터 시각화를 시도해 보겠습니다. 데이터 세트는 Kaggle에서 가져옵니다. 찾을 수 있습니다여기.
먼저 외부 소스에서 데이터를로드하고 정리하기 위해 Pandas 라이브러리를 사용합니다. 이전 기사에서 팬더에 대해 더 많이 공부할 수 있습니다.여기.
사용하려면 Pandas 라이브러리를 가져와야합니다. 그것을 사용하여 가져올 수 있습니다.
import pandas as pd
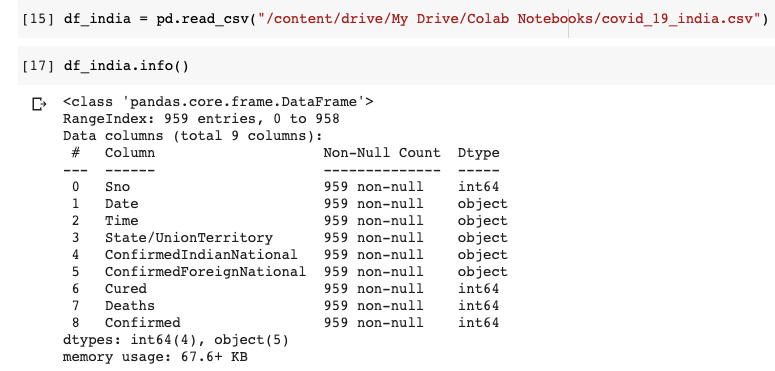
Kaggle에서 가져온 CSV 파일을로드하고 이에 대해 자세히 알아 보겠습니다.
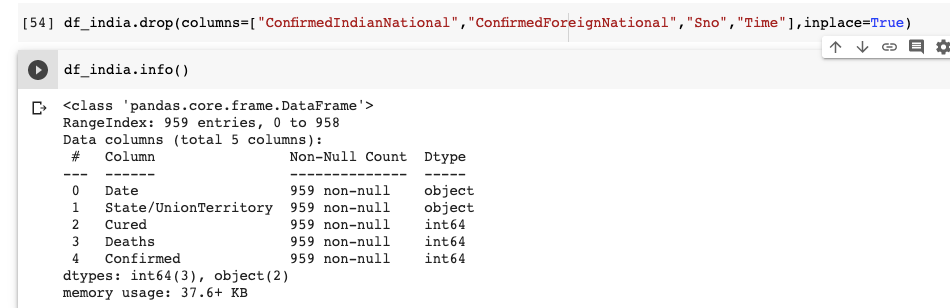
데이터 세트에 총 9 개의 열이 있음을 이해할 수 있습니다. 날짜 및 시간 열은 마지막으로 업데이트 된 날짜 및 시간을 나타냅니다. ConfirmedIndianNational 및 ConfirmedForeignNational 열은 사용하지 않습니다. 따라서이 두 개의 열을 삭제하겠습니다. 시간 열도 중요하지 않습니다. 우리도 그것을 떨어 뜨리 자. 데이터 프레임에 이미 인덱스가 있으므로 Serial No (Sno) 열도 필요하지 않습니다.
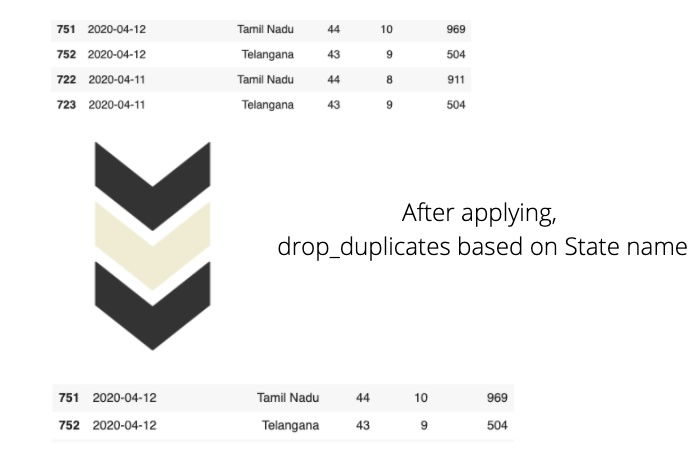
바로 데이터 프레임에 5 개의 열만 있음을 알 수 있습니다. 중복 데이터를 유지하면 불필요한 공간을 차지하고 잠재적으로 런타임이 저하 될 수 있으므로 중복 데이터를 삭제하는 것이 좋습니다.
