개발자가 앱과 소프트웨어를 만들기 위해 수많은 앱과 소프트웨어를 사용하는 방식은 아이러니합니다. 시간이 지남에 따라 워크 플로의 일부로 선택한 몇 가지 도구에 대한 강력한 선호도를 개발했습니다. 그러나 일부 소프트웨어가 표준이되었다고해서 항상 다른 소프트웨어를 주시해서는 안되는 것은 아닙니다! 다음은 내가 매일 사용하려고 시도한 가장 과소 평가되었지만 엄청나게 유용한 앱 중 일부이며 여러분도 사용해야한다고 생각합니다!
내 권장 사항이 특정 프로그래밍 틈새에 초점을 맞추지 않기를 원하기 때문에 아래 표시된 앱의 눈에 띄는 부분이 터미널 기반이므로 대부분의 프로그래머 / 개발자를 대상으로합니다.
목차
Ungit
Termius
기민함
뵤부
스페이스 데스크
1. Ungit
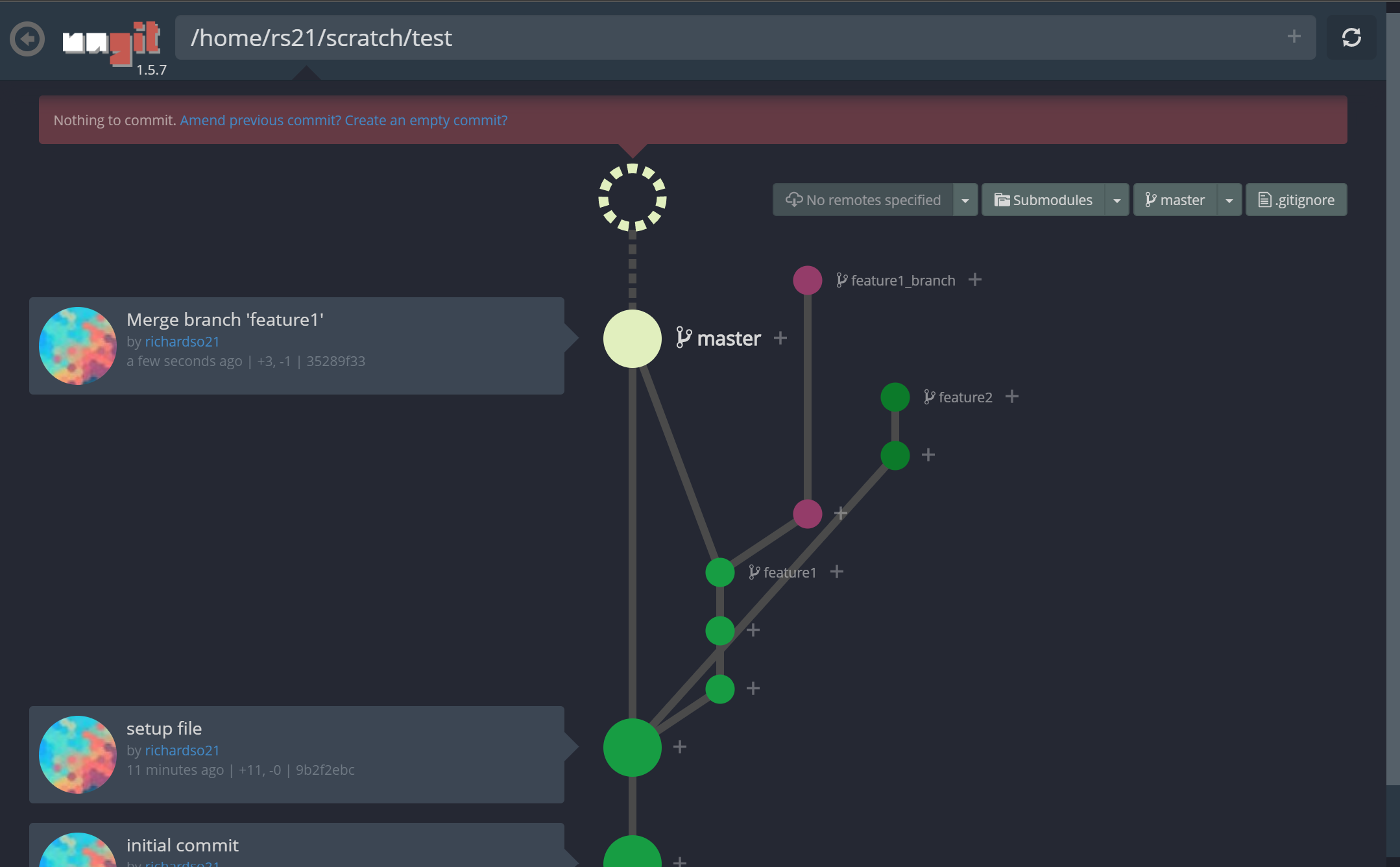
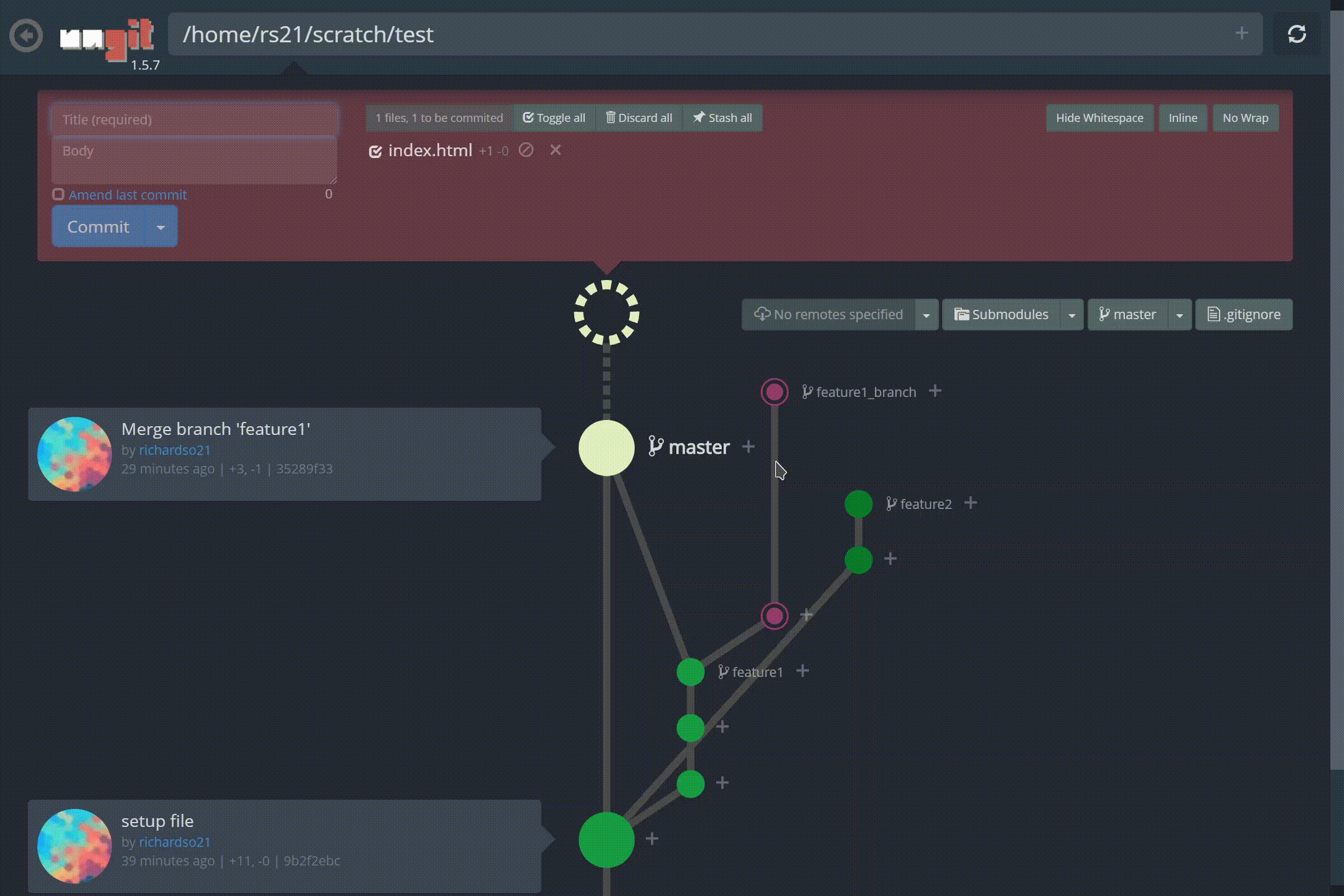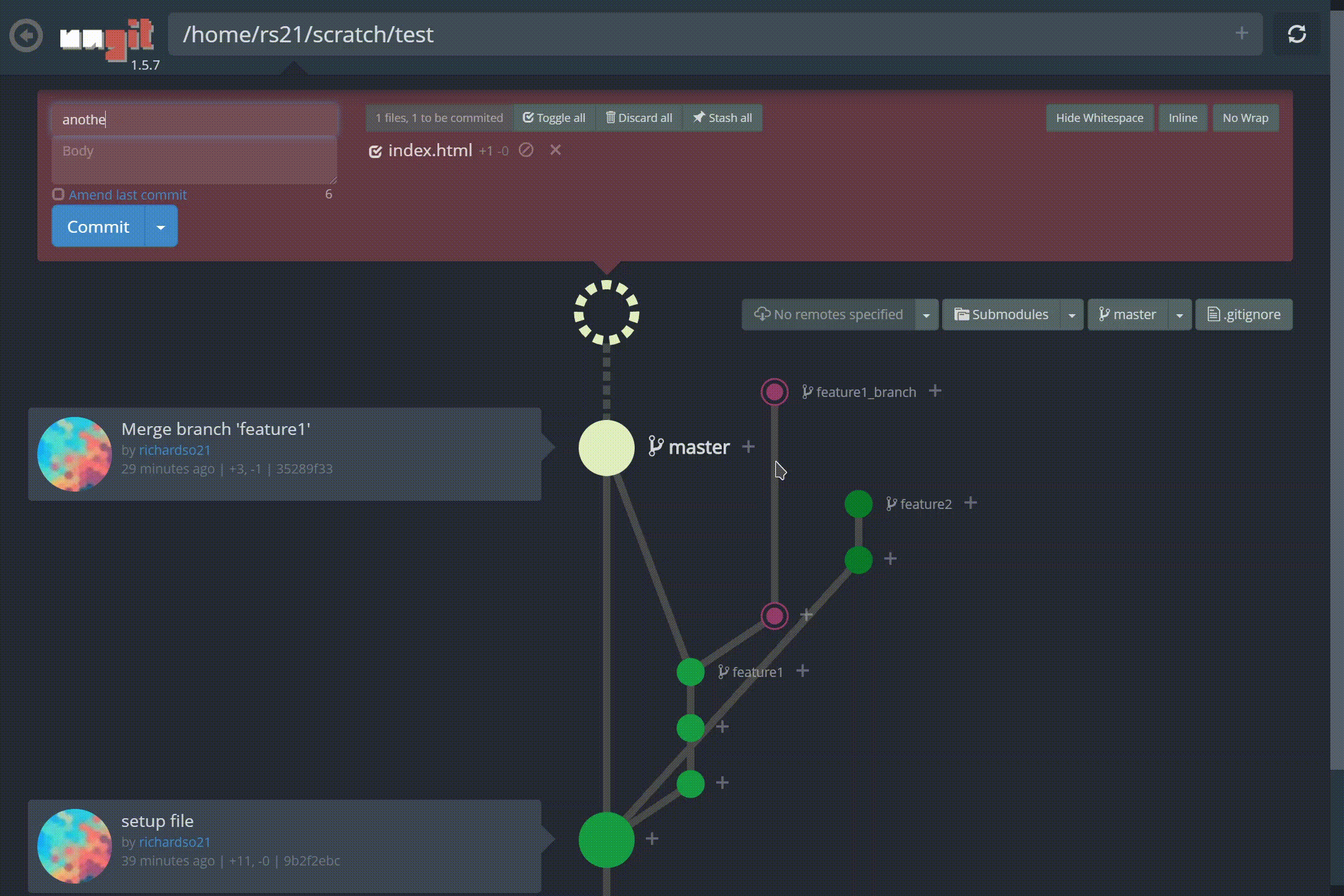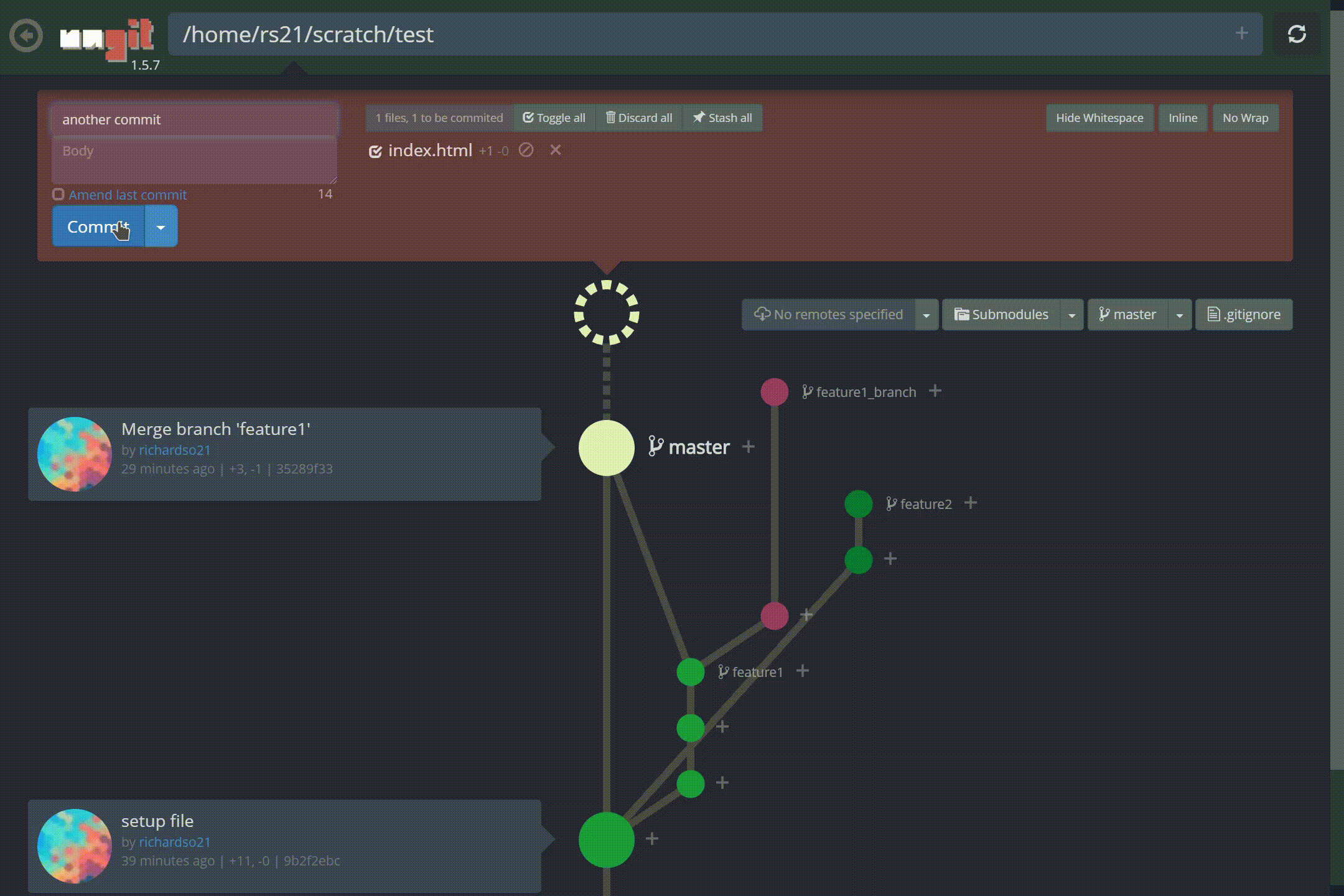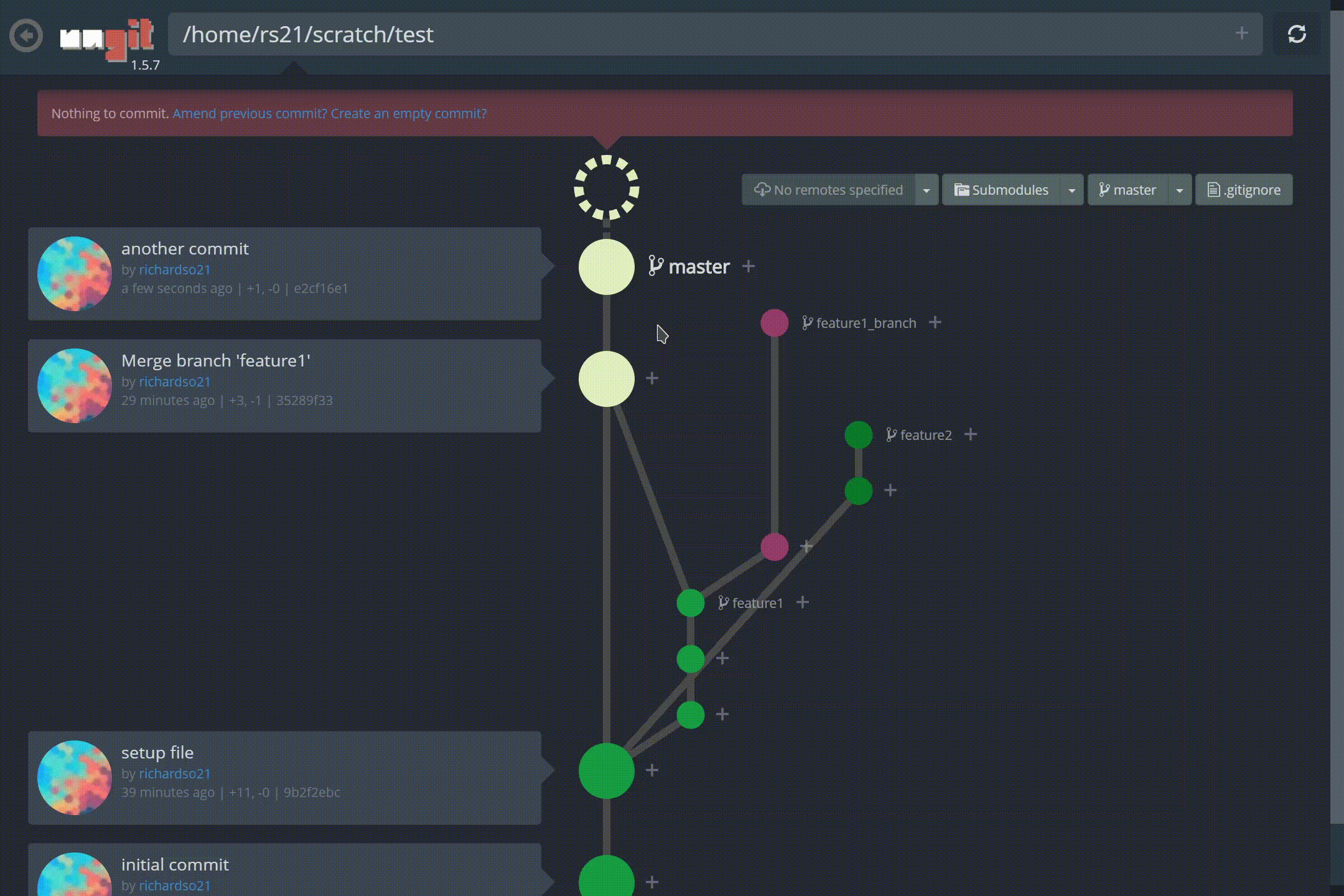
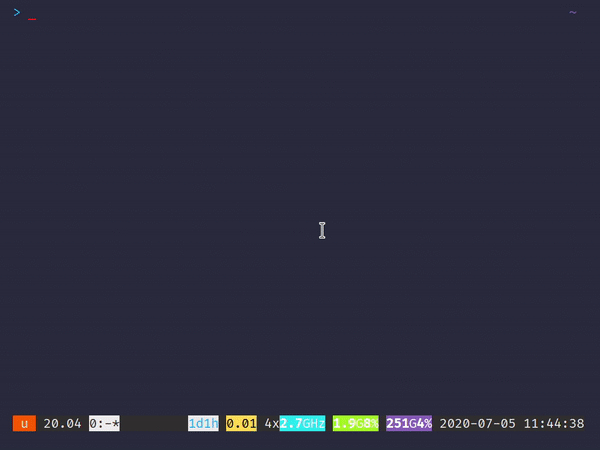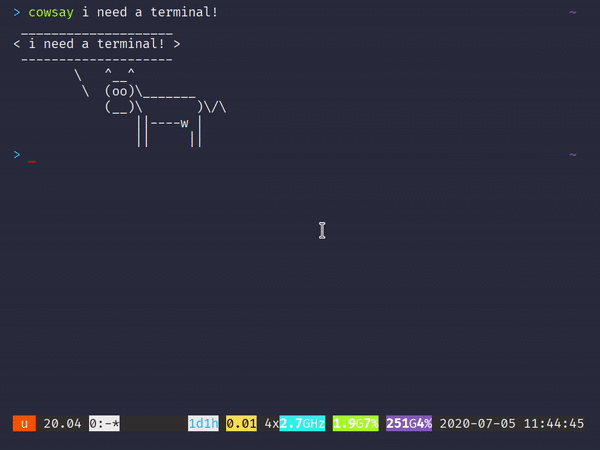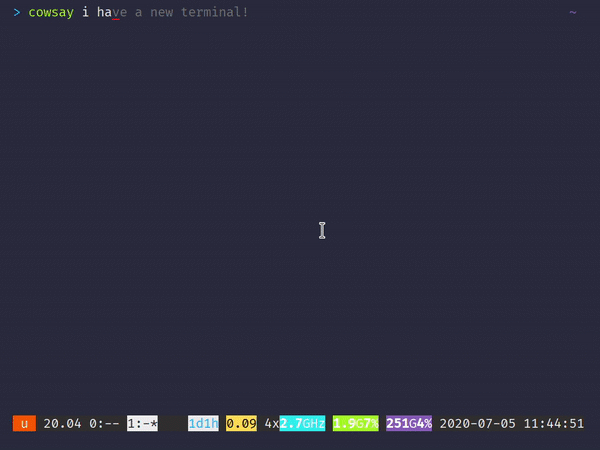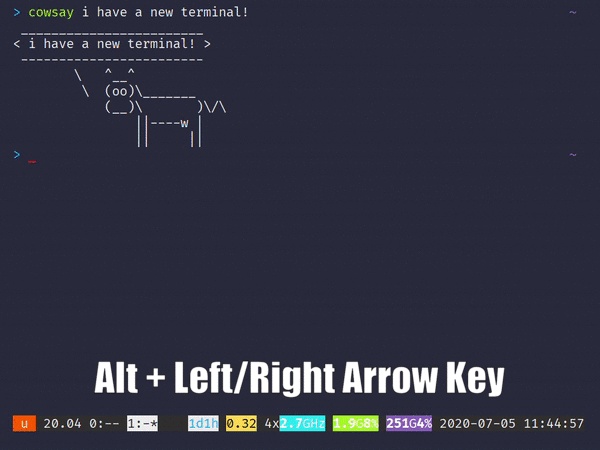
