데이터 과학,데이터 시각화
고객이 회사에 투자하도록 설득하려고한다고 상상해보십시오. 모든 직원의 기록과 성과를 막대 차트 나 원형 차트가 아닌 엑셀 시트 형식으로 표시합니다. 고객의 입장에서 자신을 상상해보십시오. 그러면 어떻게 반응할까요? (너무 많은 데이터가 그렇게 압도적이지 않을까요?). 여기에서 데이터 시각화가 등장합니다.
데이터 시각화는 원시 데이터를 시각적 플롯과 그래프로 변환하여 인간의 두뇌가 더 쉽게 해석 할 수 있도록하는 방법입니다. 주요 목표는 연구 및 데이터 분석을 더 빠르게 수행하고 추세, 패턴을 효과적으로 전달하는 것입니다.
티인간의 두뇌는 긴 일반 텍스트보다 시각적으로 매력적인 데이터를 더 잘 이해하도록 프로그래밍되어 있습니다.
이 기사에서는 데이터 세트를 가져 와서 요구 사항에 따라 데이터를 정리하고 데이터 시각화를 시도해 보겠습니다. 데이터 세트는 Kaggle에서 가져옵니다. 찾을 수 있습니다여기.
먼저 외부 소스에서 데이터를로드하고 정리하기 위해 Pandas 라이브러리를 사용합니다. 이전 기사에서 팬더에 대해 더 많이 공부할 수 있습니다.여기.
사용하려면 Pandas 라이브러리를 가져와야합니다. 그것을 사용하여 가져올 수 있습니다.
import pandas as pdKaggle에서 가져온 CSV 파일을로드하고 이에 대해 자세히 알아 보겠습니다.
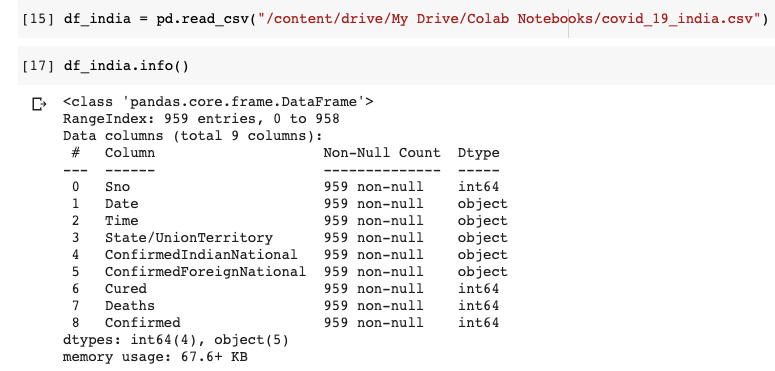
데이터 세트에 총 9 개의 열이 있음을 이해할 수 있습니다. 날짜 및 시간 열은 마지막으로 업데이트 된 날짜 및 시간을 나타냅니다. ConfirmedIndianNational 및 ConfirmedForeignNational 열은 사용하지 않습니다. 따라서이 두 개의 열을 삭제하겠습니다. 시간 열도 중요하지 않습니다. 우리도 그것을 떨어 뜨리 자. 데이터 프레임에 이미 인덱스가 있으므로 Serial No (Sno) 열도 필요하지 않습니다.
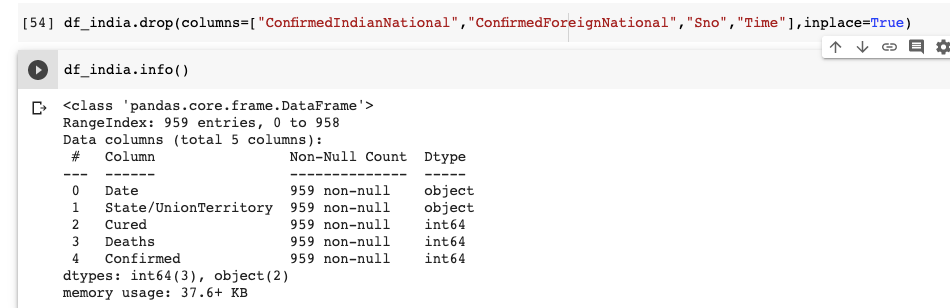
바로 데이터 프레임에 5 개의 열만 있음을 알 수 있습니다. 중복 데이터를 유지하면 불필요한 공간을 차지하고 잠재적으로 런타임이 저하 될 수 있으므로 중복 데이터를 삭제하는 것이 좋습니다.
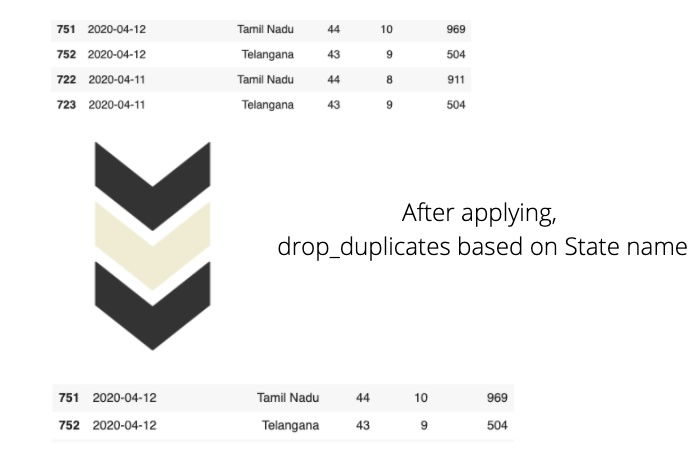
여기에서 Kaggle 데이터 세트는 매일 업데이트됩니다. 기존 데이터를 덮어 쓰는 대신 새 데이터가 추가됩니다. 예를 들어 4 월 13 일 데이터 세트에는 특정주의 누적 데이터를 나타내는 각 행이있는 925 개의 행이 있습니다. 그러나 4 월 14 일에 데이터 세트에 958 개의 행이 있었으며 이는 34 개의 새 행 (데이터 세트에 총 34 개의 상태가 있으므로)이 4 월 14 일에 추가되었음을 의미합니다.
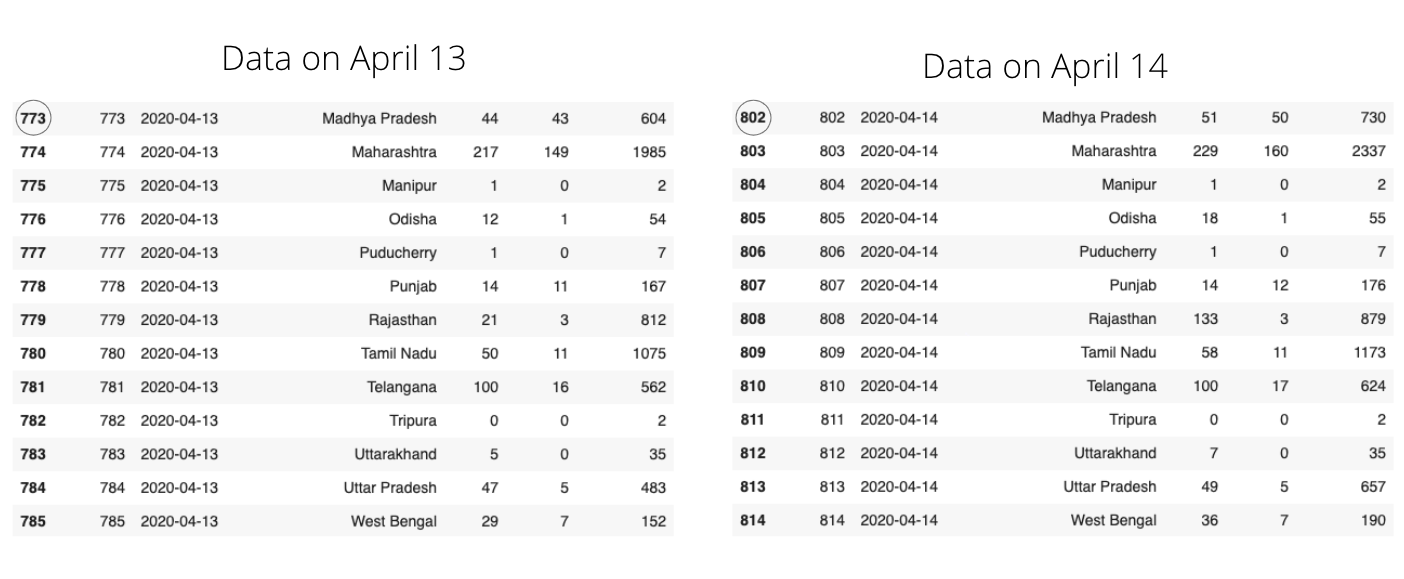
위의 그림에서 동일한 State 이름을 볼 수 있지만 다른 열의 변경 사항을 관찰하십시오. 새로운 사례에 대한 데이터는 매일 데이터 세트에 추가됩니다. 이러한 형태의 데이터는 스프레드 추세를 파악하는 데 유용 할 수 있습니다. 처럼-
- 시간 경과에 따른 케이스 수의 증가입니다.
- 시계열 분석 수행
그러나 우리는 이전 데이터를 제외하고 최신 데이터 만 분석하는 데 관심이 있습니다. 따라서 필요하지 않은 행을 삭제하겠습니다.
먼저 데이터를 날짜별로 내림차순으로 정렬하겠습니다. 상태 이름을 사용하여 데이터를 그룹화하여 중복 값을 제거하십시오.
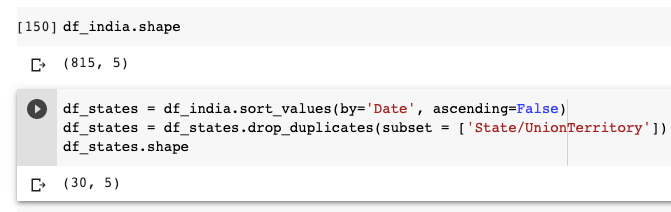
df_states 데이터 프레임에 30 개의 행만 있다는 것을 알 수 있습니다. 이는 각 상태에 대한 최신 통계를 보여주는 고유 한 행이 있음을 의미합니다. 날짜 열을 사용하여 데이터 프레임을 정렬 할 때 데이터 프레임을 날짜별로 내림차순으로 정렬하고 (코드에서 ascending = False 확인) remove_duplicates는 값의 첫 번째 항목을 저장하고 모든 중복 항목을 제거합니다.
이제 데이터 시각화에 대해 이야기하겠습니다. Plotly를 사용하여 위의 데이터 프레임을 시각화합니다.
히스토그램, 막대 그래프, 산점도는 패턴과 추세를 효율적으로 설명하지만 지리 데이터를 다루기 때문에 등치 맵을 선호합니다.
등치 맵은 무엇입니까?
Plotly에 따르면 Choropleth 맵은 데이터 변수와 관련하여 색상이 지정되거나 음영 처리 된 분할 된 지리적 영역을 나타냅니다. 이러한지도는 지리적 영역에 대한 가치를 빠르고 쉽게 표시 할 수있는 방법을 제공하며 트렌드와 패턴도 공개합니다.
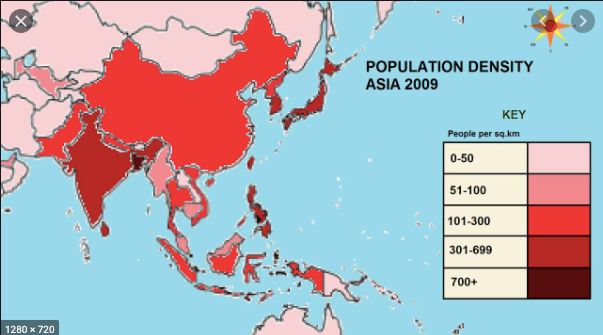
위 이미지에서 영역은 인구 밀도에 따라 색상이 지정됩니다. 색이 어두울수록 특정 지역의 인구가 더 많다는 것을 의미합니다. 이제 데이터 세트와 관련하여 확인 된 사례를 기반으로 등치 맵을 생성 할 것입니다. 확진 자 수가 많을수록 특정 부위의 색이 어두워집니다.
인도지도를 렌더링하려면 상태 좌표가있는 shapefile이 필요합니다. 인도 용 shapefile을 다운로드 할 수 있습니다.여기.
Wikipedia에 따르면shapefile형식은 지리 정보 시스템 (GIS)을위한 지리 공간 벡터 데이터 형식입니다.
shapefile로 작업하기 전에 GeoPandas를 설치해야합니다. GeoPandas는 지리 공간 데이터 작업을 쉽게 만들어주는 Python 패키지입니다.
pip install geopandas
import geopandas as gpd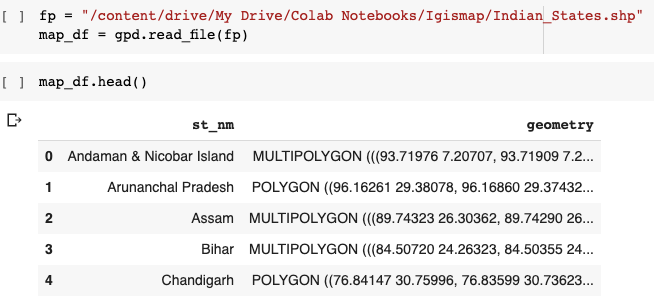
데이터 프레임에 상태 이름과 벡터 형식의 좌표가 있음을 알 수 있습니다. 이제이 shapefile을 필요한JSON체재.
import json#Read data to json.merged_json = json.loads(map_df.to_json())
다음으로 Plotly Express를 사용하여 등치 맵을 만들 것입니다. 'px.choropleth함수. 등치 맵을 만들려면 기하학적 정보가 필요합니다.
- 이것은 GeoJSON 형식 (위에서 생성 한)으로 제공 될 수 있으며 각 기능에는 고유 한 식별 값이 있습니다 (예 : st_nm)
2. 미국 주 및 세계 국가를 포함하는 Plotly 내의 기존 도형
GeoJSON 데이터, 즉 (위에서 만든 merged_json)은Geojson인수 및 측정 메트릭이색깔인수px.choropleth.
모든 등치 맵에는위치주 / 국가를 매개 변수로 사용하는 인수입니다. 인도의 여러 주에 대한 등치 맵을 만들고 있으므로 State 열을 인수에 전달합니다.
fig = px.choropleth(df_states,
geojson=merged_json,
color="Confirmed",
locations="State/UnionTerritory",
featureidkey="properties.st_nm",
color_continuous_scale = ["#ffffb2","#fecc5c","#fd8d3c","#f03b20","#bd0026"],
projection="mercator"
)fig.update_geos(fitbounds="locations", visible=False)fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})fig.show()
첫 번째 매개 변수는 데이터 프레임 자체이며 확인 된 값에 따라 색상이 달라집니다. 우리는명백한인수fig.updtae_geos ()기본지도와 프레임을 숨기려면 False로 설정합니다. 우리는 또한 설정fitbounds = "위치"세계지도를 자동으로 확대하여 관심 영역을 표시합니다.
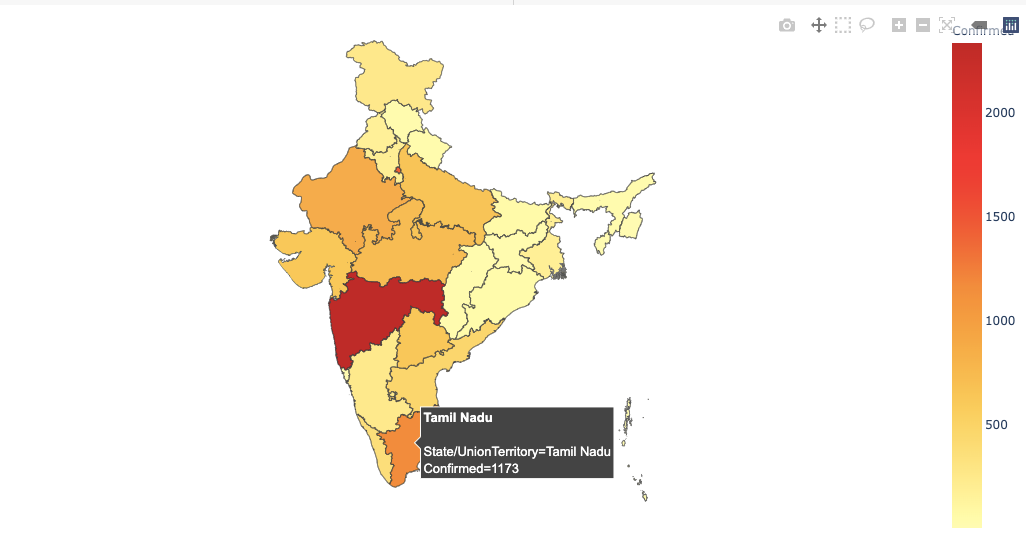
Github에서 전체 코드를 볼 수 있습니다.여기.
데이터 시각화는 매우 과소 평가 된 기술입니다. 데이터를 실시간으로 시각화 할 때 도움이 될 몇 가지 개념을 취했으면합니다. 여러분의 피드백과 응답을 자유롭게 공유하십시오. 오늘 새로운 것을 배웠다면 손을 들어보세요.
'Data Analytics(ko)' 카테고리의 다른 글
| No More Basic Plots Please -번역 (0) | 2020.10.05 |
|---|---|
| The Definitive Data Scientist Environment Setup -번역 (0) | 2020.10.03 |
| Extracting Data from PDF File Using Python and R -번역 (0) | 2020.10.02 |
| Advanced Python: Itertools Library — The Gem Of Python Language -번역 (0) | 2020.10.01 |
| Bye-bye Python. Hello Julia!-번역 (0) | 2020.09.29 |