파이썬 프로그래밍
Python 개발자를위한 10 가지 멋진 프로젝트 아이디어
Python 기술에 도전하는 미친 프로젝트 아이디어

알고 계십니까파이썬로 알려져 있습니다다재다능한 프로그래밍 언어?
예, 그렇습니다모든 단일 프로젝트에서 사용해서는 안됩니다.,
이를 사용하여 데스크톱 응용 프로그램, 게임, 모바일 앱, 웹 사이트 및 시스템 소프트웨어를 만들 수 있습니다. 구현에 가장 적합한 언어이기도합니다.인공 지능과기계 학습알고리즘.
그래서 지난 몇 주 동안유니큐Python 개발자를위한 ue 프로젝트 아이디어. 이 프로젝트 아이디어는이 놀라운 언어에 대한 귀하의 관심을 다시 불러 일으킬 것입니다. 가장 좋은 점은 재미 있지만 도전적인 프로젝트를 통해 Python 프로그래밍 기술을 향상시킬 수 있다는 것입니다.
하나씩 살펴 보겠습니다.
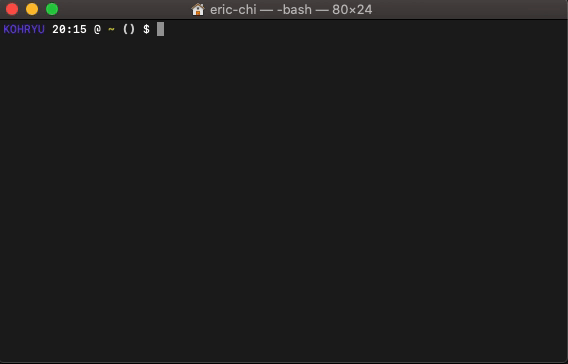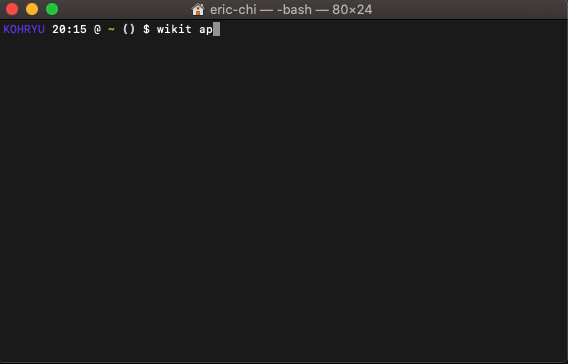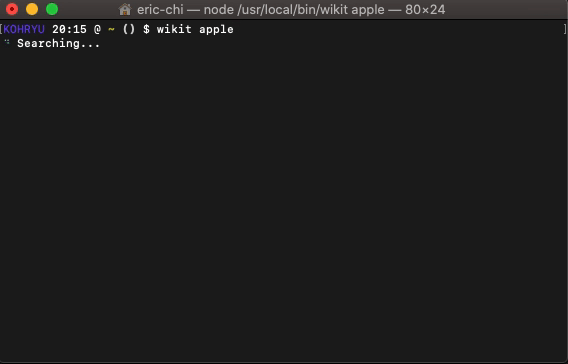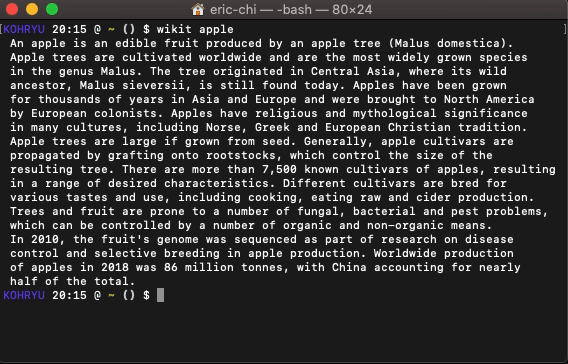
1- 음성 명령을 사용하여 소프트웨어 GUI 만들기

