확실한 데이터 과학자 환경 설정

소개 및 동기
In this post I would like to describe in detail our setup and development environment (hardware & software) and how to get it, step by step.
저는 많은 회사에서 거의 변경 (주로 하드웨어 개선)없이이 설정을 5 년 이상 사용해 왔으며 수십 개의 데이터 프로젝트 개발에 도움을주었습니다. 사용하는 동안 하나의 기능을 놓치지 않았습니다. 이것은 표준 설정입니다.페드로과나를사용WhiteBox.
왜이 가이드인가? 시간이 지남에 따라 몇 가지 기본 기능을 갖춘 견고한 환경을 찾고있는 많은 학생과 동료 데이터 과학자를 발견했습니다.
- Python, R 및 해당 라이브러리와 같은 표준 데이터 과학 도구는 설치 및 유지 관리가 쉽습니다.
- 대부분의 라이브러리는 추가 구성없이 바로 작동합니다.
- 스몰 데이터에서 빅 데이터까지, 그리고 표준 머신 러닝 모델에서 딥 러닝 프로토 타이핑에 이르기까지 데이터 관련 작업의 전체 스펙트럼을 다룰 수 있습니다.
- 값 비싼 하드웨어와 소프트웨어를 구입하기 위해 은행 계좌를 깰 필요가 없습니다.
하드웨어
노트북에는 다음이 있어야합니다.
- 최소 16GB RAM. 이는 Dask 또는 Spark와 같은 도구를 사용하지 않고 메모리에서 쉽게 처리 할 수있는 데이터의 양을 제한하므로 가장 중요한 기능입니다. 많을수록 좋습니다. 여유가 있다면 32GB를 사용하십시오.
- 강력한 프로세서. 코어가 4 개인 Intel i5 또는 i7 이상. 명백한 이유로 데이터를 처리하는 동안 많은 시간을 절약 할 수 있습니다.
- 최소 4GB RAM의 NVIDIA GPU. 간단한 딥 러닝 모델을 프로토 타입하거나 미세 조정해야하는 경우에만 가능합니다. 해당 작업에 대해 거의 모든 CPU보다 훨씬 빠릅니다.랩톱에서 처음부터 심각한 딥 러닝 모델을 훈련 할 수는 없습니다..
- 좋은 냉각 시스템. 최소한 몇 시간 동안 워크로드를 실행합니다. 노트북이 녹지 않고 처리 할 수 있는지 확인하십시오.
- 256GB 이상의 SSD이면 충분합니다.
- 더 큰 SSD, 더 많은 RAM을 추가하거나 배터리를 쉽게 교체하는 등의 기능을 업그레이드 할 수 있습니다.
개인적으로 추천하는 것은 중고 Thinkpad 워크 스테이션 노트북입니다. 나는 초침이있다P50위에 나열된 모든 기능을 충족하는 500 유로에 구입했습니다.
Thinkpad는 우리가 수년 동안 사용해 왔지만 결코 실패한 적이없는 뛰어난 전문가 용 노트북입니다. 핸디캡은 가격이지만 많은 대기업이 임대 계약을 맺고 2 년마다 랩톱을 폐기하므로 사용 조건이 매우 좋은 중고 씽크 패드를 많이 찾을 수 있습니다. 이러한 노트북 중 상당수는 중고 시장에서 끝납니다. 다음에서 검색을 시작할 수 있습니다.
이러한 중고 시장의 대부분은 보증 및 송장을 제공 할 수 있습니다 (귀하가 회사 인 경우). 이 게시물을 읽고 중대형 조직에 속한 경우 가장 좋은 방법은 제조업체와 직접 임대 계약에 도달하는 것입니다.

