PYTHON PROGRAMMING
10 Crazy Cool Project Ideas for Python Developers
Crazy project ideas to challenge your Python skills

Did you know Python is known as an all-rounder programming language?
Yes, it is, though it shouldn’t be used on every single project,
You can use it to create desktop applications, games, mobile apps, websites, and system software. It is even the most suitable language for the implementation of Artificial Intelligence and Machine Learning algorithms.
So, I spent the last few weeks collecting unique project ideas for Python developers. These project ideas will hopefully bring back your interest in this amazing language. The best part is that you can enhance your Python programming skills with these fun but challenging projects.
Let’s have a look at them one-by-one.
1- Create a Software GUI Using Voice Commands

These days, massive progress has been made in the field of desktop application development. You will see many drag & drop GUI builders and speech recognition libraries. So, why not join them together and create a user interface by talking with the computer?
This is purely a new concept and after some research, I found that no one has ever attempted to do it. So, it might be a little bit more challenging than the ones mentioned below.
Here are some instructions to get started on this project using Python. First of all, you need these packages:-
- Speech Recognition Library
- PAGE — Drag & Drop GUI Builder
- Documentation
- Video of how PAGE works
- Create Login Window Using PAGE
Now, the idea is to hardcode some speech commands like:
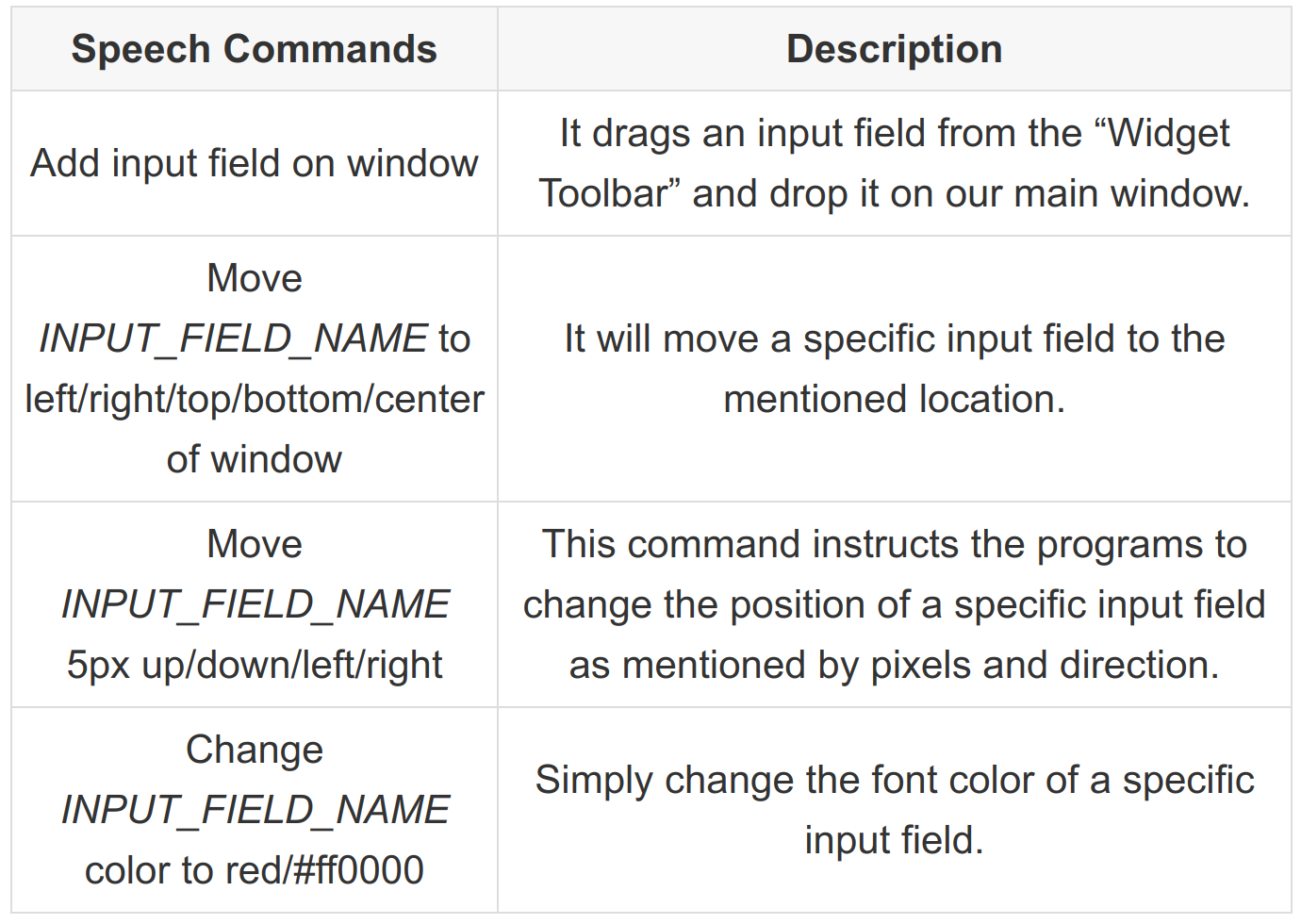
You got the point, right? It’s very simple and straightforward to add more commands like these.
As this is going to be a Minimum Viable Product (MVP). So, it will be completely ok if you have to hardcode many conditional statements (e.g. if…else).
After setting up some basic commands, it’s time to test the code. For now, you can try to build a very basic login form in a window.
The major flexibility of this idea is that it can be implemented for game development, websites, and mobile apps. Even in different programming languages.
2- AI Betting Bot