These days, massive progress has been made in the field of desktop application development. You will see many drag & drop GUI builders and speech recognition libraries. So, why not join them together and create a user interface by talking with the computer?
이것은 순전히 새로운 개념이며 몇 가지 연구 끝에 아무도 그것을 시도하지 않았다는 것을 알았습니다. 따라서 아래에 언급 된 것보다 조금 더 어려울 수 있습니다.
다음은 Python을 사용하여이 프로젝트를 시작하기위한 몇 가지 지침입니다. 우선, 다음 패키지가 필요합니다.
이제 아이디어는 다음과 같은 일부 음성 명령을 하드 코딩하는 것입니다.
당신은 요점을 알고 있습니까? 이와 같은 명령을 더 추가하는 것은 매우 간단하고 간단합니다.
이것이 될 것이므로최소 실행 가능 제품 (MVP). 따라서 많은 조건문 (예 : if… else)을 하드 코딩해야한다면 완전히 괜찮을 것입니다.
몇 가지 기본 명령을 설정 한 후에는 코드를 테스트 할 차례입니다. 지금은 창에서 매우 기본적인 로그인 양식을 만들 수 있습니다.
이 아이디어의 가장 큰 유연성은 게임 개발, 웹 사이트 및 모바일 앱에 대해 구현할 수 있다는 것입니다. 다른 프로그래밍 언어에서도.
2- AI 베팅 봇

베팅은 사람들이 결과를 예측하고 옳다면 그 대가로 보상을받는 활동입니다. 이제 지난 몇 년 동안 인공 지능 또는 기계 학습에서 발생한 많은 기술 발전이 있습니다.
예를 들어, 다음과 같은 프로그램에 대해 들어 보셨을 것입니다.AlphaGo 마스터,알파 고 제로, 및AlphaZero재생할 수 있습니다Go (게임)어떤 프로 인간 선수보다 낫습니다. 당신은 심지어 얻을 수 있습니다소스 코드Leela Zero라는 유사한 프로그램의
제가 전하고 싶은 것은 AI가 우리보다 더 똑똑해지고 있다는 것입니다. 모든 가능성을 고려하여 더 나은 것을 예측하고 과거의 경험에서 배울 수 있음을 의미합니다.
Python에서지도 학습 개념을 적용하여 AI Betting Bot을 만들어 보겠습니다. 시작하는 데 필요한 라이브러리는 다음과 같습니다.
- pandas — 데이터 분석
- NumPy — 다차원 배열, 행렬 및 수학 함수
- scikit-learn — 기계 학습
- XGBoost — 그라디언트 부스팅
- Matplotlib — 플로팅
- seaborn — 통계 데이터 시각화
- pickle — 파이썬 객체 직렬화
처음에는 결과를 예측하기 위해 게임 (예 : 테니스, 축구 등)을 선택해야합니다. 이제 모델 학습에 사용할 수있는 이전 일치 결과 데이터를 검색합니다.
예를 들어 테니스 경기의 데이터는 다음 사이트에서 .csv 형식으로 다운로드 할 수 있습니다.tennis-data.co.uk 웹 사이트.
베팅에 익숙하지 않은 경우 방법은 다음과 같습니다.
- $ 10을 베팅하고 싶습니다.로저 페더러1.3의 배당률로.
- 그가 이기면 $ 10 (실제 금액)과 $ 3 (수익)을 받게됩니다.
- 그가지면 당신의 돈 (예 : $ 10)도 잃게됩니다.
모델을 훈련 한 후에는신뢰 수준각 예측에 대해 예측이 옳은 횟수를 확인하여 봇의 성능을 확인하고 마지막으로 주시해야합니다.투자 수익 (ROI).
유사한 오픈 소스 다운로드AI 베팅 봇 프로젝트에두아르 토마스.
3- 트레이딩 봇

Trading Bot은 예측을 위해 AI도 필요하기 때문에 이전 프로젝트와 매우 유사합니다.
이제 질문은 AI가 주가의 변동을 정확하게 예측할 수 있는지 여부입니다.
그리고 대답은 예입니다.
시작하기 전에 거래 봇을 개발하기위한 데이터가 필요합니다.
Investopedia의 이러한 리소스는 봇 교육에 도움이 될 수 있습니다.
이 두 기사를 모두 읽은 후에는 주식을 구매할 때와 구매하지 않을 때를 더 잘 이해할 수 있습니다. 이 지식은 자동으로 결정을 내리는 Python 프로그램으로 쉽게 변환 될 수 있습니다.
이 오픈 소스 거래 봇에서 참조 할 수도 있습니다.freqtrade. Python을 사용하여 빌드되고 여러 기계 학습 알고리즘을 구현합니다.
4- Iron Man Jarvis (AI 기반 가상 도우미)

