Scikit-Learn (Python) : 데이터 과학자를위한 6 가지 유용한 트릭
scikit-learn (sklearn)을 사용하여 Python에서 기계 학습 모델을 개선하는 방법

Scikit-learn (sklearn)강력한 오픈 소스입니다기계 학습 라이브러리Python 프로그래밍 언어 위에 구축되었습니다. 이 라이브러리에는 다양한 분류, 회귀 및 클러스터링 알고리즘을 포함하여 기계 학습 및 통계 모델링을위한 많은 효율적인 도구가 포함되어 있습니다.
이 기사에서는 scikit-learn 라이브러리와 관련된 6 가지 트릭을 보여 주어 특정 프로그래밍 방식을 좀 더 쉽게 할 수 있습니다.
1. 임의 더미 데이터 생성
임의의 '더미'데이터를 생성하기 위해make_classification ()의 경우 기능분류 데이터, 및make_regression ()의 경우 기능회귀 데이터. 이것은 디버깅 할 때나 (작은) 임의의 데이터 세트에서 특정 작업을 시도하려는 경우에 매우 유용합니다.
아래에서는 4 개의 특성 (X에 있음)과 클래스 레이블 (y에 있음)로 구성된 10 개의 분류 데이터 포인트를 생성합니다. 여기서 데이터 포인트는 네거티브 클래스 (0) 또는 포지티브 클래스 (1)에 속합니다.
from sklearn.datasets import make_classification
import pandas as pdX, y = make_classification(n_samples=10, n_features=4, n_classes=2, random_state=123)
여기에서 X는 생성 된 데이터 포인트에 대한 4 개의 특성 열로 구성됩니다.
pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])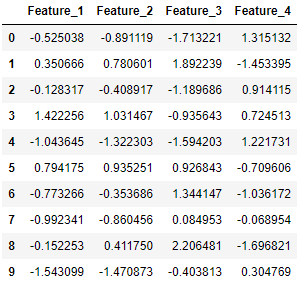
그리고 y에는 각 데이터 요소의 해당 레이블이 포함됩니다.
pd.DataFrame(y, columns=['Label'])2. 결 측값 대치
Scikit-learn은돌리다누락 된 값. 여기에서는 두 가지 접근 방식을 고려합니다. 그만큼SimpleImputer클래스는 결 측값을 대치하기위한 기본 전략을 제공합니다 (예 : 평균 또는 중앙값을 통해). 보다 정교한 접근 방식KNNImputer클래스는 다음을 사용하여 결 측값을 채우기위한 대치를 제공합니다.K- 최근 접 이웃접근하다. 각 누락 된 값은n_neighbors특정 기능에 대한 값이있는 최근 접 이웃. 이웃 값은 균일하게 평균화되거나 각 이웃까지의 거리에 따라 가중치가 부여됩니다.
아래에서는 두 대치 방법을 사용하는 예제 응용 프로그램을 보여줍니다.
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import SimpleImputer, KNNImputer
from sklearn.datasets import make_classification
import pandas as pdX, y = make_classification(n_samples=5, n_features=4, n_classes=2, random_state=123)
X = pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])print(X.iloc[1,2])
>>> 2.21298305
X [1, 2]를 누락 된 값으로 변환합니다.
X.iloc[1, 2] = float('NaN')X

먼저 우리는단순 전가:
imputer_simple = SimpleImputer()
pd.DataFrame(imputer_simple.fit_transform(X))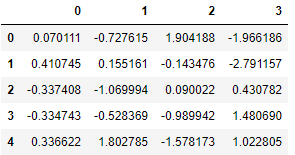
결과 값-0.143476.
다음으로 우리는KNN 입력, 2 개의 가장 가까운 이웃이 고려되고 이웃에 균일 한 가중치가 부여됩니다.
imputer_KNN = KNNImputer(n_neighbors=2, weights="uniform")pd.DataFrame(imputer_KNN.fit_transform(X))
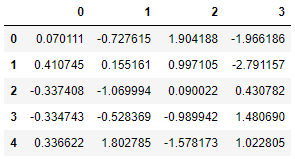
결과 값0.997105(= 0.5 * (1.904188 + 0.090022)).
3. 파이프 라인을 사용하여 여러 단계를 함께 연결
그만큼관로scikit-learn의 도구는 기계 학습 모델을 단순화하는 데 매우 유용합니다. 파이프 라인을 사용하여 여러 단계를 하나로 연결하여 데이터가 고정 된 일련의 단계를 거치도록 할 수 있습니다. 따라서 모든 단계를 개별적으로 호출하는 대신 파이프 라인은 모든 단계를 하나의 시스템으로 연결합니다. 이러한 파이프 라인을 생성하기 위해 우리는make_pipeline함수.