Betting is an activity where people predict an outcome and if they are right then they receive a reward in return. Now, there are many technological advances that happened in Artificial Intelligence or Machine Learning in the past few years.
For example, you might have heard about programs like AlphaGo Master , AlphaGo Zero , and AlphaZero that can play Go (game) better than any professional human player. You can even get the source code of a similar program called Leela Zero.
The point I want to convey is that AI is getting smarter than us. Meaning that it can predict something better by taking into account all the possibilities and learn from past experiences.
Let’s apply some supervised learning concepts in Python to create an AI Betting Bot. Here are some libraries you need to get started.
- pandas — Data Analysis
- NumPy — Multi-dimensional arrays, matrices, and mathematical functions
- scikit-learn — Machine Learning
- XGBoost — Gradient Boosting
- Matplotlib — Plotting
- seaborn — Statistical Data Visualization
- pickle — Python Object Serialization
At first, you need to select a game (e.g. tennis, football, etc.) for predicting the results. Now search for historical match results data that can be used to train the model.
For example, the data of tennis matches can be downloaded in .csv format from tennis-data.co.uk website .
In case you are not familiar with betting, here’s how it works.
- You want to bet $10 on Roger Federer with an odd of 1.3.
- If he wins, you will receive $10 (actual amount), plus $3 (profit).
- If he loses, you will lose your money (e.g. $10) too.
After training the model, we have to compute the Confidence Level for each prediction, find out the performance of our bot by checking how many times the prediction was right, and finally also keep an eye on Return On Investment (ROI).
Download a similar open-source AI Betting Bot Project by Edouard Thomas.
3- Trading Bot

Trading Bot is very similar to the previous project because it also requires AI for prediction.
Now the question is whether an AI can correctly predict the fluctuation of stock prices?
And, the answer is Yes.
Before getting started, we need some data to develop a trading bot.
These resources from Investopedia might help in training the bot.
After reading both of these articles, you will now have a better understanding of when to buy stocks and when not. This knowledge can easily be transformed into a Python program that automatically makes the decision for us.
You can also take reference from this open-source trading bot called freqtrade . It is built using Python and implements several machine learning algorithms.
4- Iron Man Jarvis (AI based Virtual Assistant)

This idea is taken from the Hollywood movie series Iron Man. The movie revolves around technology, robots, and AI.
Here, the Iron Man has built a virtual assistant for himself using artificial intelligence. The program is known as Jarvis that helps Iron Man in everyday tasks.
Iron Man gives instructions to Jarvis using simple English language and Jarvis responds in English too. It means that our program will need speech recognition as well as text-to-speech functionalities.
I would recommend using these libraries:
For now, you can hardcode the speech commands like:
You can also use Jarvis for tons of other tasks like:
- Set alarm on mobile.
- Continuously check the home security camera and inform in case someone is waiting outside. You can add more features like face detection and recognition. It helps you find out who or how many people are there.
- Open/Close room windows.
- Turn on/off lights.
- Automatically respond to emails.
- Schedule tasks.
Even the founder of Facebook, “Mark Zuckerberg” has built a Jarvis as a side-project.
5- Monitor a Website to Get Informed About an Upcoming Concert of Artist