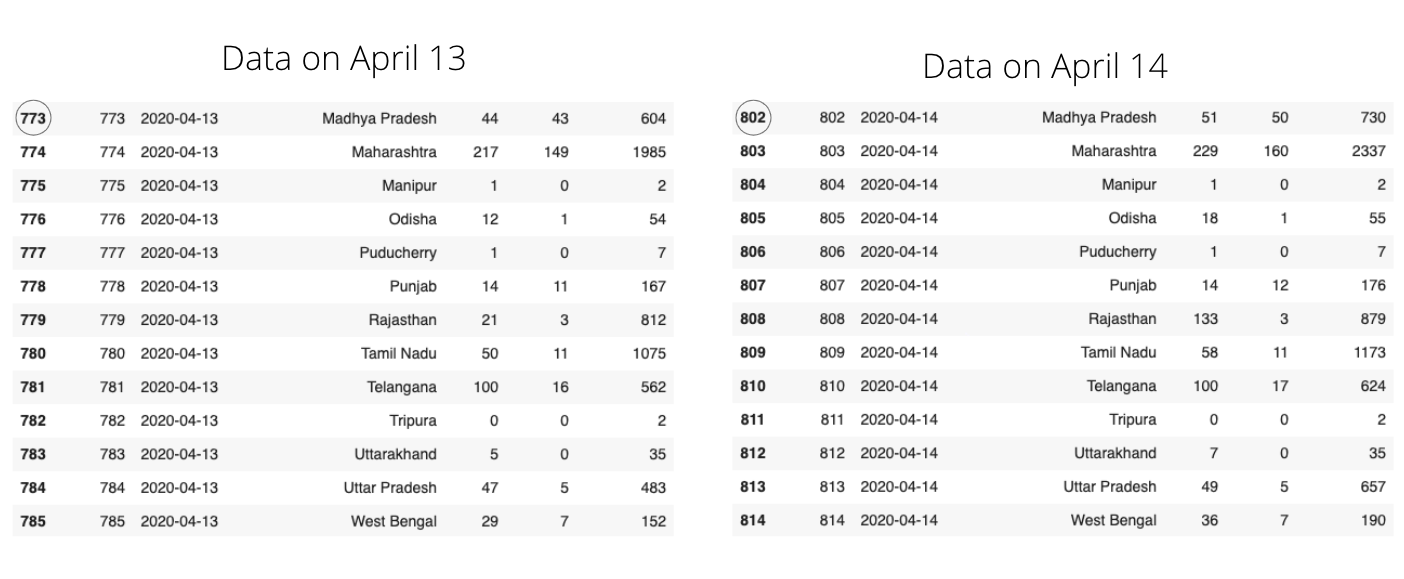
여기에서 Kaggle 데이터 세트는 매일 업데이트됩니다. 기존 데이터를 덮어 쓰는 대신 새 데이터가 추가됩니다. 예를 들어 4 월 13 일 데이터 세트에는 특정주의 누적 데이터를 나타내는 각 행이있는 925 개의 행이 있습니다. 그러나 4 월 14 일에 데이터 세트에 958 개의 행이 있었으며 이는 34 개의 새 행 (데이터 세트에 총 34 개의 상태가 있으므로)이 4 월 14 일에 추가되었음을 의미합니다.
위의 그림에서 동일한 State 이름을 볼 수 있지만 다른 열의 변경 사항을 관찰하십시오. 새로운 사례에 대한 데이터는 매일 데이터 세트에 추가됩니다. 이러한 형태의 데이터는 스프레드 추세를 파악하는 데 유용 할 수 있습니다. 처럼-
시간 경과에 따른 케이스 수의 증가입니다.