Apple MacBook을 피하십시오:
여러 가지 이유로 OSX를 정말 좋아하지 않는 한 Apple 노트북을 피해야합니다. 그들은디자인 분야의 전문가와 음악 제작자를위한, 사진 작가, 동영상 및 사진 편집자, UX / UI, 웹 개발자와 같이 무거운 작업을 실행할 필요가없는 개발자도 마찬가지입니다. 2011 년부터 2016 년까지 제 주 노트북은 맥북 이었기 때문에 그 한계를 잘 알고 있습니다. 하나를 사지 않는 주된 이유는 다음과 같습니다.
- 동일한 하드웨어에 대해 훨씬 더 많은 비용을 지불하게됩니다.
- 끔찍한 공급 업체 종속으로 인해 다른 대안으로 변경하는 데 막대한 비용이 듭니다.
- NVIDIA GPU를 사용할 수 없으므로 랩톱에서 딥 러닝 프로토 타이핑은 잊어 버리십시오.
- 마더 보드에 납땜되어 있으므로 하드웨어를 업그레이드 할 수 없습니다. 더 많은 RAM이 필요한 경우 새 노트북을 구입해야합니다.
울트라 북 (일반)을 피하십시오:
대부분의 울트라 북은 가벼운 워크로드, 웹 브라우징, 사무 생산성 소프트웨어 등을 위해 설계되었습니다. 대부분은 위에 나열된 냉각 시스템 요구 사항을 충족하지 못하며 수명이 짧습니다. 또한 업그레이드 할 수 없습니다.
운영 체제
데이터 과학 용으로 사용되는 운영 체제는 Ubuntu의 최신 LTS (장기 지원)입니다. 이 글을 쓰는 시점에서Ubuntu 20.04 LTS최신입니다.

Ubuntu는 데이터 과학자로서 다른 운영 체제 및 기타 Linux 배포판에 비해 몇 가지 이점을 제공합니다.
- 가장 성공적인 데이터 과학 도구는 오픈 소스이며 무료 오픈 소스 인 Ubuntu에서 설치 및 사용하기 쉽습니다. 이러한 도구의 대부분의 개발자는 아마도 Linux를 사용하고있을 것입니다. TensorFlow, PyTorch 등과 같은 GPU를 지원하는 딥 러닝 프레임 워크의 경우 특히 그렇습니다.
- 데이터 작업을 할 때 보안은 설정의 핵심이되어야합니다. Linux는 기본적으로 Windows 또는 OS X보다 더 안전하며 소수의 사람들이 사용하기 때문에 대부분의 악성 소프트웨어는 Linux에서 실행되도록 설계되지 않았습니다.
- 데스크탑과 서버 모두에서 가장 많이 사용되는 Linux 배포판이며 훌륭하고 지원적인 커뮤니티입니다. 제대로 작동하지 않는 문제를 발견하면 도움을 받거나 문제 해결 방법에 대한 정보를 찾는 것이 더 쉽습니다.
- 대부분의 서버는 Linux 기반입니다., 해당 서버에 코드를 배포하고 싶을 것입니다. 프로덕션에 배포 할 환경에 가까울수록 좋습니다. 이것이 Linux를 플랫폼으로 사용하는 주된 이유 중 하나입니다.
- 그것은 위대한패키지 관리자거의 모든 것을 설치하는 데 사용할 수 있습니다.
Ubuntu 설치시주의 사항 :
- 운이 좋으면 전용 GPU를 사용할 수있는 경우 그래픽 전용 드라이버를 설치하지 마십시오 (설치하는 동안 확인란이 선택되지 않음). 기본 드라이버가 버그가 있고 특정 GPU (제 경우와 같이)에서 외부 모니터가 제대로 작동하지 않을 수 있으므로 나중에 설치할 수 있습니다.
- 설치 USB를 올바르게 만드십시오. Linux에 액세스 할 수 있으면 사용할 수 있습니다.시동 디스크 작성기, Windows 또는 OSX의 경우balenaEtcher확실한 선택입니다.
NVIDIA 드라이버
NVIDIA Linux 지원은 수년 동안 커뮤니티의 불만 중 하나였습니다. 유명한 것을 기억하십시오.
