The New Jupyter Book
Jupyter Book extends the notebook idea
2020–08–07 | On the Jupyter blog, Chris Holdgraf announces a rewrite of the Jupyter Book project.
“Jupyter Book is an open source project for building beautiful, publication-quality books, websites, and documents from source material that contains computational content. With this post, we’re happy to announce that Jupyter Book has been re-written from the ground up, making it easier to install, faster to use, and able to create more complex publishing content in your books. It is now supported by the Executable Book Project, an open community that builds open source tools for interactive and executable documents in the Jupyter ecosystem and beyond.”
What does the new Jupyter Book do?
The new version of Jupyter Book will feel very similar. However, it has a lot of new features due to the new Jupyter Book stack underneath (more on that later).
The new Jupyter Book has the following main features (with links to the relevant documentation for each):
✅ Write publication-quality content in markdown
You can write in either Jupyter markdown, or an extended flavor of markdown with publishing features. This includes support for rich syntax such as citations and cross-references, math and equations, and figures.
✅ Write content in Jupyter Notebooks
This allows you to include your code and outputs in your book. You can also write notebooks entirely in markdown to execute when you build your book.
✅ Execute and cache your book’s content
For .ipynb and markdown notebooks, execute code and insert the latest outputs into your book. In addition, cache and re-use outputs to be used later.
✅ Insert notebook outputs into your content
Generate outputs as you build your documentation, and insert them in-line with your content across pages.
✅ Add interactivity to your book
You can toggle cell visibility, include interactive outputs from Jupyter, and connect with online services like Binder.
✅ Generate a variety of outputs
This includes single- and multi-page websites, as well as PDF outputs.
✅ Build books with a simple command-line interface
You can quickly generate your books with one command, like so: jupyter-book build mybook/
These are just a few of the major changes that we’ve made. For a more complete idea of what you can do, check out the Jupyter Book documentation
An enhanced flavor of markdown
The biggest enhancement to Jupyter Book is support for the MyST Markdown language. MyST stands for “Markedly Structured Text”, and is a flavor of markdown that implements all of the features of the Sphinx documentation engine, allowing you to write scientific publications in markdown. It draws inspiration from RMarkdown and the reStructuredText ecosystem of tools. Anything you can do in Sphinx, you can do with MyST as well.
MyST Markdown is a superset of Jupyter Markdown (AKA, CommonMark), meaning that any default markdown in a Jupyter Notebook is valid in Jupyter Book. If you’d like extra features in markdown such as citations, figures, references, etc, then you may include extra MyST Markdown syntax in your content.
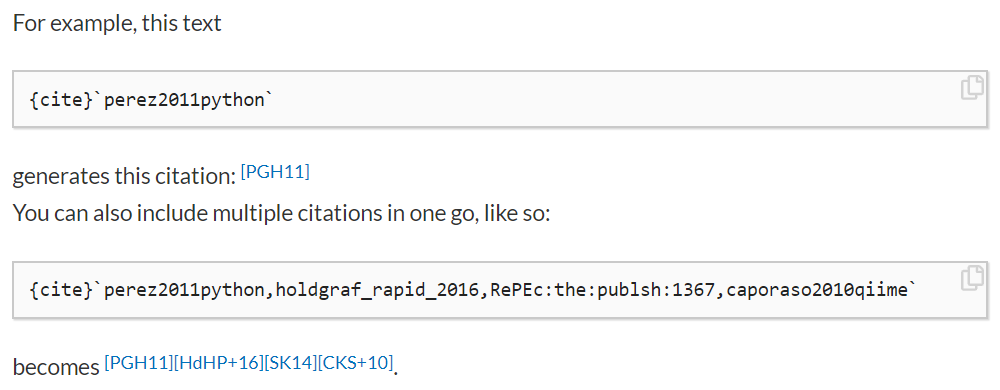
For example, here’s how you can include a citation in the new Jupyter Book:
A smarter build system
While the old version of Jupyter Book used a combination of Python and Jekyll to build your book’s HTML, the new Jupyter Book uses Python all the way through. This means that building the HTML for your book is as simple as:
jupyter-book build mybookname/In addition, the new build system leverages Jupyter Cache to execute notebook content only if the code is updated, and to insert the outputs from the cache at build time. This saves you time by avoiding the need to re-execute code that hasn’t been changed.
jupyter-book command-line interface is used to convert a collection of content into an HTML book. (source: https://blog.jupyter.org/)More book output types
By leveraging Sphinx, Jupyter Book will be able to support more complex outputs than just an HTML website. For example, we are currently prototyping PDF Outputs, both via HTML as well as via LaTeX. This gives Jupyter Book more flexibility to generate the right book for your use case.
You can also run Jupyter Book on individual pages. This means that you can write single-page content (like a scientific article) entirely in Markdown.