시계열 분석 수행
그러나 우리는 이전 데이터를 제외하고 최신 데이터 만 분석하는 데 관심이 있습니다. 따라서 필요하지 않은 행을 삭제하겠습니다.
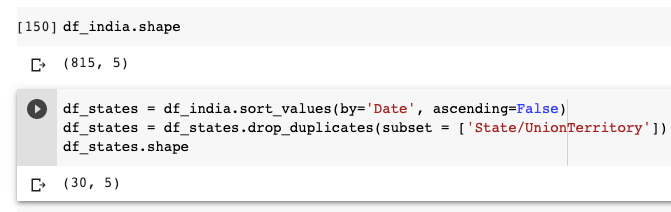
먼저 데이터를 날짜별로 내림차순으로 정렬하겠습니다. 상태 이름을 사용하여 데이터를 그룹화하여 중복 값을 제거하십시오.
df_states 데이터 프레임에 30 개의 행만 있다는 것을 알 수 있습니다. 이는 각 상태에 대한 최신 통계를 보여주는 고유 한 행이 있음을 의미합니다. 날짜 열을 사용하여 데이터 프레임을 정렬 할 때 데이터 프레임을 날짜별로 내림차순으로 정렬하고 (코드에서 ascending = False 확인) remove_duplicates는 값의 첫 번째 항목을 저장하고 모든 중복 항목을 제거합니다.
이제 데이터 시각화에 대해 이야기하겠습니다. Plotly를 사용하여 위의 데이터 프레임을 시각화합니다.
히스토그램, 막대 그래프, 산점도는 패턴과 추세를 효율적으로 설명하지만 지리 데이터를 다루기 때문에 등치 맵을 선호합니다.
등치 맵은 무엇입니까?
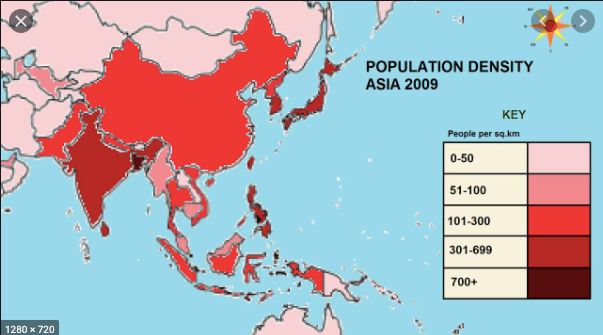
Plotly에 따르면 Choropleth 맵은 데이터 변수와 관련하여 색상이 지정되거나 음영 처리 된 분할 된 지리적 영역을 나타냅니다. 이러한지도는 지리적 영역에 대한 가치를 빠르고 쉽게 표시 할 수있는 방법을 제공하며 트렌드와 패턴도 공개합니다.
출처 — Youtube
위 이미지에서 영역은 인구 밀도에 따라 색상이 지정됩니다. 색이 어두울수록 특정 지역의 인구가 더 많다는 것을 의미합니다. 이제 데이터 세트와 관련하여 확인 된 사례를 기반으로 등치 맵을 생성 할 것입니다. 확진 자 수가 많을수록 특정 부위의 색이 어두워집니다.
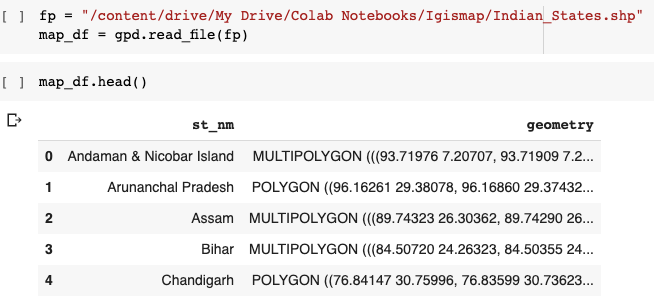
인도지도를 렌더링하려면 상태 좌표가있는 shapefile이 필요합니다. 인도 용 shapefile을 다운로드 할 수 있습니다.여기.