NVIDIA: 젠장!
운 좋게도 상황이 바뀌었고 지금은 여전히 엉덩이에 통증이 있지만 모든 것이 더 쉽습니다.
다음은 NVIDIA 드라이버를 설치해야하는 방법입니다.
1. 추가독점 GPU 드라이버 PPA시스템에 :
sudo add-apt-repository ppa:graphics-drivers/ppa2. 사용 가능한 최신 드라이버를 설치합니다 (이 게시물 작성 당시에는 440,탭사용 가능한 옵션을 확인하는 키) :
sudo apt install nvidia-driver-440설치가 완료 될 때까지 기다렸다가 PC를 재부팅하십시오.
이제 NVIDIA X 서버 설정에 액세스 할 수 있습니다.
이를 사용하여 절전 모드 (딥 러닝 작업을 수행하지 않을 경우 유용함)와 성능 모드 (GPU를 사용할 수 있지만 배터리를 소모 함)간에 전환 할 수 있습니다. 온 디맨드 모드는 여전히 제대로 작동하지 않으므로 피하십시오.
또한 실행할 수 있어야합니다.nvidia-smiGPU 워크로드 (사용량, 온도, 메모리)에 대한 정보를 표시하는 애플리케이션입니다. GPU에서 딥 러닝 모델을 훈련하는 동안 많이 사용할 것입니다.

단말기
기본 그놈 터미널은 괜찮지 만터미네이터, 터미널 창을 수직으로 분할 할 수있는 강력한 터미널 에뮬레이터CTR+시프트+이자형수평으로CTR+시프트+영형, 동시에 여러 터미널에 명령을 브로드 캐스트합니다. 다양한 서버 또는 클러스터를 설정하는 데 유용합니다.
다음과 같이 Terminator를 설치합니다.
sudo apt install terminatorVirtualBox
VirtualBox는 다음을 실행할 수있는 소프트웨어입니다.사실상현재 운영 체제 세션 내의 다른 컴퓨터. 다른 운영 체제를 실행할 수도 있습니다 (Linux 내부의 Windows 또는 그 반대).
다음과 같은 BI 및 Dashboarding 도구와 같이 Linux에서 사용할 수없는 특정 소프트웨어가 필요한 경우에 유용합니다.
VirtualBox는 VM (Virtual Machine)을 만들고 필요한 것을 테스트하고 삭제할 수 있기 때문에 시스템을 손상시키지 않고 새로운 라이브러리와 소프트웨어를 테스트하는데도 유용합니다.
VirtualBox를 설치하려면 터미널을 열고 다음을 작성하십시오.
sudo apt install virtualbox사용법은 매우 간단하지만 마스터하기는 어렵습니다. VirtualBox에 대한 광범위한 자습서를 보려면이.
Python, R 등 (Miniconda 포함)
Python은 이미 Ubuntu에 포함되어 있습니다. 하지만 너시스템 Python을 사용하거나 시스템 전체에 분석 라이브러리를 설치해서는 안됩니다.. 그렇게하면 시스템 파이썬이 깨질 수 있으며, 고치는 것은 어렵습니다.
저는 고립 된 가상 환경을 만드는 것을 선호합니다. 문제가 발생할 경우를 대비하여 삭제하고 다시 만들 수 있습니다. 이를 위해 사용할 수있는 가장 좋은 도구는콘다:
모든 언어 (Python, R, Ruby, Lua, Scala, Java, JavaScript, C / C ++, FORTRAN 등)에 대한 패키지, 종속성 및 환경 관리.
많은 사람들이 conda를 사용하지만 그것이 어떻게 작동하고 무엇을하는지 정말로 이해하는 사람은 거의 없습니다. 좌절감으로 이어질 수 있습니다.
conda는 두 가지 유형으로 제공됩니다.
- Anaconda : conda 패키지 관리자 포함과많은 라이브러리 (500Mb)가 설치되었습니다. 이러한 라이브러리를 모두 사용하지는 않을 것이며 며칠 안에 구식이 될 것입니다. 나는이 풍미를 가지고가는 것을 추천하지 않는다.