A new stack
The biggest change under-the-hood is that Jupyter Book now uses the Sphinx documentation engine instead of Jekyll for building books. By leveraging the Sphinx ecosystem, Jupyter Book can more effectively build on top of community tools, and can contribute components back to the broader community.
Instead of being a single repository, the old Jupyter Book repository has now been separated into several modular tools. Each of these tools can be used on their own in your Sphinx documentation, and they can be coordinated together via Jupyter Book:
- The MyST markdown parser for Sphinx allows you to write fully-featured Sphinx documentation in Markdown.
- MyST-NB is an
.ipynbparser for Sphinx that allows you to use MyST Markdown in your notebooks. It also provides tools for execution, cacheing, and variable insertion of Jupyter Notebooks in Sphinx. - The Sphinx Book Theme is a beautiful book-like theme for Sphinx, build on top of the PyData Sphinx Theme.
- Jupyter Cache allows you to execute a collection of notebooks and store their outputs in a hashed database. This lets you cache your notebook’s output without including it in the
.ipynbfile itself. - Sphinx-Thebe converts your “static” HTML page into an interactive page with code cells that are run remotely by a Binder kernel.
- Finally, Jupyter Book also supports a growing collection of Sphinx extensions, such as sphinx-copybutton, sphinx-togglebutton, sphinx-comments, and sphinx-panels.
What next?
Jupyter Book and its related projects will continue to be developed as a part of the Executable Book Project, a community that builds open source tools for high-quality scientific publications from computational content in the Jupyter ecosystem and beyond.
Overview and installation
Install the command-line interface
First off, make sure you have the CLI installed so that you can work with Jupyter Book. The Jupyter-Book CLI allows you to build and control your Jupyter Book. You can install it via pip with the following command:
pip install -U jupyter-bookThe book building process
Building a Jupyter Book broadly consists of two steps:
Put your book content in a folder or a file. Jupyter Book needs the following pieces in order to build your book:
- Your content file(s) (the pages of your book) in either markdown or Jupyter Notebooks.
- A Table of Contents
YAMLfile (_toc.yml) that defines the structure of your book. Mandatory when building a folder. - (optional) A configuration file (
_config.yml) to control the behavior of Jupyter Book.
Build your book. Using Jupyter Book’s command-line interface you can convert your pages into either an HTML or a PDF book.
Host your book’s HTML online. Once your book’s HTML is built, you can host it online as a public website. See Publish your book online for more information.
Create a template Jupyter Book
We’ll use a small template book to show what kinds of files you might put inside your own. To create a new Jupyter Book, type the following at the command-line:
jupyter-book create mybooknameA new book will be created at the path that you’ve given (in this case, mybookname/).
If you would like to quickly generate a basic Table of Contents YAML file, run the following command:
jupyter-book toc mybookname/And it will generate a TOC for you. Note that there must be at least one content file in each folder in order for any sub-folders to be parsed.
Inspecting your book’s contents
Let’s take a quick look at some important files in the demo book you created:
mybookname/
├── _config.yml
├── _toc.yml
├── content.md
├── intro.md
├── markdown.md
├── notebooks.ipynb
└── references.bibHere’s a quick rundown of the files you can modify for yourself, and that ultimately make up your book.
Book configuration
All of the configuration for your book is in the following file:
mybookname/
├── _config.ymlYou can define metadata for your book (such as its title), add a book logo, turn on different “interactive” buttons (such as a Binder button for pages built from a Jupyter Notebook), and more.
Table of Contents
Jupyter Book uses your Table of Contents to define the structure of your book. For example, your chapters, sub-chapters, etc.
The Table of Contents lives at this location:
mybookname/
├── _toc.ymlThis is a YAML file with a collection of pages, each one linking to a file in your content/ folder. Here’s an example of a few pages defined in toc.yml.
- file: features/features
sections:
- file: features/markdown
- file: features/notebooksThe top-most level of your TOC file are book chapters. Above, this is the “Features” page. Note that in this case the title of the page is not explicitly specified but is inferred from the source files. This behavior is controlled by the page_titles setting in _config.yml (see Files for more details). Each chapter can have several sections (defined in sections:) and each section can have several sub-sections. For more information about how section structure maps onto book structure, see How headers and sections map onto to book structure.
Each item in the _toc.yml file points to a single file. The links should be relative to your book’s folder and with no extension.
For example, in the example above there is a file in mybookname/content/notebooks.ipynb. The TOC entry that points to this file is here:
- file: features/notebooksBook content
The markdown and ipynb files in your folder is your book’s content. Some content files for the demo book are shown below:
mybookname/
...
├── content.md
└── notebooks.ipynbNote that the content files are either Jupyter Notebooks or Markdown files. These are the files that define “sections” in your book.
You can store these files in whatever collection of folders you’d like, note that the structure of your book when it is built will depend solely on the order of items in your _toc.yml file (see below section)
Book bibliography for citations
If you’d like to build a bibliography for your book, you can do so by including the following file:
mybookname/
└── references.bibThis BiBTex file can be used to insert citations into your book’s pages. For more information, see Citations and cross-references.