명령 줄 인터페이스를 통해 Git 리포지토리를 관리하는 것은 악명 높을 정도로 어렵습니다. 모든 사람이 사실을 알고 있습니다. 그리고 20 개 정도의 다른 브랜치가있는 프로젝트를 열면 모든 브랜치를 통해 최근 커밋을 따라 가기가 어렵습니다.분기 모델. 더 나쁜 것은 처음으로 Git을 사용하여 버전 제어를 수행하려는 초보자입니다. ㅏCLI는 사용자가 Git의 진정한 의미를 이해하도록 할 수 없습니다.
저 가지 좀 봐! 또한 커밋을 만드는 것이 그 어느 때보 다 쉬워졌습니다.재미있는 애니메이션과 결합하여느낌커밋이 완료되었습니다— 명령 줄이 유도 할 수없는 것 :
ungit에서 새 커밋 만들기
지점 간 체크 아웃도 비교적 간단합니다.UI를 통해 현재있는 브랜치와 관련된 커밋 내역을 볼 수 있습니다.:
ungit의 동일한 저장소에서 다른 분기 간 전환 (체크 아웃)
Ungit분기 병합, 태그 지정 등을 지원합니다! YouTube에서보다 포괄적 인 데모를 찾을 수 있습니다.여기.
2. Termius
격리 시간 (적어도이 글을 쓰는 시점)이므로 모두가 집에서 합리적으로 일하고 있습니다. 직장에서 컴퓨터 나 서버에 액세스해야하는 경우 어떻게합니까? 글쎄, 당신은 서버에 SSH를 사용하여 해당 컴퓨터의 터미널에 대한 액세스 권한을 부여합니다. 이것은 간단한 것으로 할 수 있지만ssh명령, 왜 안돼스타일와Termius?
TermiusMosh와 호환되는 SSH 클라이언트로, Electron을 기반으로 구축 된 것 같습니다. Windows, macOS, Linux, iOS, Android 등 상상할 수있는 모든 플랫폼에서 작동합니다.