- Miniconda : conda 패키지 관리자 만 포함합니다. conda 또는 pip를 통해 모든 기존 라이브러리에 계속 액세스 할 수 있지만 해당 라이브러리는 필요할 때 다운로드 및 설치됩니다. 이 옵션을 사용하면 시간과 메모리를 절약 할 수 있습니다.
Miniconda 설치 스크립트 다운로드여기그것을 실행하십시오 :
bash Miniconda3-latest-Linux-x86_64.shconda를 초기화했는지 확인하십시오.예설치 스크립트가 물어볼 때!) 해당 줄이.bashrc파일:
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/home/david/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/home/david/miniconda3/etc/profile.d/conda.sh" ]; then
. "/home/david/miniconda3/etc/profile.d/conda.sh"
else
export PATH="/home/david/miniconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<콘다 앱이 추가됩니다.통로언제든지 액세스 할 수 있습니다. conda가 제대로 설치되었는지 확인하려면 다음을 입력하십시오.콘다터미널에서 :
conda 가상 환경에서 원하는 Python 버전은 물론 R, Java, Julia, Scala 등을 설치할 수 있습니다.
conda 및 pip 패키지 관리자 모두에서 라이브러리를 설치할 수도 있으며 동일한 가상 환경에서 완벽하게 호환되므로 둘 중 하나를 선택할 필요가 없습니다.
conda에 대해 한 가지 더 :
conda는 코드 배포를위한 고유 한 기능을 제공합니다. 라는 도서관입니다콘다 팩그리고 그것은절대로 필요한 것우리를 위해. 여러 번 액세스 할 수없는 인터넷 격리 클러스터에 라이브러리를 배포하는 데 도움이되었습니다.씨, 아니python3필요한 것을 설치하는 간단한 방법이 없습니다.
이 라이브러리를 사용하면.tar.gz원하는 곳에서 압축을 풀 수 있습니다. 그런 다음 환경을 활성화하고 평소처럼 사용할 수 있습니다.
설치 및 사용하기콘다 팩이것을 방문하십시오링크:
conda install -c conda-forge conda-pack이는 주어진 환경에서 작업 할 수있는 올바른 권한을 부여하지 않고 프로젝트 요구 사항에 맞게 구성 할 시간이없는 게으른 IT 직원에 대한 궁극적 인 무기입니다. ssh가 서버에 액세스 할 수 있습니까? 그런 다음 원하고 필요한 환경을 갖게됩니다.
다음은 공식 문서의 데모입니다.
Jupyter
Jupyter는 대화 형 프로그래밍 환경이 필요한 개발을 위해 데이터 과학자에게 필수입니다.
제가 몇 년 동안 배운 비결은 로컬 JupyterHub 서버를 만들고 시스템 서비스로 구성하여 매번 서버를 시작할 필요가 없도록하는 것입니다 (노트북이 시작 되 자마자 서버가 항상 가동되고 대기합니다). 또한 모든 환경에서 Python / R 커널을 감지하고 Jupyter에서 자동으로 사용할 수 있도록하는 라이브러리를 설치합니다.
이것을하기 위해:
1. 먼저 conda 가상 환경을 만듭니다 (일반적으로jupyter_env) :
conda create -n jupyter_env2. 환경 활성화 :
conda activate jupyter_env3. Python을 설치합니다.
conda install python=3.74. 필요한 라이브러리를 설치합니다.
conda install -c conda-forge jupyterhub jupyterlab nodejs nb_conda_kernels5. 서비스 파일 생성sudo nano /etc/systemd/system/jupyterhub.service내용과 함께 (적응 경로, 변경<your_user>사용자 이름으로) :
[Unit]
Description=JupyterHub
After=network.target[Service]
User=root
Environment="PATH=/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/home/<your_user>/miniconda3/envs/jupyter_env/bin:/home/<your_user>/miniconda3/bin"
ExecStart=/home/<your_user>/miniconda3/envs/jupyter_env/bin/jupyterhub[Install]
WantedBy=multi-user.target
6. 서비스 데몬을 다시로드합니다.