Next step: build your book
Now that you’ve got a Jupyter Book folder structure, we can create the HTML (or PDF) for each of your book’s pages.
Build your book
Once you’ve added content and configured your book, it’s time to build outputs for your book. We’ll use the jupyter-book build command-line tool for this.
Currently, there are two kinds of supported outputs: an HTML website for your book, and a PDF that contains all of the pages of your book that is built from the book HTML.
Prerequisites
In order to build the HTML for each page, you should have followed the steps in creating your Jupyter Book structure. You should have a collection of notebook/markdown files in your mybookname/ folder, a _toc.yml file that defines the structure of your book, and any configuration you’d like in the _config.yml file.
Build your book’s HTML
Now that your book’s content is in your book folder and you’ve defined your book’s structure in _toc.yml, you can build the HTML for your book.
Note: HTML is the default builder.
Do so by running the following command:
jupyter-book build mybookname/This will generate a fully-functioning HTML site using a static site generator. The site will be placed in the _build/html folder. You can then open the pages in the site by entering that folder and opening the html files with your web browser.
Note: You can also use the short-hand jb for jupyter-book. E.g.,: jb build mybookname/.
Build a standalone page
Sometimes you’d like to build a single page of content rather than an entire book. For example, if you’d like to generate a web-friendly HTML page from a Jupyter Notebook for a report or publication.
You can generate a standalone HTML file for a single page of the Jupyter Book using the same command :
jupyter-book build path/to/mypage.ipynbThis will execute your content and output the proper HTML in a _build/html folder.
Your page will be called mypage.html. This will work for any content source file that is supported by Jupyter Book.
Note: Users should note that building single pages in the context of a larger project, can trigger warnings and incomplete links. For example, building docs/start/overview.md will issue a bunch of unknown document,term not in glossary, and undefined links warnings.
Page caching
By default, Jupyter Book will only build the HTML for pages that have been updated since the last time you built the book. This helps reduce the amount of unnecessary time needed to build your book. If you’d like to force Jupyter Book to re-build a particular page, you can either edit the corresponding file in your book’s folder, or delete that page’s HTML in the _build/html folder.
Local preview
To preview your book, you can open the generated HTML files in your browser. Either double-click the html file in your local folder, or enter the absolute path to the file in your browser navigation bar adding file:// at the beginning (e.g. file://Users/my_path_to_book/_build/index.html).
Next step: publish your book
Now that you’ve created the HTML for your book, it’s time to publish it online.
Publish your book online
Once you’ve built the HTML for your book, you can host it online. The best way to do this is with a service that hosts static websites (because that’s what you have just created with Jupyter Book). There are many options for doing this, and these sections cover some of the more popular ones.
Create an online repository for your book
Regardless of the approach you use for publishing your book online, it will require you to host your book’s content in an online repository such as GitHub. This section describes one approach you can use to create your own GitHub repository and add your book’s content to it.
- First, log-in to GitHub, then go to the “create a new repository” page:https://github.com/new
- Next, give your online repository a name and a description. Make your repository public and do not initialize with a README file, then click “Create repository”.
- Now, clone the (currently empty) online repository to a location on your local computer. You can do this via the command line with:
git clone https://github.com/<my-org>/<my-repository-name>4. Copy all of your book files and folders into this newly cloned repository. For example, if you created your book locally with jupyter-book create mylocalbook and your new repository is called myonlinebook, you could do this via the command line with:
cp -r mylocalbook/* myonlinebook/5. Now you need to sync your local and remote (i.e., online) repositories. You can do this with the following commands:
cd myonlinebook
git add ./*
git commit -m "adding my first book!"
git pushThanks so much for your interest in my post!
If it was useful for you, please remember to “Clap” 👏 it so other people can also benefit from it.
If you have any suggestions or questions, please leave a comment!
Recommended Articles
- Learn Python & ML with Kaggle
- GitHub Launches Codespaces
- Netflix’s Polynote
- The List of Top 10 lists
- Most popular Python libraries
- Top Data Science Courses & Certification for 2020
- Influencers in AI to follow
- Data Science Programming Languages
- Examples of Artificial Intelligence
- What the BigTech Knows… about You
- Lemonade and the power of Artificial Intelligence
- Ideas for Data Science Projects
- Build a Instagram BOT
- TensorFlow Courses
- How to start TensorFlow
Source:
'Data Analytics(en)' 카테고리의 다른 글
| Bye-bye Python. Hello Julia! (0) | 2020.09.29 |
|---|---|
| Python Lambda Expressions in Data Science (0) | 2020.09.29 |
| Bringing the best out of Jupyter Notebooks for Data Science (0) | 2020.09.28 |
| Please Stop Doing These 5 Things in Pandas (0) | 2020.09.27 |
| Interactive spreadsheets in Jupyter (0) | 2020.09.26 |