이 아이디어는 할리우드 영화 시리즈에서 가져온 것입니다.아이언 맨. 영화는 기술, 로봇, AI를 중심으로 전개됩니다.
여기에서 Iron Man은 인공 지능을 사용하여 가상 비서를 구축했습니다. 이 프로그램은자비스아이언 맨의 일상적인 작업을 도와줍니다.
Iron Man은 간단한 영어를 사용하여 Jarvis에게 지침을 제공하고 Jarvis도 영어로 응답합니다. 이는 우리 프로그램이 음성 인식과 텍스트 음성 변환 기능이 필요하다는 것을 의미합니다.
다음 라이브러리를 사용하는 것이 좋습니다.
지금은 다음과 같은 음성 명령을 하드 코딩 할 수 있습니다.
다음과 같은 수많은 다른 작업에 Jarvis를 사용할 수도 있습니다.
- 모바일에서 알람을 설정합니다.
- 지속적으로 홈 보안 카메라를 확인하고 누군가가 밖에서 기다리고있을 경우 알려줍니다. 얼굴 인식 및 인식과 같은 더 많은 기능을 추가 할 수 있습니다. 누가 또는 얼마나 많은 사람들이 있는지 알아내는 데 도움이됩니다.
- 방 창문을 열거 나 닫습니다.
- 조명을 켜거나 끕니다.
- 이메일에 자동으로 응답합니다.
- 작업을 예약합니다.
Facebook의 창립자 인 "Mark Zuckerberg"조차도자비스사이드 프로젝트로.
5- 다가오는 아티스트 콘서트에 대한 정보를 얻기 위해 웹 사이트 모니터링

송킥다가오는 콘서트에 대한 정보를 제공하는 매우 인기있는 서비스입니다. 이것의API다음과 같은 방법으로 예정된 콘서트를 검색하는 데 사용할 수 있습니다.
- 예술가
- 위치
- 장소
- 날짜와 시간
Songkick의 API를 사용하여 매일 특정 콘서트를 계속 확인하는 Python 스크립트를 만들 수 있습니다. 마지막으로 콘서트가 열릴 때마다 자신에게 이메일을 보내십시오.
때때로 Songkick은표를 사다그들의 웹 사이트에 링크. 그러나이 링크는 다른 콘서트를 위해 다른 웹 사이트로 이동할 수 있습니다. 이는 웹 스크래핑을 이용하더라도 자동으로 티켓을 구매하기가 매우 어렵다는 것을 의미합니다.
대신 수동 조치를위한 애플리케이션에있는 그대로 티켓 구매 링크를 표시 할 수 있습니다.
6- 무료 Let ’s Encrypt SSL 인증서 자동 갱신

암호화하자무료 SSL 인증서를 제공하는 인증 기관입니다. 그러나 문제는이 인증서가 90 일 동안 만 유효하다는 것입니다. 90 일 후에는 갱신해야합니다.
제 생각에는 이것은 Python을 사용한 자동화를위한 훌륭한 시나리오입니다. 만료되기 전에 웹 사이트 SSL 인증서를 자동으로 갱신하는 코드를 작성할 수 있습니다.
이것을 확인하십시오GitHub의 코드영감을 위해.
7- 군중 속의 개인 인식

요즘 정부는 시민의 보안을 강화하기 위해 공공 장소에 감시 카메라를 설치했습니다. 이러한 카메라의 대부분은 단순히 비디오를 녹화하기위한 것이므로 법의학 전문가는 개인을 수동으로 인식하거나 추적해야합니다.
카메라에있는 각 사람을 실시간으로 인식하는 Python 프로그램을 만들면 어떨까요? 우선, 우리가 가지고 있지 않은 국가 ID 카드 데이터베이스에 액세스해야합니다.
따라서 쉬운 옵션은 가족 구성원의 기록으로 데이터베이스를 만드는 것입니다.
그런 다음얼굴 인식라이브러리를 만들고 카메라의 출력과 연결합니다.
8- 접촉 추적