Songkick is a very popular service that provides information about upcoming concerts. Its API can be used to search for upcoming concerts by:
- Artist
- Location
- Venue
- Date and Time
You can create a Python script that keeps checking a specific concert daily using Songkick’s API. At last, send an email to yourself whenever the concert is available.
Sometimes Songkick even displays buy tickets link on their website. But, this link could go to a different website for different concerts. It means that it is very difficult to automatically purchase tickets even if we make use of web scraping.
Rather, we can simply display the buy tickets link as it is in our application for manual action.
6- Automatically Renew Free Let’s Encrypt SSL Certificates

Let’s Encrypt is a certificate authority that offers free SSL certificates. But, the issue is that this certificate is only valid for 90 days. After 90 days, you have to renew it.
In my opinion, this is a great scenario for automation using Python. We can write some code that automatically renews a website SSL certificate before expiring.
Check out this code on GitHub for inspiration.
7- Recognize Individuals in Crowd

These days, governments had installed surveillance cameras in public places to increase the security of their citizens. Most of these cameras are merely to record video and then the forensic experts have to manually recognize or trace the individual.
What if we create a Python program that recognizes each person in camera in real-time. First of all, we need access to a national ID card database, which we probably don’t have.
So, an easy option is to create a database with your family members’ records.
You can then use a Face Recognition library and connect it with the output of the camera.
8- Contact Tracing

Contact Tracing is a way to identify all those people that come into contact with each other during a specific time period. It is mostly useful in a pandemic like COVID-19 or HIV. Because without any data about who is infected we can’t stop its spread.
Python can be used with a machine learning algorithm called DBSCAN (Density-Based Spatial Clustering of Applications with Noise) for contact tracing.
As this is just a side-project, so we don’t have access to any official data. For now, it is better to generate some realistic test data using Mockaroo.
You may have a look at this article for specific code implementation.
9- Automatically Move Files From One Folder to Another

This is a very basic Python program that keeps monitoring a folder. Whenever a file is added in that folder it checks its type and moves it to a specific folder accordingly.
For example, we can track our downloads folder. Now, when a new file is downloaded, then it will automatically be moved in another folder according to its type.
.exe files are most probably software setups, so move them inside the “software” folder. Whereas, moving images (png, jpg, gif) inside the “images” folder.
This way we can organize different types of files for quick access.
10- Gather Career Path Videos From YouTube
Create an application that accepts the names of skills that we need to learn for a career.
For example, to become a web developer, we need to learn:
- HTML5
- CSS3
- JavaScript
- Backend language (PHP, Node.js, Python, ASP.NET, or Java)
- Bootstrap 4
- WordPress
- Backend Framework (Laravel, Codeigniter, Django, Flask, etc.)
- etc.
After entering the skills, there will be a “Generate Career Path” button. It instructs our program to search YouTube and select relevant videos/playlists according to each skill. In case there are many similar videos for skill then it will select the one with the most views, comments, likes, etc.
The program then groups these videos according to skills and display their thumbnail, title, and link in the GUI.
It will also analyze the duration of each video, aggregate them, and then inform us about how much time it will take to learn this career path.
Now, as a user, we can watch these videos which are ordered in a step by step manner to become a master in this career.
Conclusion
Challenging yourself with unique programming projects keeps you active, enhance your skills, and helps you explore new possibilities.
Some of the project ideas I mentioned above can also be used as your Final Year Project.
It’s time to show your creativity with Python programming language and turn these ideas into something you will proud of.
Thanks for reading!
'Data Analytics(en)' 카테고리의 다른 글
| 7 Awesome Command-Line Tools (0) | 2020.10.28 |
|---|---|
| Master Python Lambda Functions With These 4 Don’ts (0) | 2020.10.27 |
| Change The Way You Write Python Code With One Extra Character (0) | 2020.10.26 |
| Data-Preprocessing with Python (0) | 2020.10.25 |
| Advanced Python: 9 Best Practices to Apply When You Define Classes (0) | 2020.10.24 |














{kind=link}