원격 서버, Termius에서`sl` 실행 😎
Termius에 대한 사용자 지정 옵션
이 앱은 원하는대로 사용자 지정할 수있는 다양한 테마, 글꼴 및 글꼴 크기를 지원합니다. 말할 것도없이이 앱은 이미 기본 사전 설정으로 꽤 매끄럽게 보입니다.
가장 매력적인 기능 중 하나Termius, 외관과 SSH 기능을 제외하고는포트 포워딩, 내가 자주 사용하는Jupyter.
또한 여러 호스트를 기억할 수 있습니다.동조이동 중에 원격 서버 프로세스를 처리 할 때 모바일 장치로 동기화는 계정을 통해 이루어지며 무료로 등록하거나 추가 혜택을 위해 약간의 비용을 지불 할 수 있습니다.
3. 기민성
터미널에 대해 말하면기민함내 로컬 터미널 에뮬레이터로 이동합니다. Windows, macOS 및 많은 Linux 배포에서 지원됩니다. 최고의 판매 포인트 중 하나기민함그것입니다GPU 가속 지원. 이 때문에 터미널 에뮬레이터 제작자는대체 제품에 비해 놀랍도록 빠른 성능을 자랑합니다..
기민함Termius에 비해 훨씬 더 간단한 패키지로 제공되지만 사용자 정의가 부족하다는 의미는 아닙니다. 앱은 구성 파일 (형식의.yml파일)에서 제공하는그들의 레포. 거기에서 색 구성표에서 키보드 바인딩, 심지어 배경 불투명도까지 터미널에 대한 거의 모든 것을 사용자 지정할 수 있습니다! 터미널 고급 사용자이거나 로컬 디렉토리에 액세스하는 데 필요한 경우기민함!
