New Features in Python 3.9
A look at the best features included in the latest iteration of Python
It’s that time again, a new version of Python is imminent. Now in beta (3.9.0b3), we will soon be seeing the full release of Python 3.9.
Some of the newest features are incredibly exciting, and it will be amazing to see them used after release. We’ll cover the following:
- Dictionary Union Operators
- Type Hinting
- Two New String Methods
- New Python Parser — this is very cool
Let’s take a first look at these new features and how we use them.
Dictionary Unions
One of my favorite new features with a sleek syntax. If we have two dictionaries a and b that we need to merge, we now use the union operators.
We have the merge operator |:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}c = a | b
print(c)
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
And the update operator |=, which updates the original dictionary:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}a |= b
print(a)
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
If our dictionaries share a common key, the key-value pair in the second dictionary will be used:
a = {1: 'a', 2: 'b', 3: 'c', 6: 'in both'}
b = {4: 'd', 5: 'e', 6: 'but different'}print(a | b)
[Out]: {1: 'a', 2: 'b', 3: 'c', 6: 'but different', 4: 'd', 5: 'e'}
Dictionary Update with Iterables
Another cool behavior of the |= operator is the ability to update the dictionary with new key-value pairs using an iterable object — like a list or generator:
a = {'a': 'one', 'b': 'two'}
b = ((i, i**2) for i in range(3))a |= b
print(a)
[Out]: {'a': 'one', 'b': 'two', 0: 0, 1: 1, 2: 4}
If we attempt the same with the standard union operator | we will get a TypeError as it will only allow unions between dict types.
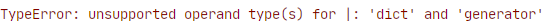
Type Hinting
Python is dynamically typed, meaning we don’t need to specify datatypes in our code.
This is okay, but sometimes it can be confusing, and suddenly Python’s flexibility becomes more of a nuisance than anything else.
Since 3.5, we could specify types, but it was pretty cumbersome. This update has truly changed that, let’s use an example:
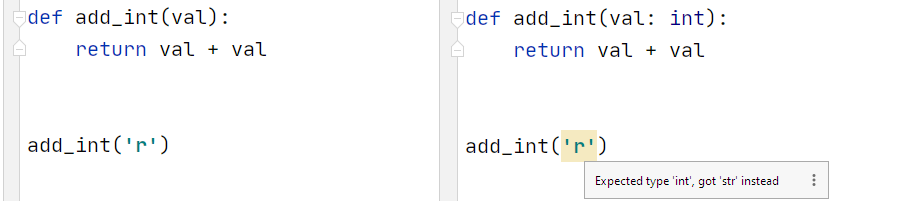
In our add_int function, we clearly want to add the same number to itself (for some mysterious undefined reason). But our editor doesn’t know that, and it is perfectly okay to add two strings together using + — so no warning is given.
What we can now do is specify the expected input type as int. Using this, our editor picks up on the problem immediately.
We can get pretty specific about the types included too, for example:
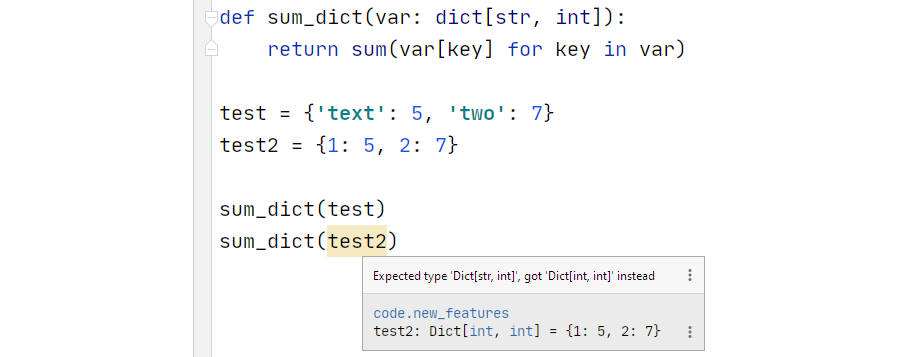
Type hinting can be used everywhere — and thanks to the new syntax, it now looks much cleaner:

String Methods
Not as glamourous as the other new features, but still worth a mention as it is particularly useful. Two new string methods for removing prefixes and suffixes have been added:
"Hello world".removeprefix("He")[Out]: "llo world"
Hello world".removesuffix("ld")[Out]: "Hello wor"
New Parser
This one is more of an out-of-sight change but has the potential of being one of the most significant changes for the future evolution of Python.
Python currently uses a predominantly LL(1)-based grammar, which in turn can be parsed by a LL(1) parser — which parses code top-down, left-to-right, with a lookahead of just one token.
Now, I have almost no idea of how this works — but I can give you a few of the current issues in Python due to the use of this method:
- Python contains non-LL(1) grammar; because of this, some parts of the current grammar use workarounds, creating unnecessary complexity.
- LL(1) creates limitations in the Python syntax (without possible workarounds). This issue highlights that the following code simply cannot be implemented using the current parser (raising a SyntaxError):
with (open("a_really_long_foo") as foo,
open("a_really_long_bar") as bar):
pass- LL(1) breaks with left-recursion in the parser. Meaning particular recursive syntax can cause an infinite loop in the parse tree. Guido van Rossum, the creator of Python, explains this here.
All of these factors (and many more that I simply cannot comprehend) have one major impact on Python; they limit the evolution of the language.
The new parser, based on PEG, will allow the Python developers significantly more flexibility — something we will begin to notice from Python 3.10 onwards.
That is everything we can look forward to with the upcoming Python 3.9. If you really can’t wait, the most recent beta release — 3.9.0b3 — is available here.
If you have any questions or suggestions, feel free to reach out via Twitter or in the comments below.
Thanks for reading!
If you enjoyed this article and want to learn more about some of the lesser-known features in Python, you may be interested in my previous article:
'Data Analytics(en)' 카테고리의 다른 글
| You are telling people that you are a Python beginner if you ask this question. (0) | 2020.10.07 |
|---|---|
| Scikit-Learn (Python): 6 Useful Tricks for Data Scientists (0) | 2020.10.06 |
| No More Basic Plots Please (0) | 2020.10.05 |
| The Definitive Data Scientist Environment Setup (0) | 2020.10.03 |
| Extracting Data from PDF File Using Python and R (0) | 2020.10.02 |