데이터 수집,데이터 과학
Python 및 R을 사용하여 PDF 파일에서 데이터 추출
Demonstration of parsing PDF files using Python & R API
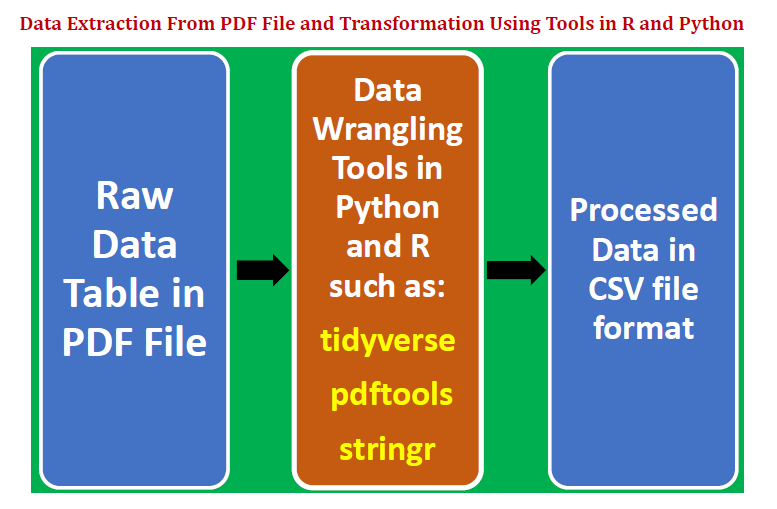
데이터는 추론 분석, 예측 분석 또는 규범 분석과 같은 데이터 과학의 모든 분석에서 핵심입니다. 모델의 예측력은 모델 구축에 사용 된 데이터의 품질에 따라 달라집니다. 데이터는 텍스트, 표, 이미지, 음성 또는 비디오와 같은 다양한 형태로 제공됩니다. 대부분의 경우 분석에 사용되는 데이터는 추가 분석에 적합한 형식으로 렌더링하기 위해 마이닝, 처리 및 변환되어야합니다.
대부분의 분석에 사용되는 가장 일반적인 유형의 데이터 세트는 쉼표로 구분 된 값 (csv) 테이블. 그러나 휴대용 문서 형식 (pdf)파일은 가장 많이 사용되는 파일 형식 중 하나입니다. 모든 데이터 과학자는pdf파일을 만들고 데이터를 "csv”그런 다음 분석 또는 모델 구축에 사용할 수 있습니다.
에서 데이터 복사pdf줄 단위 파일은 너무 지루하며 프로세스 중 인적 오류로 인해 종종 손상 될 수 있습니다. 따라서 데이터를 가져 오는 방법을 이해하는 것이 매우 중요합니다.pdf효율적이고 오류없는 방식으로.
이 기사에서는 데이터 테이블을 추출하는 데 초점을 맞출 것입니다.pdf파일. 텍스트 또는 이미지와 같은 다른 유형의 데이터를 추출하기 위해 유사한 분석을 수행 할 수 있습니다.pdf파일. 이 기사는 pdf 파일에서 숫자 데이터를 추출하는 데 중점을 둡니다. pdf 파일에서 이미지를 추출하기 위해 python에는 다음과 같은 패키지가 있습니다.광산 수레PDF에서 이미지, 텍스트 및 모양을 추출하는 데 사용할 수 있습니다.
데이터 테이블을pdf파일을 추가 분석 및 모델 구축에 적합한 형식으로 변환합니다. 하나는 Python을 사용하고 다른 하나는 R을 사용하는 두 가지 예를 제시합니다.이 기사에서는 다음 사항을 고려합니다.
- 에서 데이터 테이블 추출pdf파일.
- 데이터 랭 글링 및 문자열 처리 기술을 사용하여 데이터를 정리, 변환 및 구조화합니다.
- 깨끗하고 깔끔한 데이터 테이블을csv파일.
- R에서 데이터 랭 글링 및 문자열 처리 패키지를 소개합니다."순수한",“pdftools”, 및"스트링거".