4. 뵤부
이건 아니야기술적으로앱이나 소프트웨어이지만 개인적으로 워크 플로에서이 기능을 많이 사용했기 때문에이 기사에서이 기능을 소개해야한다고 느꼈습니다.It’s a terminal multiplexer & window manager— 사실, 실제로는 래퍼입니다.tmux및 / 또는GNU 화면,들어 보셨을 멀티플렉서입니다. 원격 서버 (Termius 😉)에서 작업 중이거나 자신의 컴퓨터에서 여러 터미널 창을 자주 여는 경우뵤부확실히 당신을위한 것입니다.
여러 터미널 인스턴스를 여는 대신뵤부하나의 인터페이스에서 모든 터미널 인스턴스를 처리합니다.. 작업을 위해 2 개의 터미널이 열려 있고이 모든 것에 동시에 쉽게 액세스해야한다고 가정 해 보겠습니다. 이것이 실제로 작동하는지 봅시다 :
Byobu를 사용하여 한 곳에서 터미널 세션 / 인스턴스 처리
재미있는 사실 : 여기 Byobu가 Alacritty로 실행 중입니다!
보시다시피 새 터미널 인스턴스를 만들고 둘 사이를 전환하는 것은 매우 간단합니다. 인스턴스 (또는 문서에 기반한 "창")는 상태 표시 줄에 아래에 나열되어 있습니다.이 표시 줄은 이미 자체적으로 좋은 정보로 채워져 있습니다.그리고 이것은 상자에서 바로 나옵니다!
Byobu의기본상태 표시 줄
여기서 그치지 않습니다. 실제로 각 창에서 개별 분할 창을 설정하여완전한터미널 레이아웃.
Byobu의 분할 창
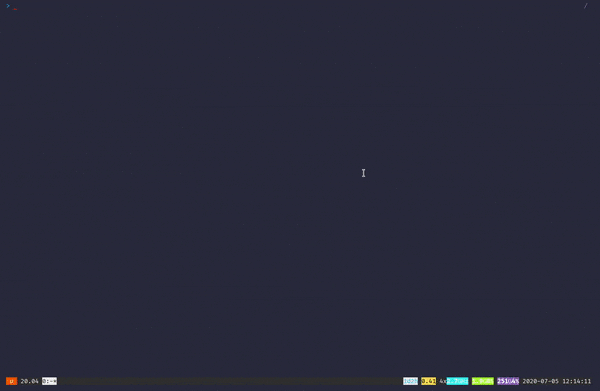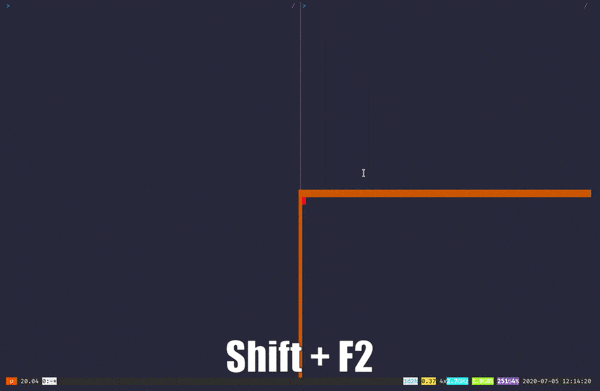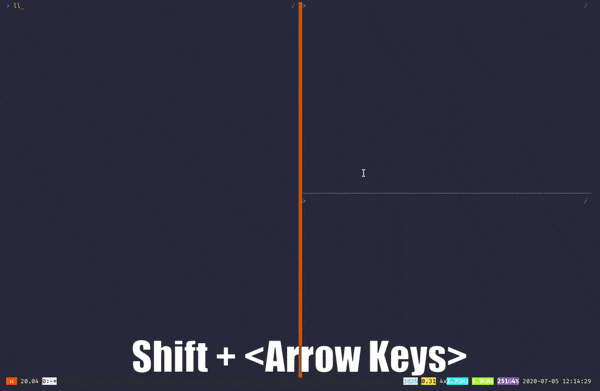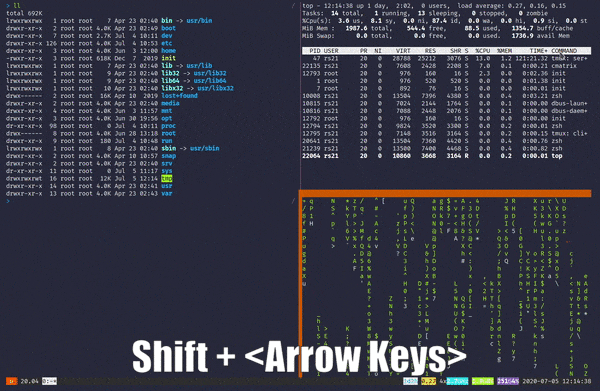
내 생각에 Byobu는 다른 멀티플렉서에 비해 배우기가 훨씬 쉽습니다. 뵤부F1, F2, F3… 등과 같은 기능 키를 사용합니다. — 기본 키보드 바인딩 용. 적어도 나에게는 모든 것을 한 줄에 두는 것이 일부 바인딩이 손 경련을 유발할 수 있더라도 모든 것을 여기에 두는 것보다 더 좋은 생각입니다. 길을 잃었거나 초보자라면 언제든지Shift + F1치트 시트를 보려면.
5. 스페이스 데스크
최근에이 앱에 대한 기사를 작성했습니다.여기. 이에 대한 자세한 내용을 원하시면 해당 기사로 넘어가십시오!
원래,스페이스 데스크iPad, Wi-Fi가 지원되는 구형 노트북 또는 휴대폰을 메인 컴퓨터의 보조 모니터로 변환 할 수 있습니다.어디에서나 Alt-Tabbing을 사용하는 데 얼마나 많은 시간을 소비하는지 깨닫는 경우를 제외하고는 지금 매우 틈새 시장처럼 들릴 수 있습니다.
따라서 두 번째 모니터를 구입하거나 예비 부품으로 DIY 모니터를 만드는 대신이 앱으로 시간과 비용을 절약 할 수 있습니다. 개인적으로 저는 이것을 사용하여 이전 노트북을 새로운 목적으로 되 살렸고 문제 나 버그가 거의 또는 전혀 보이지 않았습니다. 그만큼앱이 완전히 무선으로 실행됩니다., 따라서 더 나은 편의와 케이블 부족을 위해 인터넷 연결 상태에 따라 마일리지가 달라질 수 있습니다.
스페이스 데스크아직 베타 단계에 있지만 올해 말에 첫 번째 릴리스 버전이 될 예정 이니 계속 지켜봐 주시기 바랍니다.
결론
오늘부터 사용해야하는 과소 평가 된 앱 / 소프트웨어에 대한 내용입니다! 내가 나열한 것에 대한 생각이나 대안이 있으면 언제든지 알려 주시고 아래에서 대화를 시작하세요.언제나처럼 즐거운 코딩입니다. 여러분!
It’s ironic how developers use a plethora of apps and software to make…apps and software. Over time, we have developed strong preferences over a select few tools as part of their workflow. However, just because some pieces of software have become the norm that doesn’t mean we shouldn’t always be on the lookout for others! Here are some of the most underrated yet insanely useful apps that I’ve tried to use on a daily basis, and that I think you should use too!
Because I don’t want my recommendations to be focused towards a specific niche of programming, a noticeable fraction of apps shown below would be terminal-based, thus addressing the majority of programmers/developers.
Table of Contents
Ungit
Termius
Alacritty
Byobu
Spacedesk
1. Ungit
It is notoriously difficult to manage your Git repository through the command line interface — everyone knows that for a fact. And when you have a project open with 20 or so different branches, it’s hard to keep up with recent commits through all of them, let alone follow a branching model. Even worse are beginners trying to use Git for their first time to perform version control; a CLI can’t let users comprehend what Git really is supposed to be.
Ungit solves all of these issues with an intuitive GUI for managing Git repos.
Ungit represents your repo like a spider web of commits and branches. Here’s what it’ll look like in action:
A quick look into ungit
Look at those branches! Also, making commits are easier than ever, and paired with the fun animations, lets you feel a commit was done — something the command line can’t induce:
Creating a new commit in ungit
Checking out between branches is also relatively simple, and the UI lets you see the commit history relative to the branch you’re currently on:
Switching (Checking out) between different branches in the same repo in ungit
Ungit supports merging branches, tagging, and much more! You can find a more comprehensive demo on YouTube here.
2. Termius
It’s quarantine time (at least at the time of writing this), so everybody is reasonably working from home. What if you need to access a computer or server at your workplace? Well, you would SSH into the server, giving yourself access to the terminal on that machine. Although this is doable with a simple ssh command, why not do it in style with Termius?
Termius is an Mosh-compatible SSH client, seemingly built on top of Electron (don’t quote me on that!), which works on all platforms you’d imagine — that’s Windows, macOS, Linux, iOS, and Android.
Running `sl`, on a remote server, on Termius 😎
Customization options for Termius
The app supports a plethora of themes, fonts, and font sizes, which you can customize to your liking. Not to mention, the app already looks pretty sleek with its default presets.
One of the most compelling features of Termius, apart from its looks and SSH capability, is port forwarding, which I frequently use for Jupyter.