sudo systemctl daemon-reload7. 시작주피터 허브서비스:
sudo systemctl start jupyterhub8. 활성화주피터 허브서비스이므로 부팅시 자동으로 시작됩니다.
sudo systemctl enable jupyterhub9. 이제 다음으로 이동할 수 있습니다.localhost : 8000및 로그인Linux 사용자 및 비밀번호로:
10. 로그인 후 클래식 모드에서 본격적인 Jupyter 서버에 액세스 할 수 있습니다 (/나무) 또는 최신 JupyterLab (/랩) :
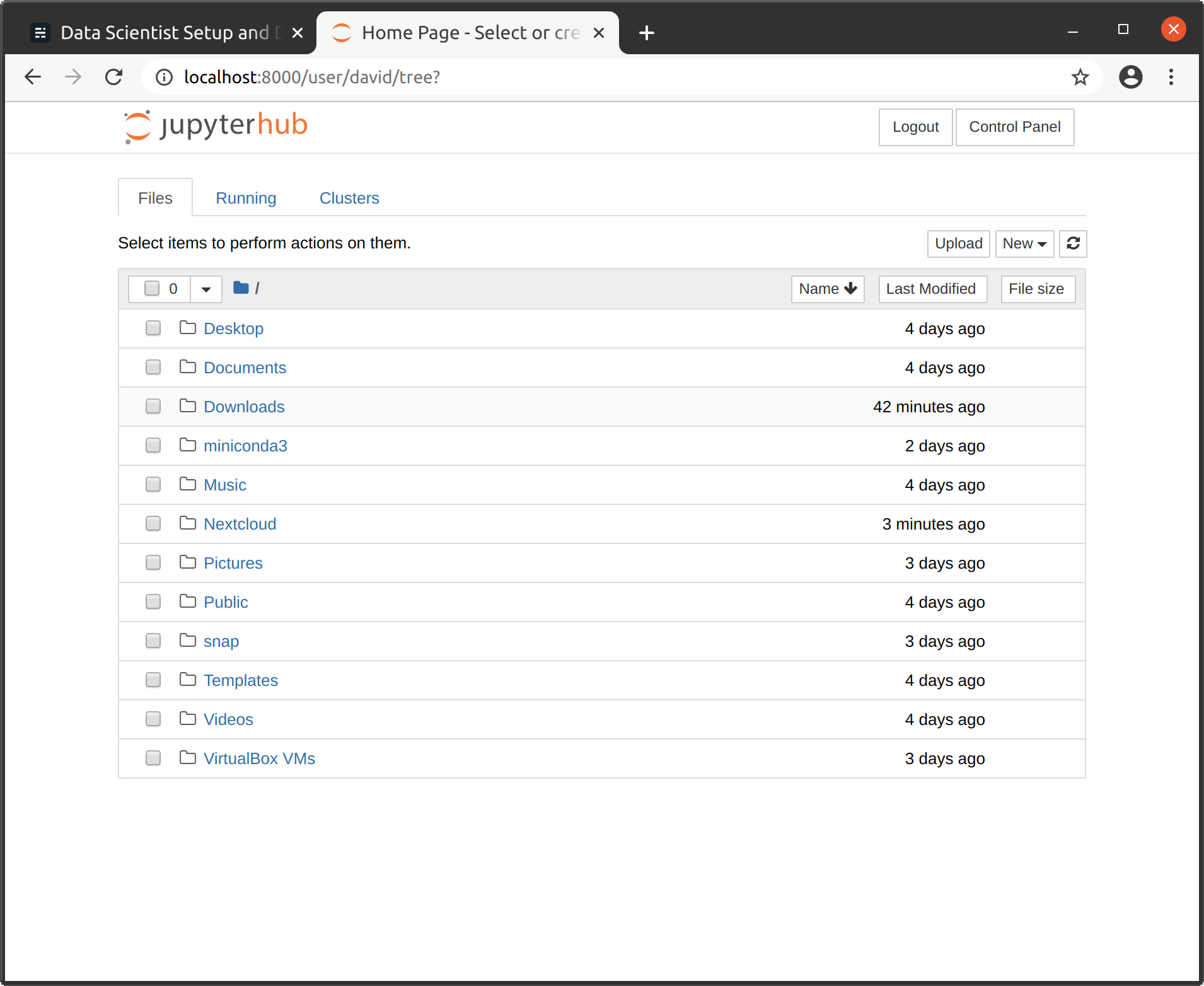
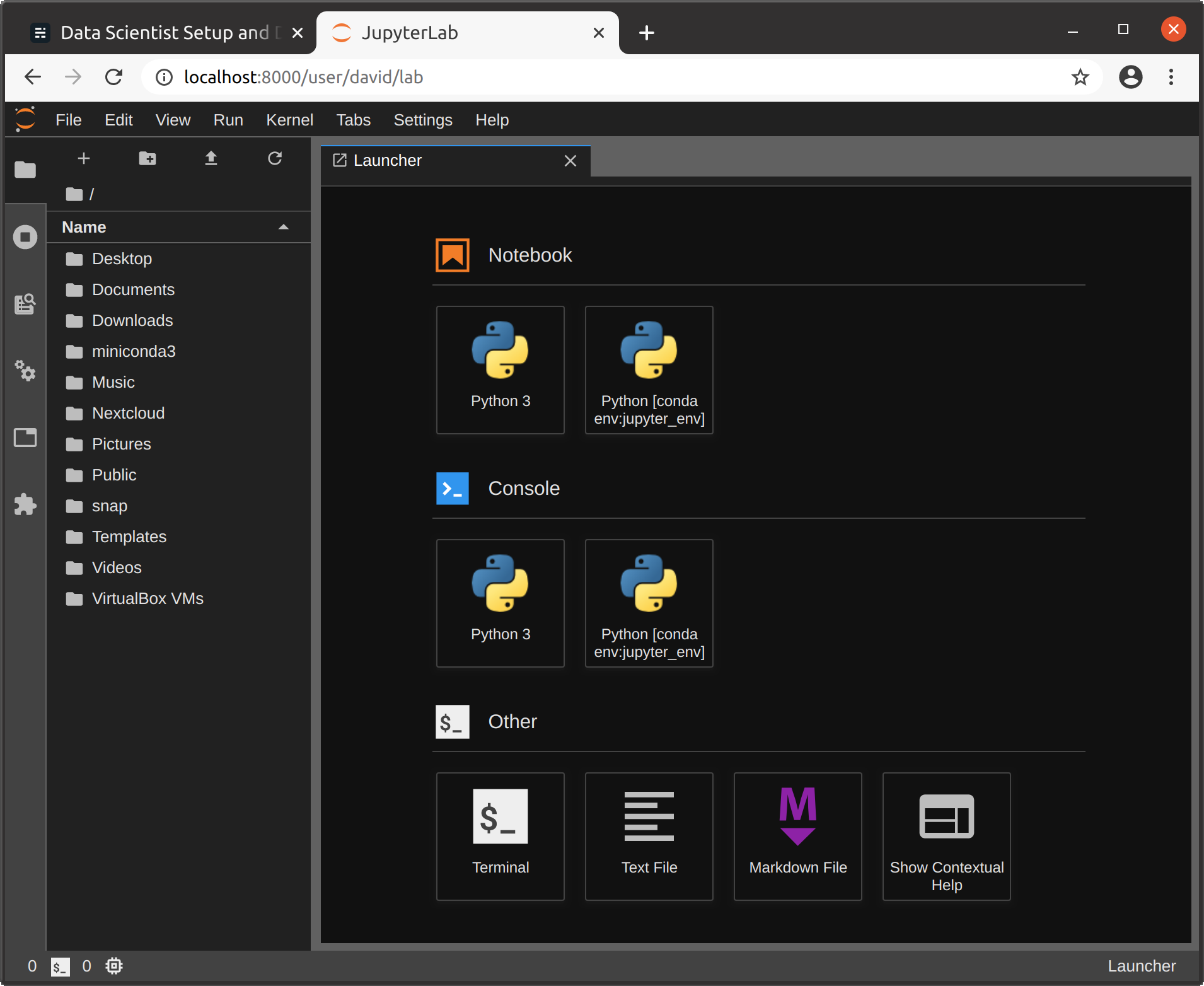
이 Jupyter 설정의 가장 흥미로운 기능은 모든 conda 환경에서 커널을 감지하므로 여기에서 번거 로움없이 해당 커널에 액세스 할 수 있다는 것입니다. 해당 커널을 설치하십시오.원하는 환경에서(conda 설치 ipykernel, 또는conda 설치 irkernel) 및 JupyterHub 제어판에서 Jupyter 서버를 다시 시작합니다.
커널을 설치하려는 환경을 이전에 활성화해야합니다! (conda activate <env_name>).
십오 일
파이썬