예제 1 : Python을 사용하여 PDF 파일에서 테이블 추출
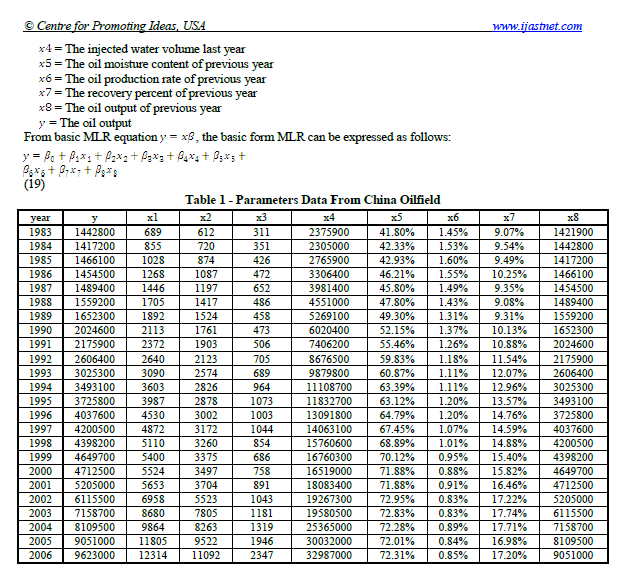
아래 표를 a에서 추출한다고 가정 해 보겠습니다.pdf파일.
— — — — — — — — — — — — — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — — — — — — — — — —
a) 테이블을 복사하여 Excel에 붙여넣고 파일을 table_1_raw.csv로 저장합니다.
데이터는 1 차원 형식으로 저장되며 재구성, 정리 및 변환되어야합니다.
b) 필요한 라이브러리 가져 오기
import pandas as pd
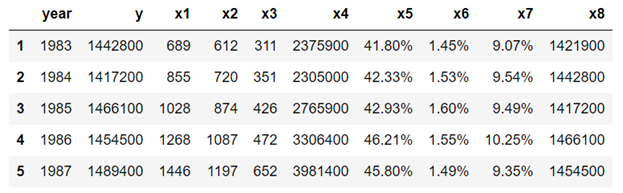
import numpy as npc) 원시 데이터 가져 오기 및 데이터 재구성
df=pd.read_csv("table_1_raw.csv", header=None)df.values.shapedf2=pd.DataFrame(df.values.reshape(25,10))column_names=df2[0:1].values[0]df3=df2[1:]df3.columns = df2[0:1].values[0]df3.head()
d) 문자열 처리 도구를 사용하여 데이터 랭 글링 수행
위의 표에서 알 수 있습니다.x5,x6, 및x7백분율로 표시되므로 백분율 (%) 기호를 제거해야합니다.
df4['x5']=list(map(lambda x: x[:-1], df4['x5'].values))df4['x6']=list(map(lambda x: x[:-1], df4['x6'].values))df4['x7']=list(map(lambda x: x[:-1], df4['x7'].values))
e) 데이터를 숫자 형식으로 변환
열의 열 값은x5,x6, 및x7데이터 유형이 문자열이므로 다음과 같이 숫자 데이터로 변환해야합니다.
df4['x5']=[float(x) for x in df4['x5'].values]df4['x6']=[float(x) for x in df4['x6'].values]df4['x7']=[float(x) for x in df4['x7'].values]
f) 변환 된 데이터의 최종 형식보기
df4.head(n=5)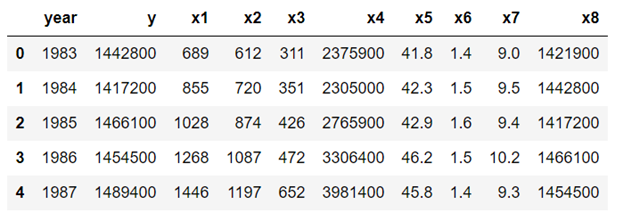
g) 최종 데이터를 csv 파일로 내보내기
df4.to_csv('table_1_final.csv',index=False)예 2 : R을 사용하여 PDF 파일에서 테이블 추출
이 예제는 테이블에서 테이블을 추출하는 방법을 보여줍니다.pdfR에서 데이터 랭 글링 기술을 사용하는 파일입니다.pdf파일 이름trade_report.pdf:
— — — — — — — — — — — — — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — — — — — — — — —
테이블을 추출하고 데이터를 랭 글링 한 다음 추가 분석을 위해 준비된 데이터 프레임 테이블로 변환하려고합니다. 그러면 최종 데이터 테이블을 쉽게 내보내고 "csv”파일. 특히 다음을 수행하고자합니다.
i) 칼럼에생성물, ETC-USD 제품에서 USD를 제거하고 싶습니다.
ii) 분할데이트열을 두 개의 별도 열로, 즉,데이트과시각.
iii) 열에서 USD 제거회비과합계.