Wikipedia에 따르면shapefile형식은 지리 정보 시스템 (GIS)을위한 지리 공간 벡터 데이터 형식입니다.
shapefile로 작업하기 전에 GeoPandas를 설치해야합니다. GeoPandas는 지리 공간 데이터 작업을 쉽게 만들어주는 Python 패키지입니다.
pip install geopandas import geopandas as gpd
데이터 프레임에 상태 이름과 벡터 형식의 좌표가 있음을 알 수 있습니다. 이제이 shapefile을 필요한JSON체재.
import json#Read data to json.merged_json = json.loads(map_df.to_json())
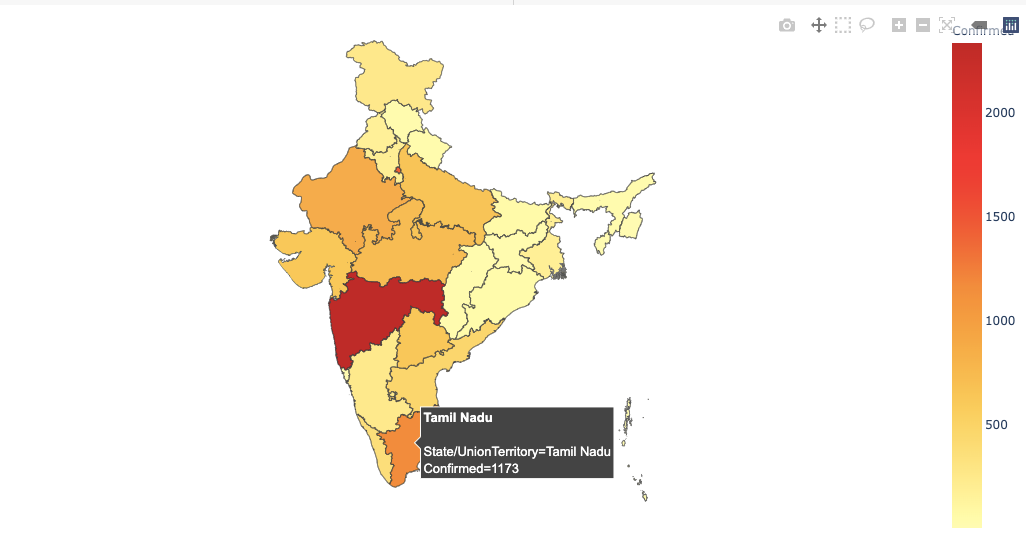
다음으로 Plotly Express를 사용하여 등치 맵을 만들 것입니다. 'px.choropleth함수. 등치 맵을 만들려면 기하학적 정보가 필요합니다.
이것은 GeoJSON 형식 (위에서 생성 한)으로 제공 될 수 있으며 각 기능에는 고유 한 식별 값이 있습니다 (예 : st_nm)
2. 미국 주 및 세계 국가를 포함하는 Plotly 내의 기존 도형
GeoJSON 데이터, 즉 (위에서 만든 merged_json)은Geojson인수 및 측정 메트릭이색깔인수px.choropleth.
모든 등치 맵에는위치주 / 국가를 매개 변수로 사용하는 인수입니다. 인도의 여러 주에 대한 등치 맵을 만들고 있으므로 State 열을 인수에 전달합니다.
첫 번째 매개 변수는 데이터 프레임 자체이며 확인 된 값에 따라 색상이 달라집니다. 우리는명백한인수fig.updtae_geos ()기본지도와 프레임을 숨기려면 False로 설정합니다. 우리는 또한 설정fitbounds = "위치"세계지도를 자동으로 확대하여 관심 영역을 표시합니다.
Let us imagine you are trying to convince a client to invest in your company. You exhibit all the employee’s records and their achievements in the form of an excel sheet rather than a bar chart or a pie chart. Imagine yourself in the client’s place. How would you react then? (Wouldn’t too much data be so overwhelming?). This is where data visualization comes into the picture.
Data visualization is the practice of translating raw data into visual plots and graphs to make it easier for the human brain to interpret. The primary objective is to make the research and data analysis quicker and also to communicate the trends, patterns effectively.
The human brain is programmed to understand visually appealing data better than lengthy plain texts.