연락처 추적은 특정 기간 동안 서로 연락 한 모든 사람을 식별하는 방법입니다. COVID-19 또는 HIV와 같은 전염병에 주로 유용합니다. 감염된 사람에 대한 데이터가 없으면 확산을 막을 수 없기 때문입니다.
Python은 다음과 같은 기계 학습 알고리즘과 함께 사용할 수 있습니다.DBSCAN (노이즈가있는 애플리케이션의 밀도 기반 공간 클러스터링)연락처 추적을 위해.
이것은 부수적 인 프로젝트이므로 공식 데이터에 액세스 할 수 없습니다. 지금은 다음을 사용하여 현실적인 테스트 데이터를 생성하는 것이 좋습니다.모카 루.
당신은 볼 수 있습니다이 기사특정 코드 구현을 위해.
9- 한 폴더에서 다른 폴더로 파일 자동 이동

이것은 폴더를 계속 모니터링하는 매우 기본적인 Python 프로그램입니다. 해당 폴더에 파일이 추가 될 때마다 유형을 확인하고 그에 따라 특정 폴더로 이동합니다.
예를 들어 다운로드 폴더를 추적 할 수 있습니다. 이제 새 파일을 다운로드하면 파일 유형에 따라 자동으로 다른 폴더로 이동합니다.
.exe 파일은 대부분 소프트웨어 설정이므로 "software"폴더로 이동하십시오. 반면,“images”폴더 안에있는 움직이는 이미지 (png, jpg, gif).
이렇게하면 빠른 액세스를 위해 다양한 유형의 파일을 구성 할 수 있습니다.
10- YouTube에서 경력 경로 비디오 수집
경력을 위해 배워야하는 기술의 이름을 받아들이는 응용 프로그램을 만듭니다.
예를 들어 웹 개발자가 되려면 다음을 배워야합니다.
- HTML5
- CSS3
- 자바 스크립트
- 백엔드 언어 (PHP, Node.js, Python, ASP.NET 또는 Java)
- 부트 스트랩 4
- 워드 프레스
- 백엔드 프레임 워크 (Laravel, Codeigniter, Django, Flask 등)
- 기타
스킬을 입력하면"경력 경로 생성"단추. 프로그램에 검색을 지시합니다.유튜브각 기술에 따라 관련 비디오 / 재생 목록을 선택합니다. 스킬에 대한 유사한 동영상이 많은 경우 조회수, 댓글, 좋아요 등이 가장 많은 동영상을 선택합니다.
그런 다음 프로그램은 이러한 비디오를 기술에 따라 그룹화하고 GUI에 썸네일, 제목 및 링크를 표시합니다.
또한 각 비디오의 길이를 분석하고 집계 한 다음이 경력 경로를 배우는 데 걸리는 시간을 알려줍니다.
이제 사용자로서 우리는이 커리어의 마스터가되기 위해 단계적으로 주문되는 이러한 비디오를 볼 수 있습니다.
결론
고유 한 프로그래밍 프로젝트에 도전하면 활동성을 유지하고 기술을 향상 시키며 새로운 가능성을 탐색하는 데 도움이됩니다.
위에서 언급 한 프로젝트 아이디어 중 일부는마지막 해 프로젝트.
Python 프로그래밍 언어로 창의성을 보여주고 이러한 아이디어를 자랑스럽게 생각할 때입니다.
읽어 주셔서 감사합니다!
'Data Analytics(ko)' 카테고리의 다른 글
| 7 Awesome Command-Line Tools -번역 (0) | 2020.10.28 |
|---|---|
| Master Python Lambda Functions With These 4 Don’ts -번역 (0) | 2020.10.27 |
| Change The Way You Write Python Code With One Extra Character -번역 (0) | 2020.10.26 |
| Data-Preprocessing with Python -번역 (0) | 2020.10.25 |
| Advanced Python: 9 Best Practices to Apply When You Define Classes -번역 (0) | 2020.10.24 |














{kind=link}