아래에는 파이프 라인이 누락 된 값 (있는 경우)을 대치하는 대치 자와 로지스틱 회귀 분류기로 구성된 간단한 예가 나와 있습니다.
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.datasets import make_classification
import pandas as pdX, y = make_classification(n_samples=25, n_features=4, n_classes=2, random_state=123)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
imputer = SimpleImputer()
clf = LogisticRegression()
pipe = make_pipeline(imputer, clf)
이제 파이프 라인을 사용하여 훈련 데이터를 맞추고 테스트 데이터를 예측할 수 있습니다. 먼저 훈련 데이터가 대치되어 로지스틱 회귀 분류기를 사용하여 훈련을 시작합니다. 그런 다음 테스트 데이터의 클래스를 예측할 수 있습니다.
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)pd.DataFrame({'Prediction': y_pred, 'True': y_test})
4. joblib를 사용하여 파이프 라인 모델 저장
scikit-learn을 통해 생성 된 파이프 라인 모델은 다음을 사용하여 쉽게 저장할 수 있습니다.joblib. 모델에 큰 데이터 배열이 포함 된 경우 각 배열은 별도의 파일에 저장됩니다. 로컬에 저장되면 새 응용 프로그램에서 사용할 모델을 쉽게로드 (또는 복원) 할 수 있습니다.
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.datasets import make_classification
import joblibX, y = make_classification(n_samples=20, n_features=4, n_classes=2, random_state=123)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
imputer = SimpleImputer()
clf = LogisticRegression()
pipe = make_pipeline(imputer, clf)
pipe.fit(X_train, y_train)joblib.dump(pipe, 'pipe.joblib')
이제 피팅 된 파이프 라인 모델은 다음을 통해 컴퓨터에 저장 (덤프)됩니다.joblib.dump. 이 모델은joblib.load, 그리고 나중에 평소와 같이 적용 할 수 있습니다.
new_pipe = joblib.load('.../pipe.joblib')new_pipe.predict(X_test)
5. 혼동 행렬 플로팅
ㅏ혼동 행렬테스트 데이터 세트에 대한 분류기의 성능을 설명하는 데 사용되는 테이블입니다. 여기서 우리는이진 분류 문제즉, 관측 값이 속할 수있는 두 가지 가능한 클래스가 있습니다. "예"(1) 및 "아니요"(0).
예제 이진 분류 문제를 만들고 다음을 사용하여 해당 정오 행렬을 표시해 보겠습니다.plot_confusion_matrix함수:
from sklearn.model_selection import train_test_split
from sklearn.metrics import plot_confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classificationX, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=123)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
clf = LogisticRegression()
clf.fit(X_train, y_train)
confmat = plot_confusion_matrix(clf, X_test, y_test, cmap="Blues")
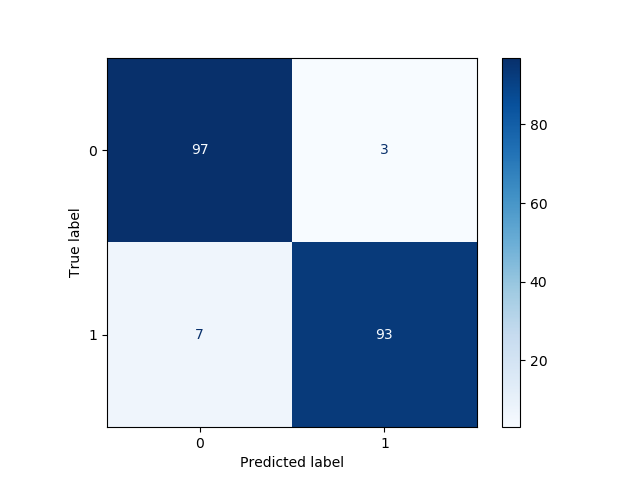
여기에있는 혼동 행렬을 통해 멋진 방식으로 시각화했습니다.
- 93참 양성 (TP);
- 97참 음성 (TN);
- 삼거짓 양성 (FP);
- 7거짓 음성 (FN).
따라서 우리는 (93 + 97) / 200 = 95 %의 정확도 점수에 도달했습니다.