It also supports remembering multiple hosts, which you can then sync with your mobile devices when you’re handling remote server processes on-the-go. Syncing is done through accounts, which you can sign up for free, or pay a little for extra added benefits.
3. Alacritty
Talking about terminals, Alacritty would be my go-to local terminal emulator. It is supported in Windows, macOS, and many linux distributions. One of the best selling points of Alacritty is its support for GPU acceleration. Because of this, the makers of the terminal emulator boast blazing fast performance compared to alternatives.
Alacritty comes in a much simpler package compared to Termius, however, that doesn’t mean that it lacks in customization. The app accepts a configuration file (in the form of an .ymlfile) that you can fiddle around, provided by their repo. There, you can customize practically anything about the terminal, from color schemes to keyboard bindings to even background opacity! Whether you are a terminal power user or just need it to access your local directories, try out Alacritty!
4. Byobu
This isn’t technically an app or piece of software, but I felt compelled to feature it in this article because I’ve personally used this so much in my workflow. It’s a terminal multiplexer & window manager— in fact, it’s actually a wrapper over tmux and/or GNU screen, which are multiplexers you might’ve heard of. If you’re either working on a remote server (on Termius 😉) or find yourself frequently opening multiple terminal windows on your own machine, Byobu is definitely for you.
Instead of opening multiple terminal instances, Byobu handles all terminal instances in one interface. Let’s say you have 2 terminals open for a task, and you need to easily access all of these at the same time. Let’s see this in action:
Using Byobu to handle terminal sessions/instances in one place
Fun fact: Byobu here is running under Alacritty!
As you can see, it’s extremely simple to create a new terminal instance and switch between the two. Your instances (or “windows” based on the documentation) are listed below at the status bar, which is already by itself filled with goodies, and this comes right out of the box!
Byobu’s defaultstatus bar
It doesn’t stop there: you can actually set up individual split panes in each window, letting you create the perfect terminal layout.
Splitting panes in Byobu
Byobu is, in my opinion, much easier to learn compared to other multiplexers out there. Byobu utilizes the function keys — like F1, F2, F3…etc. — for it’s main keyboard bindings. At least for me, putting everything on a row is a better idea than having it all over the place, even if some bindings might induce some hand cramps😅. And if you’re lost or a beginner, you can always press Shift+F1 to view a cheat sheet.
5. Spacedesk
I’ve made an article on this app recently over here. If you want more details of this, you can head on to that article as well!
Basically, Spacedesk lets you convert an iPad, old laptop with wifi, or even phone into a second monitor for your main machine. It might sound extremely niche right now, except when you realize how much time you spend just Alt-Tabbing everywhere.
So, instead of buying a second monitor or trying to make a DIY monitor out of spare parts, you can save time and money with this app. Personally, I’ve used this to revive my old laptop with a new purpose, and I’ve seen little to no issues or bugs. The app runs completely wirelessly, so in exchange for better convenience and the lack of cables, your mileage may vary depending on how good your internet connection is.
Spacedesk is still in its beta stage, however, it plans to make it’s first release version later this year, so stay tuned!
Conclusion
That’s about it for some underrated apps/software you should start using today! If you have thoughts or some alternatives to ones I’ve listed feel free to let me know and start a conversation below. As always, happy coding, everybody!
Python is one of the most popular languages used by many in data science and machine learning, web development, scripting, automation, and more. One of the reasons for this popularity is its simplicity and ease of learning.
If you are reading this, you are most likely already using Python, or at least interested in it.
In this article, we’ll take a quick look at 29 short code snippets that you can understand and master incredibly quickly. Go!
👉 1. Checking for uniqueness
The next method checks if there are duplicate items in the given list. It uses a property set()that removes duplicate items from the list:
👉 2. Anagram
This method can be used to check if two strings are anagrams. An Anagram is a word or phrase formed by rearranging the letters of another word or phrase, usually using all the original letters exactly once:
👉 3. Memory
And this can be used to check the memory usage of an object:
👉 4. Size in bytes
The method returns the length of the string in bytes:
👉 5. Print the string N times
This snippet can be used to output a string nonce without the need to use loops for this:
👉 6. Makes the first letters of words large
And here is the register. The snippet uses a method title()to capitalize each word in a string:
👉 7. Separation
This method splits the list into smaller lists of the specified size:
👉 8. Removing false values
So you remove the false values ( False, None, 0and «») from the list using filter():
👉 9. Counting
The following code can be used to transpose a 2D array:
👉 10. Chain comparison
You can do multiple comparisons with all kinds of operators in one line:
👉 11. Separate with comma
The following snippet can be used to convert a list of strings to a single string, where each item from the list is separated by commas:
👉 12. Count the vowels
This method counts the number of vowels (“a”, “e”, “i”, “o”, “u”) found in the string:
👉 13. Converting the first letter of a string to lowercase
Use to convert the first letter of your specified string to lowercase:
👉 14. Anti-aliasing
The following methods flatten out a potentially deep list using recursion:
👉 15. Difference
The method finds the difference between the two iterations, keeping only the values that are in the first:
👉 16. The difference between lists
The following method returns the difference between the two lists after applying this function to each element of both lists:
👉 17. Chained function call
You can call multiple functions on one line:
👉 18. Finding Duplicates
This code checks to see if there are duplicate values in the list using the fact that set()it only contains unique values:
👉 19. Combine two dictionaries
The following method can be used to combine two dictionaries:
👉 20. Convert two lists to a dictionary
Now let’s get down to converting two lists into a dictionary:
👉 21. Using `enumerate`
The snippet shows what you can use enumerate()to get both values and indices of lists:
👉 22. Time spent
Use to calculate the time it takes for a specific code to run:
👉 23. Try / else
You can use elseas part of a block try:
👉 24. The element that appears most often
This method returns the most frequent item that appears in the list:
👉 25. Palindrome
The method checks if the given string is a palindrome:
👉 26. Calculator without if-else
The following snippet shows how to write a simple calculator without the need for conditions if-else:
👉 27. Shuffle
This code can be used to randomize the order of items in a list. Note that shuffleworks in place and returns None:
👉 28. Change values
A really quick way to swap two variables without the need for an extra one:
👉 29. Get default value for missing keys
The code shows how you can get the default value if the key you are looking for is not included in the dictionary:
Read More
If you found this article helpful, click the💚 or 👏 button below or share the article on Facebook so your friends can benefit from it too.
"=="와 "is"는 모두 Python (Python의 운영자 페이지에 링크). 초보자의 경우 "a == b"를 "a는 b와 같음", "a는 b"로 해석하고 "a는 b"로 해석 할 수 있습니다. 아마도 이것이 초보자들이 파이썬에서 "=="와 "is"를 혼동하는 이유 일 것입니다.
심층 토론을하기 전에 먼저“==”와“is”를 사용하는 몇 가지 예를 보여 드리고자합니다.
>>> a = 5 >>> b = 5 >>> a == b True >>> a is b True
간단 하죠?a == b과a는 b둘 다 반환진실. 그런 다음 다음 예제로 이동하십시오.
>>> a = 1000 >>> b = 1000 >>> a == b True >>> a is b False
뭐야?!? 첫 번째 예제에서 두 번째 예제로의 유일한 변경은 a와 b의 값이 5에서 1000까지입니다. 그러나 결과는 이미 "=="와 "is"사이에서 다릅니다. 다음으로 이동하십시오.
>>> a = [] >>> b = [] >>> a == b True >>> a is b False
당신의 마음이 여전히 날아 가지 않은 경우 마지막 예가 있습니다.
>>> a = 1000 >>> b = 1000 >>> a == b True >>> a is b False >>> a = b >>> a == b True >>> a is b True
"=="에 대한 공식적인 연산은 평등이고 "is"에 대한 연산은 동일성입니다. 두 개체의 값을 비교하려면 "=="를 사용합니다. "a == b"는 "a의 값이 b의 값과 같은지 여부"로 해석되어야합니다. 위의 모든 예에서 a의 값은 항상 b의 값과 같습니다 (빈 목록 예의 경우에도). 따라서“a == b”는 항상 참입니다.
정체성을 설명하기 전에 먼저신분증함수. 다음을 사용하여 개체의 ID를 얻을 수 있습니다.신분증함수. 이 아이덴티티는 시간 내내이 객체에 대해 고유하고 일정합니다. 이것을이 객체의 주소로 생각할 수 있습니다. 두 개체의 ID가 동일한 경우 해당 값도 동일해야합니다.
>>> id(a) 2047616
연산자 "is"는 두 개체의 ID가 동일한 지 여부를 비교하는 것입니다. “a is b”는“a의 정체는 b의 정체와 같다”는 의미입니다.
"=="및 "is"의 실제 의미를 알고 나면 위의 예를 자세히 살펴볼 수 있습니다.
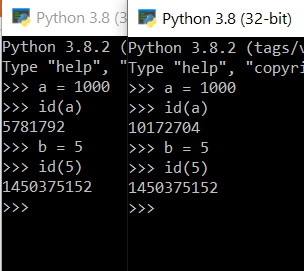
첫 번째는 첫 번째와 두 번째 예의 다른 결과입니다. 다른 결과를 보여주는 이유는 파이썬이 각 정수에 대해 고정 된 ID로 -5에서 256까지의 정수 배열 목록을 저장하기 때문입니다. 이 범위 내의 정수 변수를 할당하면 Python은이 변수의 ID를 배열 목록 내의 정수에 대한 ID로 할당합니다. 결과적으로 첫 번째 예에서 a와 b의 ID는 모두 배열 목록에서 가져 오므로 해당 ID는 물론 동일하므로a는 b사실이다.