이 예제의 데이터 세트와 코드는이 저장소에서 다운로드 할 수 있습니다.https://github.com/bot13956/extract_table_from_pdf_file_using_R.
a) 필요한 라이브러리 가져 오기
library("tidyverse")library("stringr")library("pdftools")
b) 표 추출 및 텍스트 파일로 변환
# define file pathpdf_file <- file.path("C:\\Users\\btayo\\Desktop\\TRADE", "trade_report.pdf")# convert pdf file to text (txt) filetext <- pdf_text(pdf_file)
c) 문자열 처리 도구를 사용하여 데이터를 정리하고 정리하기 위해 데이터를 랭 글링합니다.
tab <- str_split(text, "\n")[[1]][6:31]tab[1] <- tab[1]%>%str_replace("\\.","")
%>%str_replace("\r","")col_names <- str_replace_all(tab[1],"\\s+"," ")
%>%str_replace(" ", "")
%>%str_split(" ")
%>%unlist()col_names <- col_names[-3]col_names[2] <- "Trade_id"col_names <- append(col_names, "Time", 5)col_names <- append(col_names,"sign",9)length(col_names)==11tab <- tab[-1]dat <- data.frame(
x=tab%>%str_replace_all("\\s+"," ")
%>%str_replace_all("\\s*USD","")
%>%str_replace(" ",""),stringsAsFactors = FALSE)data <- dat%>%separate(x,col_names,sep=" ")data<-data%>%mutate(total=paste(data$sign,data$Total,sep=""))
%>%select(-c(sign,Total))names(data)<- names(data)%>%tolower()data$product <- data$product%>%str_replace("-$","")
d) 변환 된 데이터의 최종 형식보기
data%>%head()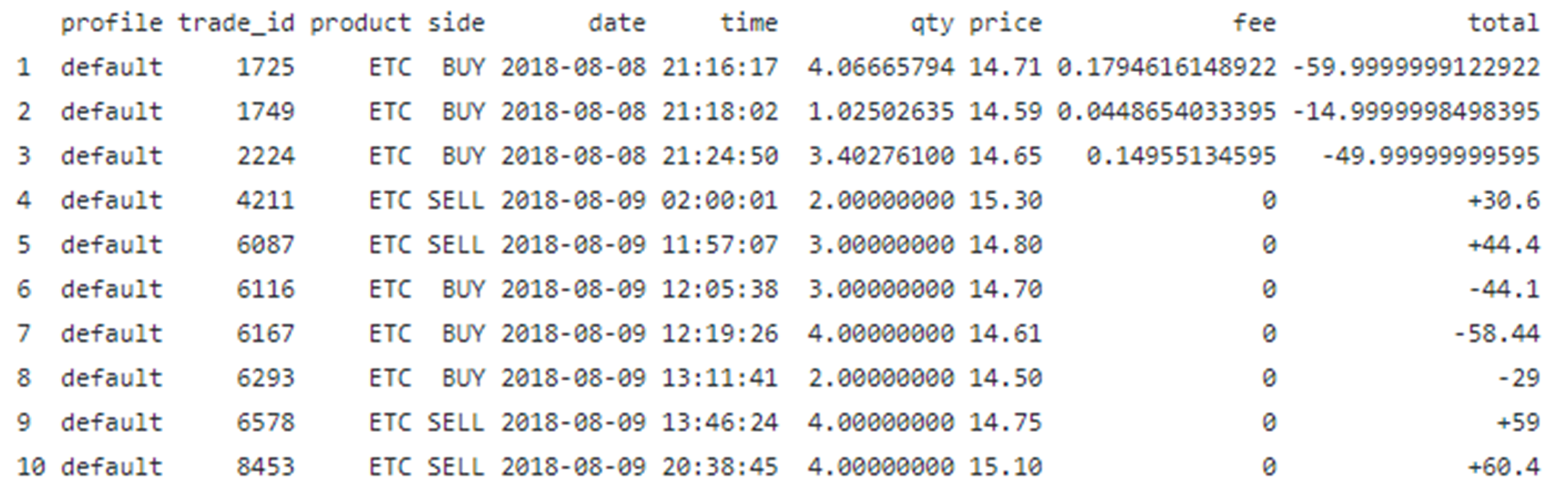
예제 2의 데이터 세트와 코드는이 저장소에서 다운로드 할 수 있습니다.https://github.com/bot13956/extract_table_from_pdf_file_using_R.
요약하면 데이터 테이블을pdf파일. 이후pdf파일은 매우 일반적인 파일 유형이므로 모든 데이터 과학자는 파일에 저장된 데이터를 추출하고 변환하는 기술에 익숙해야합니다.pdf파일.
'Data Analytics(ko)' 카테고리의 다른 글
| No More Basic Plots Please -번역 (0) | 2020.10.05 |
|---|---|
| The Definitive Data Scientist Environment Setup -번역 (0) | 2020.10.03 |
| Advanced Python: Itertools Library — The Gem Of Python Language -번역 (0) | 2020.10.01 |
| Data Visualisation using Pandas and Plotly -번역 (0) | 2020.09.30 |
| Bye-bye Python. Hello Julia!-번역 (0) | 2020.09.29 |