파이썬은 우리의 기본 언어입니다.WhiteBox.
아시다시피 저는FOSS특히 데이터 생태계의 솔루션입니다. 소수 중 하나소유권여기서 추천 할 소프트웨어는 우리가 사용하는 소프트웨어입니다.IDE:PyCharm. 코드에 대해 진지하게 생각한다면 PyCharm과 같은 IDE를 사용하고 싶을 것입니다.
- 코드 완성 및 환경 검사.
- 네이티브 conda 지원을 포함한 Python 환경.
- 디버거.
- Docker 통합.
- Git 통합.
- 과학 모드 (pandas DataFrame 및 NumPy 배열 검사).
다른 인기있는 선택에는 Pycharm의 안정성과 기능이 없습니다.
- Visual Studio Code : IDE보다 텍스트 편집기에 가깝습니다. 플러그인을 사용하여 확장 할 수 있다는 것을 알고 있지만 PyCharm만큼 강력하지는 않습니다. 여러 언어로 된 프로젝트가있는 웹 개발자라면 Visual Studio Code가 좋은 선택 일 수 있습니다. 웹 개발자이고 Python이 백엔드 용으로 선택한 언어라면 데이터에 있지 않더라도 Pycharm을 사용하십시오.
- Jupyter: if you have doubts about when you should be using Jupyter or PyCharm and call yourself a Data <whatever>, please attend 부트 캠프 중 하나우리는 최대한 빨리 가르칩니다.
PyCharm 설치에 대한 우리의 조언은스냅이므로 설치가 자동으로 업데이트되고 나머지 시스템과 격리됩니다. 커뮤니티 (무료) 버전 :
sudo snap install pycharm-community --classic스칼라
Scala는 기본 Spark로 빅 데이터 프로젝트에 사용하는 언어이지만 PySpark로 전환하고 있습니다.
여기에서 우리의 추천은IntelliJ IDEA. PyCharm 개발자 (JetBrains)의 JVM 기반 언어 (Java, Kotlin, Groovy, Scala) 용 IDE입니다. 가장 좋은 기능은 Scala에 대한 기본 지원과 PyCharm과의 유사점입니다. Eclipse에서 온 경우 키 바인딩 및 단축키를 수정하여 Eclipse를 복제 할 수 있습니다.
커뮤니티 (무료) 버전을 설치하려면 :
sudo snap install intellij-idea-community --classic빅 데이터
좋아, 당신은 당신의 노트북에서 실제로 빅 데이터를 수행하지 않을 것입니다. 빅 데이터 프로젝트에 참여하는 경우 회사 또는 고객이 적절한 Hadoop 클러스터를 제공 할 것입니다.