>>> a = 5 >>> id(a) 1450375152 >>> b = 5 >>> id(b) 1450375152
그러나 일단이 변수의 값이이 범위를 벗어나면 내부 파이썬에는 그 값을 가진 객체가 없기 때문에 파이썬은이 변수에 대한 새로운 ID를 만들고이 변수에 값을 할당합니다. 이전에 말했듯이 ID는 각 생성에 대해 고유하므로 두 변수의 값이 동일하더라도 ID는 동일하지 않습니다. 그래서a는 b두 번째 예에서는 False입니다.
>>> a = 1000 >>> id(a) 12728608 >>> b = 1000 >>> id(b) 13620208
(추가 : 두 개의 콘솔을 열면 값이 여전히 범위 내에 있으면 동일한 ID를 얻을 수 있습니다. 그러나 값이 범위를 벗어나는 경우에는 해당되지 않습니다.)
첫 번째 예제와 두 번째 예제의 차이점을 이해하면 세 번째 예제의 결과를 쉽게 이해할 수 있습니다. 파이썬은 "빈 목록"객체를 저장하지 않기 때문에 파이썬은 하나의 새 객체를 만들고 "빈 목록"값을 할당합니다. 두 목록이 비어 있거나 동일한 요소가 있어도 결과는 동일합니다.
>>> a = [1,10,100,1000] >>> b = [1,10,100,1000] >>> a == b True >>> a is b False >>> id(a) 12578024 >>> id(b) 12578056
마지막으로 마지막 예제로 이동합니다. 두 번째 예제와 마지막 예제의 유일한 차이점은 코드가 한 줄 더 있다는 것입니다.a = b. 그러나이 코드 줄은 변수의 운명을 변경합니다.ㅏ. 아래 결과는 그 이유를 알려줍니다.
>>> a = 1000 >>> b = 2000 >>> id(a) 2047616 >>> id(b) 5034992 >>> a = b >>> id(a) 5034992 >>> id(b) 5034992 >>> a 2000 >>> b 2000
보시다시피a = b, 정체성ㅏ신원 변경비.a = b신원을 할당비...에ㅏ. 그래서 둘 다ㅏ과비동일한 정체성을 가지므로ㅏ지금은 가치와 동일합니다비, 즉 2000입니다.
마지막 예는 특히 개체가 목록 인 경우 예고없이 실수로 개체의 값을 변경할 수 있다는 중요한 메시지를 알려줍니다.
>>> a = [1,2,3] >>> id(a) 5237992 >>> b = a >>> id(b) 5237992 >>> a.append(4) >>> a [1, 2, 3, 4] >>> b [1, 2, 3, 4]
위의 예에서, 둘 다ㅏ과비동일한 신원을 가지고, 그 값은 동일해야합니다. 따라서 새 요소를 추가 한 후ㅏ, 의 가치비또한 영향을받습니다. 이러한 상황을 방지하기 위해 동일한 ID를 참조하지 않고 한 개체에서 다른 개체로 값을 복사하려는 경우 모든 방법에 대한 방법은 다음을 사용하는 것입니다.딥 카피모듈에서부(Python 문서에 링크). 목록의 경우 수행 할 수도 있습니다.b = a [:].
A few days ago when I browsed the “learnpython” sub on Reddit, I saw a Redditor asking this question again. Although there are too many answers and explanations about this question on the Internet, many beginners still do not know about it and make mistakes. Here is the question
Both “==” and “is” are operators in Python(Link to operator page in Python). For beginners, they may interpret “a == b” as “a is equal to b” and “a is b” as, well, “a is b”. Probably this is the reason why beginners confuse “==” and “is” in Python.
I want to show some examples of using “==” and “is” first before the in-depth discussion.
>>> a = 5 >>> b = 5 >>> a == b True >>> a is b True
Simple, right? a == b and a is b both return True. Then go to the next example.
>>> a = 1000 >>> b = 1000 >>> a == b True >>> a is b False
WTF ?!? The only change from the first example to the second is the values of a and b from 5 to 1000. But the results already differ between “==” and “is”. Go to the next one.
>>> a = [] >>> b = [] >>> a == b True >>> a is b False
Here is the last example if your mind is still not blown.
>>> a = 1000 >>> b = 1000 >>> a == b True >>> a is b False >>> a = b >>> a == b True >>> a is b True
The official operation for “==” is equality while the operation for “is” is identity. You use “==” for comparing the values of two objects. “a == b” should be interpreted as “The value of a is whether equal to the value of b”. In all examples above, the value of a is always equal to the value of b (even for the empty list example). Therefore “a == b” is always true.
Before explaining identity, I need to first introduce id function. You can get the identity of an object with idfunction. This identity is unique and constant for this object throughout the time. You can think of this as an address for this object. If two objects have the same identity, their values must be also the same.
>>> id(a) 2047616
The operator “is” is to compare whether the identities of two objects are the same. “a is b” means “The identity of a is the same as the identity of b”.
Once you know the actual meanings of “==” and “is”, we can start going deep on those examples above.
First is the different results in the first and second examples. The reason for showing different results is that Python stores an array list of integers from -5 to 256 with a fixed identity for each integer. When you assign a variable of an integer within this range, Python will assign the identity of this variable as the one for the integer inside the array list. As a result, for the first example, since the identities of a and b are both obtained from the array list, their identities are of course the same and therefore a is bis True.
>>> a = 5 >>> id(a) 1450375152 >>> b = 5 >>> id(b) 1450375152
But once the value of this variable falls outside this range, since Python inside does not have an object with that value, therefore Python will create a new identity for this variable and assign the value to this variable. As said before, the identity is unique for each creation, therefore even the values of two variables are the same, their identities are never equal. That’s why a is bin the second example is False
>>> a = 1000 >>> id(a) 12728608 >>> b = 1000 >>> id(b) 13620208
(Extra: if you open two consoles, you will get the same identity if the value is still within the range. But of course, this is not the case if the value falls outside the range.)
Once you understand the difference between the first and second examples, it is easy to understand the result for the third example. Because Python does not store the “empty list” object, so Python creates one new object and assign the value “empty list”. The result will be the same no matter the two lists are empty or with identical elements.
>>> a = [1,10,100,1000] >>> b = [1,10,100,1000] >>> a == b True >>> a is b False >>> id(a) 12578024 >>> id(b) 12578056
Finally, we move on to the last example. The only difference between the second and the last example is that there is one more line of code a = b.However this line of code changes the destiny of the variable a. The below result tells you why.
>>> a = 1000 >>> b = 2000 >>> id(a) 2047616 >>> id(b) 5034992 >>> a = b >>> id(a) 5034992 >>> id(b) 5034992 >>> a 2000 >>> b 2000
As you can see, after a = b, the identity of a changes to the identity of b. a = bassigns the identity of bto a. So both aand b have the same identity, and thus the value of a now is the same as the value of b, which is 2000.
The last example tells you an important message that you may accidentally change the value of an object without notice, especially when the object is a list.
>>> a = [1,2,3] >>> id(a) 5237992 >>> b = a >>> id(b) 5237992 >>> a.append(4) >>> a [1, 2, 3, 4] >>> b [1, 2, 3, 4]
From the above example, because both a and bhave the same identity, their values must be the same. And thus after appending a new element to a, the value of bwill be also impacted. To prevent this situation, if you want to copy the value from one object to another object without referring to the same identity, the one for all method is to use deepcopyin the module copy (Link to Python document). For list, you can also perform by b = a[:] .
Scikit-learn (sklearn)강력한 오픈 소스입니다기계 학습 라이브러리Python 프로그래밍 언어 위에 구축되었습니다. 이 라이브러리에는 다양한 분류, 회귀 및 클러스터링 알고리즘을 포함하여 기계 학습 및 통계 모델링을위한 많은 효율적인 도구가 포함되어 있습니다.
이 기사에서는 scikit-learn 라이브러리와 관련된 6 가지 트릭을 보여 주어 특정 프로그래밍 방식을 좀 더 쉽게 할 수 있습니다.
1. 임의 더미 데이터 생성
임의의 '더미'데이터를 생성하기 위해make_classification ()의 경우 기능분류 데이터, 및make_regression ()의 경우 기능회귀 데이터. 이것은 디버깅 할 때나 (작은) 임의의 데이터 세트에서 특정 작업을 시도하려는 경우에 매우 유용합니다.