In this article, Let us take a dataset, clean the data as per requirement, and try visualizing the data. The dataset is taken from Kaggle. You can find it here.
Firstly, to load the data from external sources and clean it, we will be using the Pandas library. You can study more about Pandas in my previous article here.
We need to import the Pandas library in-order to use it. We can import it by using it.
import pandas as pd
Let us load the CSV file taken from Kaggle and try to know more about it.
We can understand that the dataset has 9 columns in total. The Date and Time column indicate the last updated date and time. We are not going to use the ConfirmedIndianNational and ConfirmedForeignNational columns. Hence let us drop these 2 columns. The Time column is also immaterial. Let us drop it too. Since the Data Frame already has an index, the Serial No(Sno) column is also not required.
Right away, we can see that the data frame has only 5 columns. It is a good practice to drop redundant data because retaining it will take up unneeded space and potentially bog down runtime.
Here the Kaggle dataset is updated daily. New data is appended instead of overwriting the existing data. For instance, on April 13th dataset has 925 rows with each row representing the cumulative data of one particular state. But on April 14th, the dataset had 958 rows, which means 34 new rows(Since there are a total of 34 different states in the dataset) were appended on April 14th.
In the above picture, you can notice the same State names, but try to observe the changes in other columns. Data about new cases are appended to the dataset every day. This form of data can be useful to know the spread trends. Like-
The increment in the number of cases across time.
Performing time series analysis
But we are interested in analyzing only the latest data leaving aside the previous data. Hence let us drop those rows which are not required.
Firstly, let us sort the data by date in descending order. And get rid of the duplicate values by grouping data using state name.
You can see that the df_states data frame has only 30 rows, which means there is a unique row showing the latest stats for each state. When we sort the data frame using the date column, we will have data frame sorted according to dates in descending order(observe that ascending=False in code) and remove_duplicates stores the first occurrence of value and removes all its duplicate occurrences.
Let us now talk about data visualization. We will use Plotly to visualize the above data frame.
Histograms, Barplots, Scatter plots explain patterns and trends efficiently, but since we are dealing with geographical data, I prefer choropleth maps.
What are Choropleth maps?
According to Plotly, Choropleth maps depict divided geographical regions that are colored or shaded with respect to a data variable. These maps offer a quick and easy way to show value over a geographical area, unveiling trends and patterns too.
Source — Youtube
In the above image, areas are colored based on their population density. Darker the color implies higher the population in that particular area. Now with respect to our dataset, we are also going to create a choropleth map based on Confirmed cases. More the number of confirmed cases, darker the color of that particular region.
To render an Indian map, we need a shapefile with the state coordinates. We can download the shapefile for India here.
According to Wikipedia, The shapefile format is a geospatial vector data format for geographic information system (GIS).
Before working with shapefiles, we need to install GeoPandas, which is a python package that makes work with geospatial data easy.
pip install geopandas import geopandas as gpd
You can see that the data frame has a State name and its coordinates in vector form. Now we will convert this shapefile into the required JSON format.
import json#Read data to json.merged_json = json.loads(map_df.to_json())
Next, we are going to create Choropleth Maps using Plotly Express.’ px.choropleth function. Making choropleth maps requires geometric information.
This can either be a supplied in the GeoJSON format(which we created above) where each feature has a unique identifying value (like st_nm in our case)
2. Existing geometries within Plotly that include the US states and world countries
The GeoJSON data, i.e. (the merged_json we create above) is passed to the geojson argument and the metric of measurement is passed into the color argument of px.choropleth.
Every choropleth map has a locations argument that takes the State/Country as a parameter. Since we are creating a choropleth map for different states in India, we pass the State column to the argument.
The first parameter is the data frame itself, and the color is going to vary based on the Confirmed value. We set the visible argument in fig.updtae_geos() to False to hide the base map and frame. We also set fitbounds = "locations" to automatically zoom the world map to show our areas of interest.
We can hover across states to know more about them.
Data Visualization is an art that is highly underestimated. Hopefully, you have taken some concepts that will help when visualizing data in real-time. Do feel free to share your feedback and responses. Raise your hands if you’ve learned something new today.