그러나 랩톱 메모리에 쉽게 맞지 않는 데이터로 모델을 분석하거나 만들려는 상황이 있습니다. 이러한 경우 로컬 Spark 설치가 매우 유용합니다. 저의 겸손한 노트북을 사용하여 디스크에 GB 크기의 데이터 세트를 분쇄했습니다.
다음은 노트북에서 Spark를 시작하고 실행하기위한 권장 사항입니다.
1. conda 환경을 만들거나 활성화합니다.
2. PySpark 및 OpenJDK를 설치합니다.
conda install pyspark openjdk3. 로컬 스파크 사용 :
from pyspark.sql import SparkSession
spark = SparkSession.builder. \
appName('your_app_name'). \
config('spark.sql.session.timeZone', 'UTC'). \
config('spark.driver.memory', '16G'). \
config('spark.driver.maxResultSize', '2G'). \
getOrCreate()여기에 훌륭한 언급이 있습니다 :
- Dask: 일을 많이 단순화하는 Dask는 일종의 Python 용 기본 Spark입니다. pandas 및 NumPy API에 더 가깝지만 경험상 Spark만큼 강력하지는 않습니다. 우리는 때때로 그것을 사용합니다.
- 모딘: 멀티 코어 및 아웃 오브 코어 계산을 지원하는 Pandas API를 복제합니다. 많은 코어 (32, 64)가있는 강력한 분석 서버에서 작업하고 pandas를 사용하려는 경우 특히 유용합니다. 일반적으로 코어 당 성능이 좋지 않기 때문에 Modin을 사용하면 계산 속도를 높일 수 있습니다.
데이터베이스 도구
때로는 다양한 DB 기술과 연결하고 쿼리를 만들고 데이터를 탐색 할 수있는 도구가 필요합니다. 우리의 선택은DBeaver:

DBeaver는 다양한 데이터베이스의 드라이버를 자동으로 다운로드하는 도구입니다. 다음을 지원합니다.
- 데이터베이스, 스키마, 테이블 및 열 이름 완성.
- 연결을위한 고급 네트워킹 요구 사항 (예 : SSH 터널 등)
다음과 같이 DBeaver를 설치할 수 있습니다.
sudo snap install dbeaver-ce가작 :
- DataGrip: JetBrains의 데이터베이스 IDE는 때때로 DBeaver와 매우 유사하며 지원되는 기술은 적지 만 매우 안정적입니다.
sudo snap install datagrip --classic
기타
우리에게 중요한 기타 특정 도구 및 앱은 다음과 같습니다.
- 스포티 파이:
sudo 스냅 설치 spotify. - 느슨하게:
sudo 스냅 설치 슬랙-클래식. - 전보 데스크탑 :
sudo snap install telegram-desktop. - Nextcloud :
sudo apt install nextcloud-desktop nautilus-nextcloud. - Thunderbird Mail : 기본적으로 설치됩니다.
- Zoom : 다음에서 수동으로 다운로드여기.
- Google 크롬 : 다음에서 수동으로 다운로드여기.
그리고 이것이 전부입니다. 그것들은 많은 도구이고 우리는 아마도 뭔가를 잊었을 것입니다. 여기에 일부 카테고리를 놓치거나 조언이 필요한 경우 의견을 남겨 주시면 게시물을 연장하겠습니다.
원래 게시 된 게시물 :https://davidadrian.cc
'Data Analytics(ko)' 카테고리의 다른 글
| New Features in Python 3.9 -번역 (0) | 2020.10.05 |
|---|---|
| No More Basic Plots Please -번역 (0) | 2020.10.05 |
| Extracting Data from PDF File Using Python and R -번역 (0) | 2020.10.02 |
| Advanced Python: Itertools Library — The Gem Of Python Language -번역 (0) | 2020.10.01 |
| Data Visualisation using Pandas and Plotly -번역 (0) | 2020.09.30 |