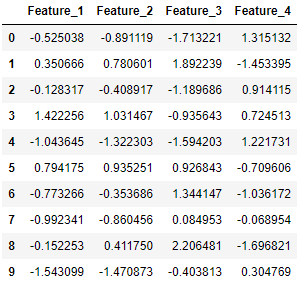
아래에서는 4 개의 특성 (X에 있음)과 클래스 레이블 (y에 있음)로 구성된 10 개의 분류 데이터 포인트를 생성합니다. 여기서 데이터 포인트는 네거티브 클래스 (0) 또는 포지티브 클래스 (1)에 속합니다.
from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=10, n_features=4, n_classes=2, random_state=123)
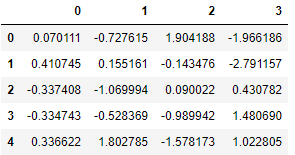
Scikit-learn은돌리다누락 된 값. 여기에서는 두 가지 접근 방식을 고려합니다. 그만큼SimpleImputer클래스는 결 측값을 대치하기위한 기본 전략을 제공합니다 (예 : 평균 또는 중앙값을 통해). 보다 정교한 접근 방식KNNImputer클래스는 다음을 사용하여 결 측값을 채우기위한 대치를 제공합니다.K- 최근 접 이웃접근하다. 각 누락 된 값은n_neighbors특정 기능에 대한 값이있는 최근 접 이웃. 이웃 값은 균일하게 평균화되거나 각 이웃까지의 거리에 따라 가중치가 부여됩니다.
아래에서는 두 대치 방법을 사용하는 예제 응용 프로그램을 보여줍니다.
from sklearn.experimental import enable_iterative_imputer from sklearn.impute import SimpleImputer, KNNImputer from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=5, n_features=4, n_classes=2, random_state=123) X = pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])print(X.iloc[1,2])
>>> 2.21298305
X [1, 2]를 누락 된 값으로 변환합니다.
X.iloc[1, 2] = float('NaN')X
먼저 우리는단순 전가:
imputer_simple = SimpleImputer()
pd.DataFrame(imputer_simple.fit_transform(X))
결과 값-0.143476.
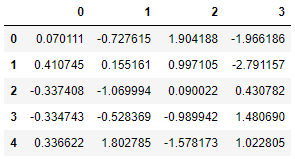
다음으로 우리는KNN 입력, 2 개의 가장 가까운 이웃이 고려되고 이웃에 균일 한 가중치가 부여됩니다.
그만큼관로scikit-learn의 도구는 기계 학습 모델을 단순화하는 데 매우 유용합니다. 파이프 라인을 사용하여 여러 단계를 하나로 연결하여 데이터가 고정 된 일련의 단계를 거치도록 할 수 있습니다. 따라서 모든 단계를 개별적으로 호출하는 대신 파이프 라인은 모든 단계를 하나의 시스템으로 연결합니다. 이러한 파이프 라인을 생성하기 위해 우리는make_pipeline함수.
아래에는 파이프 라인이 누락 된 값 (있는 경우)을 대치하는 대치 자와 로지스틱 회귀 분류기로 구성된 간단한 예가 나와 있습니다.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=25, n_features=4, n_classes=2, random_state=123)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
scikit-learn을 통해 생성 된 파이프 라인 모델은 다음을 사용하여 쉽게 저장할 수 있습니다.joblib. 모델에 큰 데이터 배열이 포함 된 경우 각 배열은 별도의 파일에 저장됩니다. 로컬에 저장되면 새 응용 프로그램에서 사용할 모델을 쉽게로드 (또는 복원) 할 수 있습니다.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import joblibX, y = make_classification(n_samples=20, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
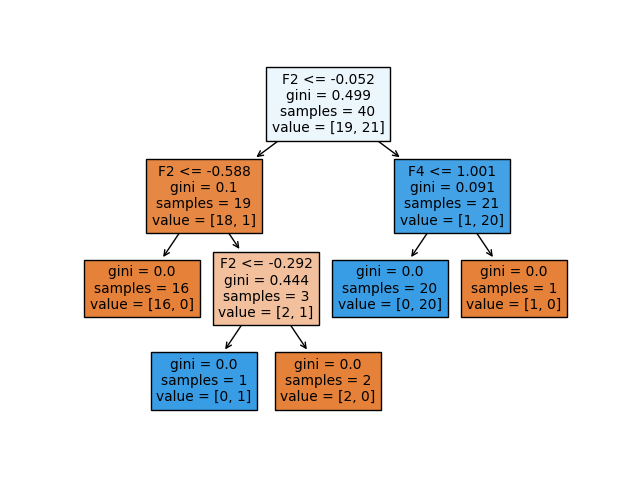
가장 잘 알려진 분류 알고리즘 중 하나는의사 결정 트리, 특징매우 직관적 인 나무 모양의 시각화. 의사 결정 트리의 아이디어는 설명 기능을 기반으로 데이터를 더 작은 영역으로 분할하는 것입니다. 그런 다음 테스트 관찰이 속한 지역에서 훈련 관찰 중 가장 일반적으로 발생하는 클래스는 예측입니다. 데이터가 지역으로 분할되는 방법을 결정하려면 다음을 적용해야합니다.분할 측정각 기능의 관련성과 중요성을 결정합니다. 잘 알려진 분할 측정으로는 정보 이득, 지니 지수 및 교차 엔트로피가 있습니다.
아래에서는 사용 방법에 대한 예를 보여줍니다.plot_treescikit-learn의 기능 :
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier, plot_tree from sklearn.datasets import make_classification
X, y = make_classification(n_samples=50, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
이 예에서는 네거티브 클래스 (0) 또는 포지티브 클래스 (1)에 속하는 40 개의 훈련 관찰에 대한 의사 결정 트리를 피팅하고 있습니다.이진 분류 문제. 트리에는 두 가지 종류의 노드가 있습니다.내부 노드(예측 자 공간이 더 분할 된 노드) 또는터미널 노드(종료점). 두 노드를 연결하는 트리의 세그먼트를가지.
의사 결정 트리의 각 노드에 대해 제공되는 정보를 자세히 살펴 보겠습니다.
그만큼분할 기준 used in the particular node is shown as e.g. ‘F2 <= -0.052’. This means that every data point that satisfies the condition that the value of the second feature is below -0.052 belongs to the newly formed region to the left, and the data points that do not satisfy the condition belong to the region to the right of the internal node.
그만큼지니 지수여기서 분할 측정으로 사용됩니다. 지니 지수 (불결)는 특정 요소가 무작위로 선택되었을 때 잘못 분류되는 정도 또는 확률을 측정합니다.
노드의 '샘플'은 특정 노드에서 발견 된 훈련 관찰의 수를 나타냅니다.
노드의 '값'은 각각 네거티브 클래스 (0)와 포지티브 클래스 (1)에서 찾은 훈련 관찰의 수를 나타냅니다. 따라서 value = [19,21]은 19 개의 관측치가 네거티브 클래스에 속하고 21 개의 관측치가 해당 특정 노드의 포지티브 클래스에 속함을 의미합니다.
결론
이 기사에서는 sklearn에서 기계 학습 모델을 개선하기위한 6 가지 유용한 scikit-learn 트릭을 다뤘습니다. 이 트릭이 어떤 식 으로든 도움이 되었기를 바랍니다. scikit-learn 라이브러리를 사용할 때 다음 프로젝트에서 행운을 빕니다!
Scikit-learn (sklearn) is a powerful open source machine learning library built on top of the Python programming language. This library contains a lot of efficient tools for machine learning and statistical modeling, including various classification, regression, and clustering algorithms.
In this article, I will show 6 tricks regarding the scikit-learn library to make certain programming practices a bit easier.
1. Generate random dummy data
To generate random ‘dummy’ data, we can make use of the make_classification() function in case of classification data, and make_regression() function in case of regression data. This is very useful in some cases when debugging or when you want to try out certain things on a (small) random data set.
Below, we generate 10 classification data points consisting of 4 features (found in X) and a class label (found in y), where the data points belong to either the negative class (0) or the positive class (1):
from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=10, n_features=4, n_classes=2, random_state=123)
Here, X consists of the 4 feature columns for the generated data points:
And y contains the corresponding label of each data point:
pd.DataFrame(y, columns=['Label'])
2. Impute missing values
Scikit-learn offers multiple ways to impute missing values. Here, we consider two approaches. The SimpleImputer class provides basic strategies for imputing missing values (through the mean or median for example). A more sophisticated approach the KNNImputer class, which provides imputation for filling in missing values using the K-Nearest Neighbors approach. Each missing value is imputed using values from the n_neighbors nearest neighbors that have a value for the particular feature. The values of the neighbors are averaged uniformly or weighted by distance to each neighbor.
Below, we show an example application using both imputation methods:
from sklearn.experimental import enable_iterative_imputer from sklearn.impute import SimpleImputer, KNNImputer from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=5, n_features=4, n_classes=2, random_state=123) X = pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])print(X.iloc[1,2])
>>> 2.21298305
Transform X[1, 2] to a missing value:
X.iloc[1, 2] = float('NaN')X
First we make use of the simple imputer:
imputer_simple = SimpleImputer()
pd.DataFrame(imputer_simple.fit_transform(X))
Resulting in a value of -0.143476.
Next, we try the KNN imputer, where the 2 nearest neighbors are considered and the neighbors are weighted uniformly:
Resulting in a value of 0.997105 (= 0.5*(1.904188+0.090022)).
3. Make use of Pipelines to chain multiple steps together
The Pipeline tool in scikit-learn is very helpful to simplify your machine learning models. Pipelines can be used to chain multiple steps into one, so that the data will go through a fixed sequence of steps. Thus, instead of calling every step separately, the pipeline concatenates all steps into one system. To create such a pipeline, we make use of the make_pipeline function.