6. 의사 결정 트리 시각화
가장 잘 알려진 분류 알고리즘 중 하나는의사 결정 트리, 특징 매우 직관적 인 나무 모양의 시각화. 의사 결정 트리의 아이디어는 설명 기능을 기반으로 데이터를 더 작은 영역으로 분할하는 것입니다. 그런 다음 테스트 관찰이 속한 지역에서 훈련 관찰 중 가장 일반적으로 발생하는 클래스는 예측입니다. 데이터가 지역으로 분할되는 방법을 결정하려면 다음을 적용해야합니다.분할 측정각 기능의 관련성과 중요성을 결정합니다. 잘 알려진 분할 측정으로는 정보 이득, 지니 지수 및 교차 엔트로피가 있습니다.
아래에서는 사용 방법에 대한 예를 보여줍니다.plot_treescikit-learn의 기능 :
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=50, n_features=4, n_classes=2, random_state=123)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)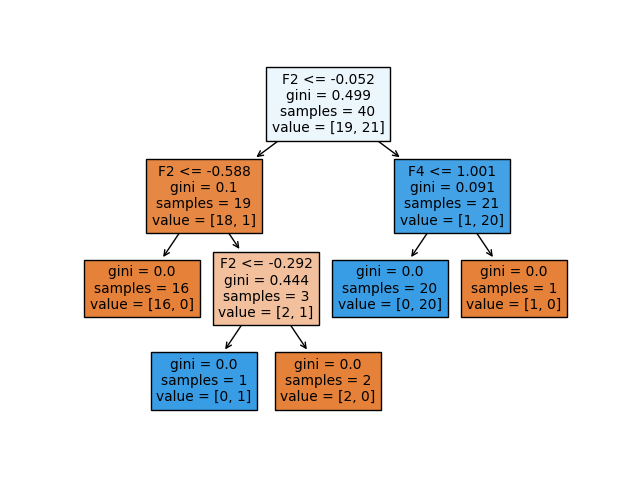
이 예에서는 네거티브 클래스 (0) 또는 포지티브 클래스 (1)에 속하는 40 개의 훈련 관찰에 대한 의사 결정 트리를 피팅하고 있습니다.이진 분류 문제. 트리에는 두 가지 종류의 노드가 있습니다.내부 노드(예측 자 공간이 더 분할 된 노드) 또는터미널 노드(종료점). 두 노드를 연결하는 트리의 세그먼트를가지.
의사 결정 트리의 각 노드에 대해 제공되는 정보를 자세히 살펴 보겠습니다.
- 그만큼분할 기준 used in the particular node is shown as e.g. ‘F2 <= -0.052’. This means that every data point that satisfies the condition that the value of the second feature is below -0.052 belongs to the newly formed region to the left, and the data points that do not satisfy the condition belong to the region to the right of the internal node.
- 그만큼지니 지수여기서 분할 측정으로 사용됩니다. 지니 지수 (불결)는 특정 요소가 무작위로 선택되었을 때 잘못 분류되는 정도 또는 확률을 측정합니다.
- 노드의 '샘플'은 특정 노드에서 발견 된 훈련 관찰의 수를 나타냅니다.
- 노드의 '값'은 각각 네거티브 클래스 (0)와 포지티브 클래스 (1)에서 찾은 훈련 관찰의 수를 나타냅니다. 따라서 value = [19,21]은 19 개의 관측치가 네거티브 클래스에 속하고 21 개의 관측치가 해당 특정 노드의 포지티브 클래스에 속함을 의미합니다.
결론
이 기사에서는 sklearn에서 기계 학습 모델을 개선하기위한 6 가지 유용한 scikit-learn 트릭을 다뤘습니다. 이 트릭이 어떤 식 으로든 도움이 되었기를 바랍니다. scikit-learn 라이브러리를 사용할 때 다음 프로젝트에서 행운을 빕니다!
레벨 업 코딩
커뮤니티의 일원이되어 주셔서 감사합니다!YouTube 채널 구독또는 가입Skilled.dev 코딩 인터뷰 과정.
'Data Analytics(ko)' 카테고리의 다른 글
| 🔝Top 29 Useful Python Snippets 🔝 That Save You Time -번역 (0) | 2020.10.08 |
|---|---|
| You are telling people that you are a Python beginner if you ask this question. -번역 (0) | 2020.10.07 |
| New Features in Python 3.9 -번역 (0) | 2020.10.05 |
| No More Basic Plots Please -번역 (0) | 2020.10.05 |
| The Definitive Data Scientist Environment Setup -번역 (0) | 2020.10.03 |