Below, a simple example is shown, where the pipeline consists of an imputer, which imputes missing values (if there are any), and a logistic regression classifier.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=25, n_features=4, n_classes=2, random_state=123)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
Now, we can use the pipeline to fit our training data and to make predictions for the test data. First, the training data goes through to imputer, and then it starts training using the logistic regression classifier. Then, we are able to predict the classes for our test data:
Pipeline models created through scikit-learn can easily be saved by making use of joblib. In case your model contains large arrays of data, each array is stored in a separate file. Once saved locally, one can easily load (or, restore) their model for use in new applications.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import joblibX, y = make_classification(n_samples=20, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
Now, the fitted pipeline model is saved (dumped) on your computer through joblib.dump. This model is restored through joblib.load, and can be applied as usual afterwards:
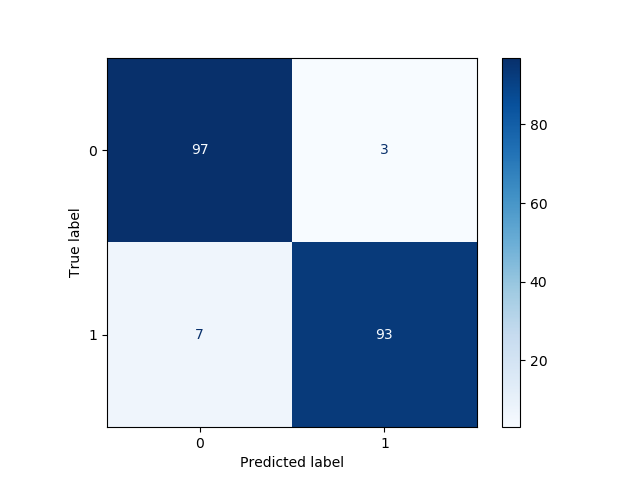
A confusion matrix is a table that is used to describe the performance of a classifier on a set of test data. Here, we focus on a binary classification problem, i.e., there are two possible classes that observations could belong to: “yes” (1) and “no” (0).
Let’s create an example binary classification problem, and display the corresponding confusion matrix, by making use of the plot_confusion_matrix function:
from sklearn.model_selection import train_test_split from sklearn.metrics import plot_confusion_matrix from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classificationX, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
Here, we have visualized in a nice way through the confusion matrix that there are:
93 true positives (TP);
97 true negatives (TN);
3 false positives (FP);
7 false negatives (FN).
So, we have reached an accuracy score of (93+97)/200 = 95%.
6. Visualize decision trees
One of the most well known classification algorithms is the decision tree, characterized byits tree-like visualizations which are very intuitive. The idea of a decision tree is to split the data into smaller regions based on the descriptive features. Then, the most commonly occurring class amongst training observations in the region to which the test observation belongs is the prediction. To decide how the data is split into regions, one has to apply a splitting measure to determine the relevance and importance of each of the features. Some well known splitting measures are Information Gain, Gini index and Cross-entropy.
Below, we show an example on how to make use of the plot_tree function in scikit-learn:
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier, plot_tree from sklearn.datasets import make_classification
X, y = make_classification(n_samples=50, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
In this example, we are fitting a decision tree on 40 training observations, that belong to either the negative class (0) or the positive class (1), so we are dealing with a binary classification problem. In the tree, we have two kinds of nodes, namely internal nodes (nodes where the predictor space is split further) or terminal nodes (end point). The segments of the trees that connect two nodes are called branches.
Let‘s have a closer look at the information provided for each node in the decision tree:
The splitting criterion used in the particular node is shown as e.g. ‘F2 <= -0.052’. This means that every data point that satisfies the condition that the value of the second feature is below -0.052 belongs to the newly formed region to the left, and the data points that do not satisfy the condition belong to the region to the right of the internal node.
The Gini index is used as splitting measure here. The Gini index (called a measure of impurity) measures the degree or probability of a particular element being wrongly classified when it is randomly chosen.
The ‘samples’ of the node indicates how many training observations are found in the particular node.
The ‘value’ of the node indicates the number of training observations found in the negative class (0) and the positive class (1) respectively. So, value=[19,21] means that 19 observations belong to the negative class and 21 observations belong to the positive class in that particular node.
Conclusion
This article covered 6 useful scikit-learn tricks to improve your machine learning models in sklearn. I hope these tricks have helped you in some way, and I wish you good luck on your next project when making use of the scikit-learn library!
Another cool behavior of the |= operator is the ability to update the dictionary with new key-value pairs using an iterable object — like a list or generator:
a = {'a': 'one', 'b': 'two'} b = ((i, i**2) for i in range(3))a |= b print(a)
[Out]: {'a': 'one', 'b': 'two', 0: 0, 1: 1, 2: 4}
If we attempt the same with the standard union operator | we will get a TypeError as it will only allow unions between dict types.
Type Hinting
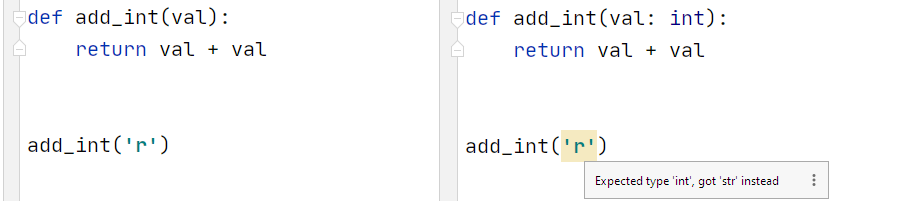
Python is dynamically typed, meaning we don’t need to specify datatypes in our code.
This is okay, but sometimes it can be confusing, and suddenly Python’s flexibility becomes more of a nuisance than anything else.
Since 3.5, we could specify types, but it was pretty cumbersome. This update has truly changed that, let’s use an example:
No type hinting (left) v type hinting with 3.9 (right)
In our add_int function, we clearly want to add the same number to itself (for some mysterious undefined reason). But our editor doesn’t know that, and it is perfectly okay to add two strings together using + — so no warning is given.
What we can now do is specify the expected input type as int. Using this, our editor picks up on the problem immediately.
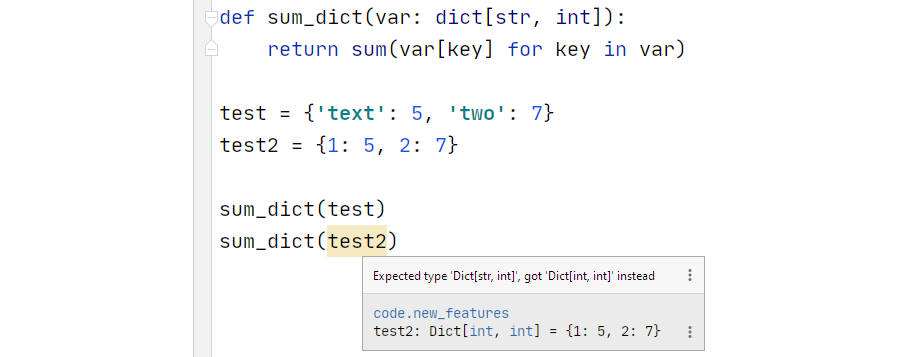
We can get pretty specific about the types included too, for example:
Type hinting can be used everywhere — and thanks to the new syntax, it now looks much cleaner:
We specify sum_dict’s argument as a dict and the returned value as an int. During test definition, we also determine it’s type.
String Methods
Not as glamourous as the other new features, but still worth a mention as it is particularly useful. Two new string methods for removing prefixes and suffixes have been added:
"Hello world".removeprefix("He")
[Out]: "llo world"
Hello world".removesuffix("ld")
[Out]: "Hello wor"
New Parser
This one is more of an out-of-sight change but has the potential of being one of the most significant changes for the future evolution of Python.
Python currently uses a predominantly LL(1)-based grammar, which in turn can be parsed by a LL(1) parser — which parses code top-down, left-to-right, with a lookahead of just one token.
Now, I have almost no idea of how this works — but I can give you a few of the current issues in Python due to the use of this method:
Python contains non-LL(1) grammar; because of this, some parts of the current grammar use workarounds, creating unnecessary complexity.
LL(1) creates limitations in the Python syntax (without possible workarounds). This issue highlights that the following code simply cannot be implemented using the current parser (raising a SyntaxError):
with (open("a_really_long_foo") as foo, open("a_really_long_bar") as bar): pass
LL(1) breaks with left-recursion in the parser. Meaning particular recursive syntax can cause an infinite loop in the parse tree. Guido van Rossum, the creator of Python, explains this here.
All of these factors (and many more that I simply cannot comprehend) have one major impact on Python; they limit the evolution of the language.
The new parser, based on PEG, will allow the Python developers significantly more flexibility — something we will begin to notice from Python 3.10 onwards.
That is everything we can look forward to with the upcoming Python 3.9. If you really can’t wait, the most recent beta release — 3.9.0b3 — is available here.
If you have any questions or suggestions, feel free to reach out via Twitter or in the comments below.
Thanks for reading!
If you enjoyed this article and want to learn more about some of the lesser-known features in Python, you may be interested in my previous article: