Big Data Pipeline Recipe
Introduction
If you are starting with Big Data it is common to feel overwhelmed by the large number of tools, frameworks and options to choose from. In this article, I will try to summarize the ingredients and the basic recipe to get you started in your Big Data journey. My goal is to categorize the different tools and try to explain the purpose of each tool and how it fits within the ecosystem.
First let’s review some considerations and to check if you really have a Big Data problem. I will focus on open source solutions that can be deployed on-prem. Cloud providers provide several solutions for your data needs and I will slightly mention them. If you are running in the cloud, you should really check what options are available to you and compare to the open source solutions looking at cost, operability, manageability, monitoring and time to market dimensions.
Data Considerations
(If you have experience with big data, skip to the next section…)
Big Data is complex, do not jump into it unless you absolutely have to. To get insights, start small, maybe use Elastic Search and Prometheus/Grafana to start collecting information and create dashboards to get information about your business. As your data expands, these tools may not be good enough or too expensive to maintain. This is when you should start considering a data lake or data warehouse; and switch your mind set to start thinking big.
Check the volume of your data, how much do you have and how long do you need to store for. Check the temperature! of the data, it loses value over time, so how long do you need to store the data for? how many storage layers(hot/warm/cold) do you need? can you archive or delete data?
Other questions you need to ask yourself are: What type of data are your storing? which formats do you use? do you have any legal obligations? how fast do you need to ingest the data? how fast do you need the data available for querying? What type of queries are you expecting? OLTP or OLAP? What are your infrastructure limitations? What type is your data? Relational? Graph? Document? Do you have an schema to enforce?
I could write several articles about this, it is very important that you understand your data, set boundaries, requirements, obligations, etc in order for this recipe to work.
Data volume is key, if you deal with billions of events per day or massive data sets, you need to apply Big Data principles to your pipeline. However, there is not a single boundary that separates “small” from “big” data and other aspects such as the velocity, your team organization, the size of the company, the type of analysis required, the infrastructure or the business goals will impact your big data journey. Let’s review some of them…
OLTP vs OLAP
Several years ago, businesses used to have online applications backed by a relational database which was used to store users and other structured data(OLTP). Overnight, this data was archived using complex jobs into a data warehouse which was optimized for data analysis and business intelligence(OLAP). Historical data was copied to the data warehouse and used to generate reports which were used to make business decisions.
Data Warehouse vs Data Lake
As data grew, data warehouses became expensive and difficult to manage. Also, companies started to store and process unstructured data such as images or logs. With Big Data, companies started to create data lakes to centralize their structured and unstructured data creating a single repository with all the data.
In short, a data lake it’s just a set of computer nodes that store data in a HA file system and a set of tools to process and get insights from the data. Based on Map Reduce a huge ecosystem of tools such Spark were created to process any type of data using commodity hardware which was more cost effective.The idea is that you can process and store the data in cheap hardware and then query the stored files directly without using a database but relying on file formats and external schemas which we will discuss later. Hadoop uses the HDFS file system to store the data in a cost effective manner.
For OLTP, in recent years, there was a shift towards NoSQL, using databases such MongoDB or Cassandra which could scale beyond the limitations of SQL databases. However, recent databases can handle large amounts of data and can be used for both , OLTP and OLAP, and do this at a low cost for both stream and batch processing; even transactional databases such as YugaByteDB can handle huge amounts of data. Big organizations with many systems, applications, sources and types of data will need a data warehouse and/or data lake to meet their analytical needs, but if your company doesn’t have too many information channels and/or you run in the cloud, a single massive database could suffice simplifying your architecture and drastically reducing costs.
Hadoop or No Hadoop
Since its release in 2006, Hadoop has been the main reference in the Big Data world. Based on the MapReduce programming model, it allowed to process large amounts of data using a simple programming model. The ecosystem grew exponentially over the years creating a rich ecosystem to deal with any use case.
Recently, there has been some criticism of the Hadoop Ecosystem and it is clear that the use has been decreasing over the last couple of years. New OLAP engines capable of ingesting and query with ultra low latency using their own data formats have been replacing some of the most common query engines in Hadoop; but the biggest impact is the increase of the number of Serverless Analytics solutions released by cloud providers where you can perform any Big Data task without managing any infrastructure.
Given the size of the Hadoop ecosystem and the huge user base, it seems to be far from dead and many of the newer solutions have no other choice than create compatible APIs and integrations with the Hadoop Ecosystem. Although HDFS is at the core of the ecosystem, it is now only used on-prem since cloud providers have built cheaper and better deep storage systems such S3 or GCS. Cloud providers also provide managed Hadoop clusters out of the box. So it seems, Hadoop is still alive and kicking but you should keep in mind that there are other newer alternatives before you start building your Hadoop ecosystem. In this article, I will try to mention which tools are part of the Hadoop ecosystem, which ones are compatible with it and which ones are not part of the Hadoop ecosystem.
Batch vs Streaming
Based on your analysis of your data temperature, you need to decide if you need real time streaming, batch processing or in many cases, both.
In a perfect world you would get all your insights from live data in real time, performing window based aggregations. However, for some use cases this is not possible and for others it is not cost effective; this is why many companies use both batch and stream processing. You should check your business needs and decide which method suits you better. For example, if you just need to create some reports, batch processing should be enough. Batch is simpler and cheaper.
The latest processing engines such Apache Flink or Apache Beam, also known as the 4th generation of big data engines, provide a unified programming model for batch and streaming data where batch is just stream processing done every 24 hours. This simplifies the programming model.
A common pattern is to have streaming data for time critical insights like credit card fraud and batch for reporting and analytics. Newer OLAP engines allow to query both in an unified way.
ETL vs ELT
Depending on your use case, you may want to transform the data on load or on read. ELT means that you can execute queries that transform and aggregate data as part of the query, this is possible to do using SQL where you can apply functions, filter data, rename columns, create views, etc. This is possible with Big Data OLAP engines which provide a way to query real time and batch in an ELT fashion. The other option, is to transform the data on load(ETL) but note that doing joins and aggregations during processing it’s not a trivial task. In general, data warehouses use ETL since they tend to require a fixed schema (star or snowflake) whereas data lakes are more flexible and can do ELT and schema on read.
Each method has its own advantages and drawbacks. In short, transformations and aggregation on read are slower but provide more flexibility. If your queries are slow, you may need to pre join or aggregate during processing phase. OLAP engines discussed later, can perform pre aggregations during ingestion.
Team Structure and methodology
Finally, your company policies, organization, methodologies, infrastructure, team structure and skills play a major role in your Big Data decisions. For example, you may have a data problem that requires you to create a pipeline but you don’t have to deal with huge amount of data, in this case you could write a stream application where you perform the ingestion, enrichment and transformation in a single pipeline which is easier; but if your company already has a data lake you may want to use the existing platform, which is something you wouldn’t build from scratch.
Another example is ETL vs ELT. Developers tend to build ETL systems where the data is ready to query in a simple format, so non technical employees can build dashboards and get insights. However, if you have a strong data analyst team and a small developer team, you may prefer ELT approach where developers just focus on ingestion; and data analysts write complex queries to transform and aggregate data. This shows how important it is to consider your team structure and skills in your big data journey.
It is recommended to have a diverse team with different skills and backgrounds working together since data is a cross functional aspect across the whole organization. Data lakes are extremely good at enabling easy collaboration while maintaining data governance and security.
Ingredients
After reviewing several aspects of the Big Data world, let’s see what are the basic ingredients.
Data (Storage)
The first thing you need is a place to store all your data. Unfortunately, there is not a single product to fit your needs that’s why you need to choose the right storage based on your use cases.
For real time data ingestion, it is common to use an append log to store the real time events, the most famous engine is Kafka. An alternative is Apache Pulsar. Both, provide streaming capabilities but also storage for your events. This is usually short term storage for hot data(remember about data temperature!) since it is not cost efficient. There are other tools such Apache NiFi used to ingest data which have its own storage. Eventually, from the append log the data is transferred to another storage that could be a database or a file system.
Massive Databases
Hadoop HDFS is the most common format for data lakes, however; large scale databases can be used as a back end for your data pipeline instead of a file system; check my previous article on Massive Scale Databases for more information. In summary, databases such Cassandra, YugaByteDB or BigTable can hold and process large amounts of data much faster than a data lake can but not as cheap; however, the price gap between a data lake file system and a database is getting smaller and smaller each year; this is something that you need to consider as part of your Hadoop/NoHadoop decision. More and more companies are now choosing a big data database instead of a data lake for their data needs and using deep storage file system just for archival.
To summarize the databases and storage options outside of the Hadoop ecosystem to consider are:
- Cassandra: NoSQL database that can store large amounts of data, provides eventual consistency and many configuration options. Great for OLTP but can be used for OLAP with pre computed aggregations (not flexible). An alternative is ScyllaDB which is much faster and better for OLAP (advanced scheduler)
- YugaByteDB: Massive scale Relational Database that can handle global transactions. Your best option for relational data.
- MongoDB: Powerful document based NoSQL database, can be used for ingestion(temp storage) or as a fast data layer for your dashboards
- InfluxDB for time series data.
- Prometheus for monitoring data.
- ElasticSearch: Distributed inverted index that can store large amounts of data. Sometimes ignored by many or just used for log storage, ElasticSearch can be used for a wide range of use cases including OLAP analysis, machine learning, log storage, unstructured data storage and much more. Definitely a tool to have in your Big Data ecosystem.
Remember the differences between SQL and NoSQL, in the NoSQL world, you do not model data, you model your queries.
Hadoop Databases
HBase is the most popular data base inside the Hadoop ecosystem. It can hold large amount of data in a columnar format. It is based on BigTable.
File Systems (Deep Storage)
For data lakes, in the Hadoop ecosystem, HDFS file system is used. However, most cloud providers have replaced it with their own deep storage system such S3 or GCS.
These file systems or deep storage systems are cheaper than data bases but just provide basic storage and do not provide strong ACID guarantees.
You will need to choose the right storage for your use case based on your needs and budget. For example, you may use a database for ingestion if you budget permit and then once data is transformed, store it in your data lake for OLAP analysis. Or you may store everything in deep storage but a small subset of hot data in a fast storage system such as a relational database.
File Formats
Another important decision if you use a HDFS is what format you will use to store your files. Note that deep storage systems store the data as files and different file formats and compression algorithms provide benefits for certain use cases. How you store the data in your data lake is critical and you need to consider the format, compression and especially how you partition your data.
The most common formats are CSV, JSON, AVRO, Protocol Buffers, Parquet, and ORC.
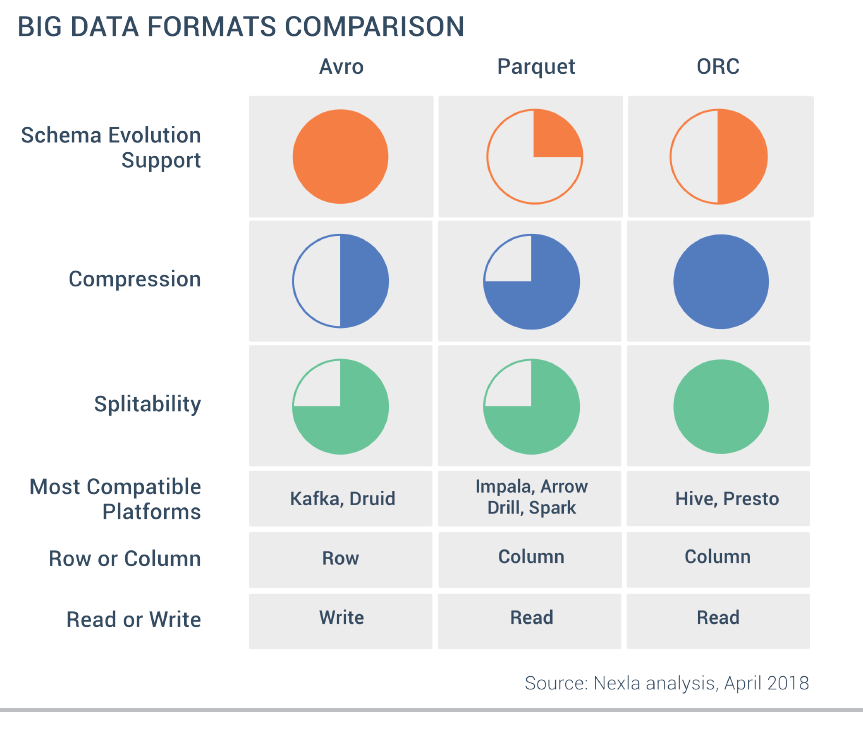
Some things to consider when choosing the format are:
- The structure of your data: Some formats accept nested data such JSON, Avro or Parquet and others do not. Even, the ones that do, may not be highly optimized for it. Avro is the most efficient format for nested data, I recommend not to use Parquet nested types because they are very inefficient. Process nested JSON is also very CPU intensive. In general, it is recommended to flat the data when ingesting it.
- Performance: Some formats such Avro and Parquet perform better than other such JSON. Even between Avro and Parquet for different use cases one will be better than others. For example, since Parquet is a column based format it is great to query your data lake using SQL whereas Avro is better for ETL row level transformation.
- Easy to read: Consider if you need people to read the data or not. JSON or CSV are text formats and are human readable whereas more performant formats such parquet or Avro are binary.
- Compression: Some formats offer higher compression rates than others.
- Schema evolution: Adding or removing fields is far more complicated in a data lake than in a database. Some formats like Avro or Parquet provide some degree of schema evolution which allows you to change the data schema and still query the data. Tools such Delta Lake format provide even better tools to deal with changes in Schemas.
- Compatibility: JSON or CSV are widely adopted and compatible with almost any tool while more performant options have less integration points.
As we can see, CSV and JSON are easy to use, human readable and common formats but lack many of the capabilities of other formats, making it too slow to be used to query the data lake. ORC and Parquet are widely used in the Hadoop ecosystem to query data whereas Avro is also used outside of Hadoop, especially together with Kafka for ingestion, it is very good for row level ETL processing. Row oriented formats have better schema evolution capabilities than column oriented formats making them a great option for data ingestion.
Lastly, you need to also consider how to compress the data in your files considering the trade off between file size and CPU costs. Some compression algorithms are faster but with bigger file size and others slower but with better compression rates. For more details check this article.
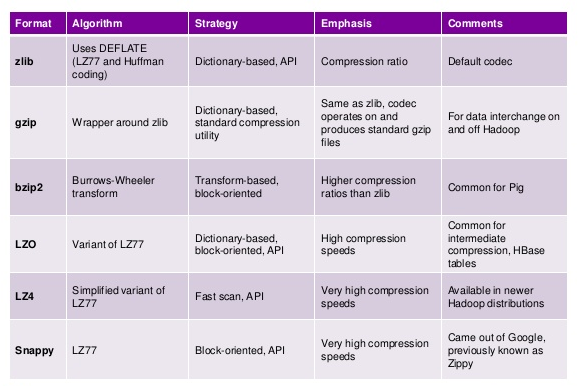
I recommend using snappy for streaming data since it does not require too much CPU power. For batch bzip2 is a great option.
Again, you need to review the considerations that we mentioned before and decide based on all the aspects we reviewed. Let’s go through some use cases as an example:
Use Cases
- You need to ingest real time data and storage somewhere for further processing as part of an ETL pipeline. If performance is important and budget is not an issue you could use Cassandra. The standard approach is to store it in HDFS using an optimized format as AVRO.
- You need to process your data and storage somewhere to be used by a highly interactive user facing application where latency is important (OLTP), you know the queries in advance. In this case use Cassandra or another database depending on the volume of your data.
- You need to serve your processed data to your user base, consistency is important and you do not know the queries in advance since the UI provides advanced queries. In this case you need a relational SQL data base, depending on your side a classic SQL DB such MySQL will suffice or you may need to use YugaByteDB or other relational massive scale database.
- You need to store your processed data for OLAP analysis for your internal team so they can run ad-hoc queries and create reports. In this case, you can store the data in your deep storage file system in Parquet or ORC format.
- You need to use SQL to run ad-hoc queries of historical data but you also need dashboards that need to respond in less than a second. In this case you need a hybrid approach where you store a subset of the data in a fast storage such as MySQL database and the historical data in Parquet format in the data lake. Then, use a query engine to query across different data sources using SQL.
- You need to perform really complex queries that need to respond in just a few milliseconds, you also may need to perform aggregations on read. In this case, use ElasticSearch to store the data or some newer OLAP system like Apache Pinot which we will discuss later.
- You need to search unstructured text. In this case use ElasticSearch.
Infrastructure
Your current infrastructure can limit your options when deciding which tools to use. The first question to ask is: Cloud vs On-Prem. Cloud providers offer many options and flexibility. Furthermore, they provide Serverless solutions for your Big Data needs which are easier to manage and monitor. Definitely, the cloud is the place to be for Big Data; even for the Hadoop ecosystem, cloud providers offer managed clusters and cheaper storage than on premises. Check my other articles regarding cloud solutions.
If you are running on premises you should think about the following:
- Where do I run my workloads? Definitely Kubernetes or Apache Mesos provide a unified orchestration framework to run your applications in a unified way. The deployment, monitoring and alerting aspects will be the same regardless of the framework you use. In contrast, if you run on bare metal, you need to think and manage all the cross cutting aspects of your deployments. In this case, managed clusters and tools will suit better than libraries and frameworks.
- What type of hardware do I have? If you have specialized hardware with fast SSDs and high-end servers, then you may be able to deploy massive databases like Cassandra and get great performance. If you just own commodity hardware, the Hadoop ecosystem will be a better option. Ideally, you want to have several types of servers for different workloads; the requirements for Cassandra are far different from HDFS.
Monitoring and Alerting
The next ingredient is essential for the success of your data pipeline. In the big data world, you need constant feedback about your processes and your data. You need to gather metrics, collect logs, monitor your systems, create alerts, dashboards and much more.
Use open source tools like Prometheus and Grafana for monitor and alerting. Use log aggregation technologies to collect logs and store them somewhere like ElasticSearch.
Leverage on cloud providers capabilities for monitoring and alerting when possible. Depending on your platform you will use a different set of tools. For Cloud Serverless platform you will rely on your cloud provider tools and best practices. For Kubernetes, you will use open source monitor solutions or enterprise integrations. I really recommend this website where you can browse and check different solutions and built your own APM solution.
Another thing to consider in the Big Data world is auditability and accountability. Because of different regulations, you may be required to trace the data, capturing and recording every change as data flows through the pipeline. This is called data provenance or lineage. Tools like Apache Atlas are used to control, record and govern your data. Other tools such Apache NiFi supports data lineage out of the box. For real time traces, check Open Telemetry or Jaeger. There are also a lot of cloud services such Datadog.
For Hadoop use, Ganglia.
Security
Apache Ranger provides a unified security monitoring framework for your Hadoop platform. Provides centralized security administration to manage all security related tasks in a central UI. It provides authorization using different methods and also full auditability across the entire Hadoop platform.
People
Your team is the key to success. Big Data Engineers can be difficult to find. Invest in training, upskilling, workshops. Remove silos and red tape, make iterations simple and use Domain Driven Design to set your team boundaries and responsibilities.
For Big Data you will have two broad categories:
- Data Engineers for ingestion, enrichment and transformation. These engineers have a strong development and operational background and are in charge of creating the data pipeline. Developers, Administrators, DevOps specialists, etc will fall in this category.
- Data Scientist: These can be BI specialists, data analysts, etc. in charge of generation reports, dashboards and gathering insights. Focused on OLAP and with strong business understanding, these people gather the data which will be used to make critical business decisions. Strong in SQL and visualization but weak in software development. Machine Learning specialists may also fall into this category.
Budget
This is an important consideration, you need money to buy all the other ingredients, and this is a limited resource. If you have unlimited money you could deploy a massive database and use it for your big data needs without many complications but it will cost you. So each technology mentioned in this article requires people with the skills to use it, deploy it and maintain it. Some technologies are more complex than others, so you need to take this into account.
Recipe
Now that we have the ingredients, let’s cook our big data recipe. In a nutshell the process is simple; you need to ingest data from different sources, enrich it, store it somewhere, store the metadata(schema), clean it, normalize it, process it, quarantine bad data, optimally aggregate data and finally store it somewhere to be consumed by downstream systems.
Let’s have a look a bit more in detail to each step…
Ingestion
The first step is to get the data, the goal of this phase is to get all the data you need and store it in raw format in a single repository. This is usually owned by other teams who push their data into Kafka or a data store.
For simple pipelines with not huge amounts of data you can build a simple microservices workflow that can ingest, enrich and transform the data in a single pipeline(ingestion + transformation), you may use tools such Apache Airflow to orchestrate the dependencies. However, for Big Data it is recommended that you separate ingestion from processing, massive processing engines that can run in parallel are not great to handle blocking calls, retries, back pressure, etc. So, it is recommended that all the data is saved before you start processing it. You should enrich your data as part of the ingestion by calling other systems to make sure all the data, including reference data has landed into the lake before processing.
There are two modes of ingestion:
- Pull: Pull the data from somewhere like a database, file system, a queue or an API
- Push: Applications can also push data into your lake but it is always recommended to have a messaging platform as Kafka in between. A common pattern is Change Data Capture(CDC) which allows us to move data into the lake in real time from databases and other systems.
As we already mentioned, It is extremely common to use Kafka or Pulsar as a mediator for your data ingestion to enable persistence, back pressure, parallelization and monitoring of your ingestion. Then, use Kafka Connect to save the data into your data lake. The idea is that your OLTP systems will publish events to Kafka and then ingest them into your lake. Avoid ingesting data in batch directly through APIs; you may call HTTP end-points for data enrichment but remember that ingesting data from APIs it’s not a good idea in the big data world because it is slow, error prone(network issues, latency…) and can bring down source systems. Although, APIs are great to set domain boundaries in the OLTP world, these boundaries are set by data stores(batch) or topics(real time) in Kafka in the Big Data world. Of course, it always depends on the size of your data but try to use Kafka or Pulsar when possible and if you do not have any other options; pull small amounts of data in a streaming fashion from the APIs, not in batch. For databases, use tools such Debezium to stream data to Kafka (CDC).
To minimize dependencies, it is always easier if the source system push data to Kafka rather than your team pulling the data since you will be tightly coupled with the other source systems. If this is not possible and you still need to own the ingestion process, we can look at two broad categories for ingestion:
- Un Managed Solutions: These are applications that you develop to ingest data into your data lake; you can run them anywhere. This is very common when ingesting data from APIs or other I/O blocking systems that do not have an out of the box solution, or when you are not using the Hadoop ecosystem. The idea is to use streaming libraries to ingest data from different topics, end-points, queues, or file systems. Because you are developing apps, you have full flexibility. Most libraries provide retries, back pressure, monitoring, batching and much more. This is a code yourself approach, so you will need other tools for orchestration and deployment. You get more control and better performance but more effort involved. You can have a single monolith or microservices communicating using a service bus or orchestrated using an external tool. Some of the libraries available are Apache Camel or Akka Ecosystem (Akka HTTP + Akka Streams + Akka Cluster + Akka Persistence + Alpakka). You can deploy it as a monolith or as microservices depending on how complex is the ingestion pipeline. If you use Kafka or Pulsar, you can use them as ingestion orchestration tools to get the data and enrich it. Each stage will move data to a new topic creating a DAG in the infrastructure itself by using topics for dependency management. If you do not have Kafka and you want a more visual workflow you can use Apache Airflow to orchestrate the dependencies and run the DAG. The idea is to have a series of services that ingest and enrich the date and then, store it somewhere. After each step is complete, the next one is executed and coordinated by Airflow. Finally, the data is stored in some kind of storage.
- Managed Solutions: In this case you can use tools which are deployed in your cluster and used for ingestion. This is common in the Hadoop ecosystem where you have tools such Sqoop to ingest data from your OLTP databases and Flume to ingest streaming data. These tools provide monitoring, retries, incremental load, compression and much more.
NiFi is one of these tools that are difficult to categorize. It is a beast on its own. It can be used for ingestion, orchestration and even simple transformations. So in theory, it could solve simple Big Data problems. It is a managed solution. It has a visual interface where you can just drag and drop components and use them to ingest and enrich data. It has over 300 built in processors which perform many tasks and you can extend it by implementing your own.

It has its own architecture, so it does not use any database HDFS but it has integrations with many tools in the Hadoop Ecosystem. You can call APIs, integrate with Kafka, FTP, many file systems and cloud storage. You can manage the data flow performing routing, filtering and basic ETL. For some use cases, NiFi may be all you need.
However, NiFi cannot scale beyond a certain point, because of the inter node communication more than 10 nodes in the cluster become inefficient. It tends to scale vertically better, but you can reach its limit, especially for complex ETL. However, you can integrate it with tools such Spark to process the data. NiFi is a great tool for ingesting and enriching your data.
Modern OLAP engines such Druid or Pinot also provide automatic ingestion of batch and streaming data, we will talk about them in another section.
You can also do some initial validation and data cleaning during the ingestion, as long as they are not expensive computations or do not cross over the bounded context, remember that a null field may be irrelevant to you but important for another team.
The last step is to decide where to land the data, we already talked about this. You can use a database or a deep storage system. For a data lake, it is common to store it in HDFS, the format will depend on the next step; if you are planning to perform row level operations, Avro is a great option. Avro also supports schema evolution using an external registry which will allow you to change the schema for your ingested data relatively easily.
Metadata
The next step after storing your data, is save its metadata (information about the data itself). The most common metadata is the schema. By using an external metadata repository, the different tools in your data lake or data pipeline can query it to infer the data schema.
If you use Avro for raw data, then the external registry is a good option. This way you can easily de couple ingestion from processing.
Once the data is ingested, in order to be queried by OLAP engines, it is very common to use SQL DDL. The most used data lake/data warehouse tool in the Hadoop ecosystem is Apache Hive, which provides a metadata store so you can use the data lake like a data warehouse with a defined schema. You can run SQL queries on top of Hive and connect many other tools such Spark to run SQL queries using Spark SQL. Hive is an important tool inside the Hadoop ecosystem providing a centralized meta database for your analytical queries. Other tools such Apache Tajo are built on top of Hive to provide data warehousing capabilities in your data lake.
Apache Impala is a native analytic database for Hadoop which provides metadata store, you can still connect to Hive for metadata using Hcatalog.
Apache Phoenix has also a metastore and can work with Hive. Phoenix focuses on OLTP enabling queries with ACID properties to the transactions. It is flexible and provides schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store. Apache Druid or Pinot also provide metadata store.
Processing
The goal of this phase is to clean, normalize, process and save the data using a single schema. The end result is a trusted data set with a well defined schema.
Generally, you would need to do some kind of processing such as:
- Validation: Validate data and quarantine bad data by storing it in a separate storage. Send alerts when a certain threshold is reached based on your data quality requirements.
- Wrangling and Cleansing: Clean your data and store it in another format to be further processed, for example replace inefficient JSON with Avro.
- Normalization and Standardization of values
- Rename fields
- …
Remember, the goal is to create a trusted data set that later can be used for downstream systems. This is a key role of a data engineer. This can be done in a stream or batch fashion.
The pipeline processing can be divided in three phases in case of batch processing:
- Pre Processing Phase: If the raw data is not clean or not in the right format, you need to pre process it. This phase includes some basic validation, but the goal is to prepare the data to be efficiently processed for the next stage. In this phase, you should try to flatten the data and save it in a binary format such Avro. This will speed up further processing. The idea is that the next phase will perform row level operations, and nested queries are expensive, so flattening the data now will improve the next phase performance.
- Trusted Phase: Data is validated, cleaned, normalized and transformed to a common schema stored in Hive. The goal is to create a trusted common data set understood by the data owners. Typically, a data specification is created and the role of the data engineer is to apply transformations to match the specification. The end result is a data set in Parquet format that can be easily queried. It is critical that you choose the right partitions and optimize the data to perform internal queries. You may want to partially pre compute some aggregations at this stage to improve query performance.
- Reporting Phase: This step is optional but often required. Unfortunately, when using a data lake, a single schema will not serve all use cases; this is one difference between a data warehouse and data lake. Querying HDFS is not as efficient as a database or data warehouse, so further optimizations are required. In this phase, you may need to denormalize the data to store it using different partitions so it can be queried more efficiently by the different stakeholders. The idea is to create different views optimized for the different downstream systems (data marts). In this phase you can also compute aggregations if you do not use an OLAP engine (see next section). The trusted phase does not know anything about who will query the data, this phase optimizes the data for the consumers. If a client is highly interactive, you may want to introduce a fast storage layer in this phase like a relational database for fast queries. Alternatively you can use OLAP engines which we will discuss later.
For streaming the logic is the same but it will run inside a defined DAG in a streaming fashion. Spark allows you to join stream with historical data but it has some limitations. We will discuss later on OLAP engines, which are better suited to merge real time with historical data.
Processing Frameworks
Some of the tools you can use for processing are:
- Apache Spark: This is the most well known framework for batch processing. Part of the Hadoop ecosystem, it is a managed cluster which provides incredible parallelism, monitoring and a great UI. It also supports stream processing (structural streaming). Basically Spark runs MapReduce jobs in memory increasing up to 100x times regular MapReduce performance. It integrates with Hive to support SQL and can be used to create Hive tables, views or to query data. It has lots of integrations, supports many formats and has a huge community. It is supported by all cloud providers. It can run on YARN as part of a Hadoop cluster but also in Kubernetes and other platforms. It has many libraries for specific use cases such SQL or machine learning.
- Apache Flink: The first engine to unify batch and streaming but heavily focus on streaming. It can be used as a backbone for microservices like Kafka. It can run on YARN as part of a Hadoop cluster but since its inception has been also optimized for other platforms like Kubernetes or Mesos. It is extremely fast and provides real time streaming, making it a better option than Spark for low latency stream processing, especially for stateful streams. It also has libraries for SQL, Machine Learning and much more.
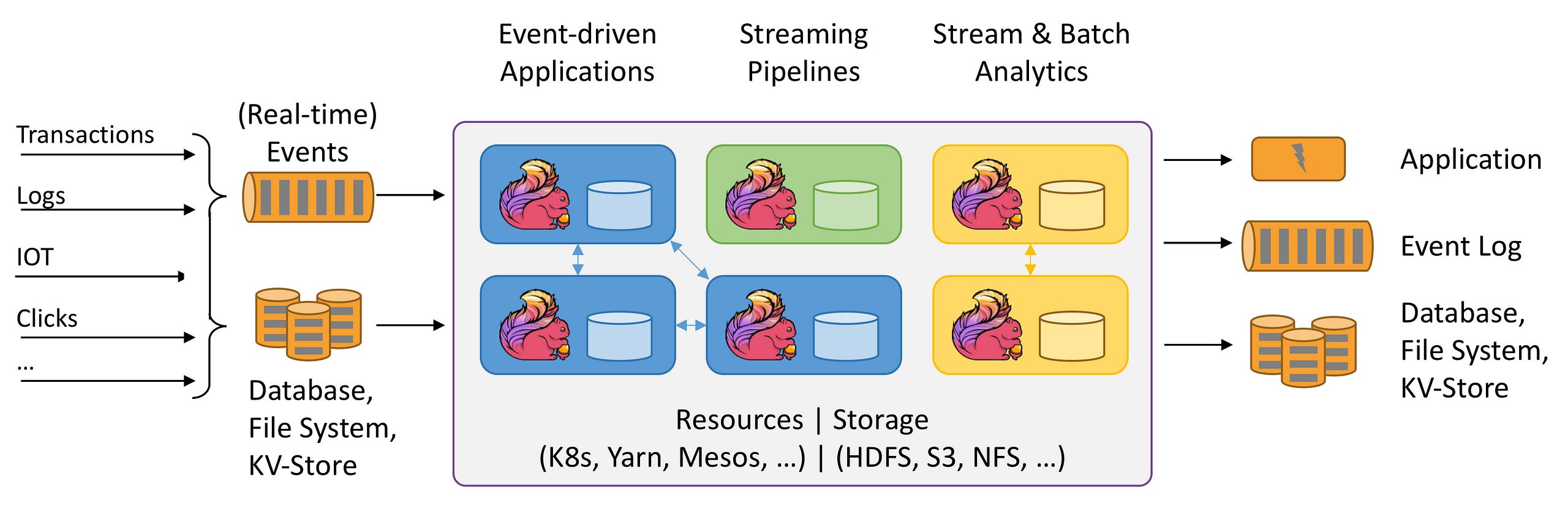
- Apache Storm: Apache Storm is a free and open source distributed real-time computation system.It focuses on streaming and it is a managed solution part of the Hadoop ecosystem. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
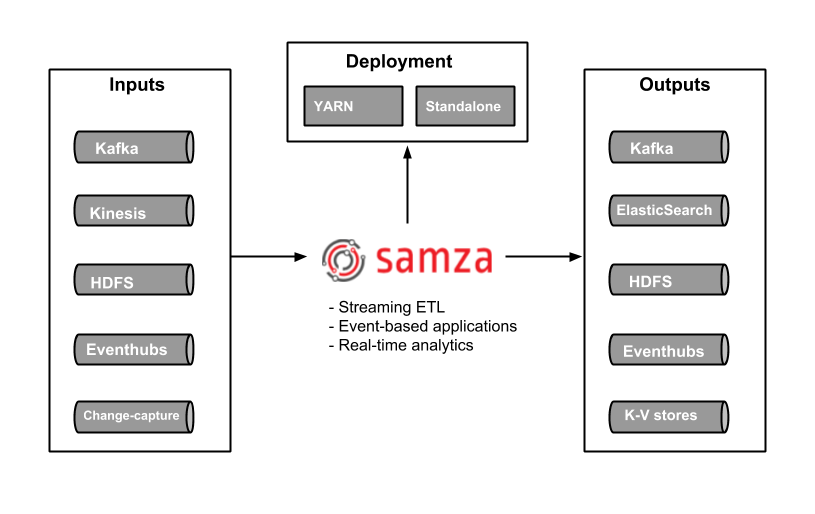
- Apache Samza: Another great stateful stream processing engine. Samza allows you to build stateful applications that process data in real-time from multiple sources including Apache Kafka. Managed solution part of the Hadoop Ecosystem that runs on top of YARN.
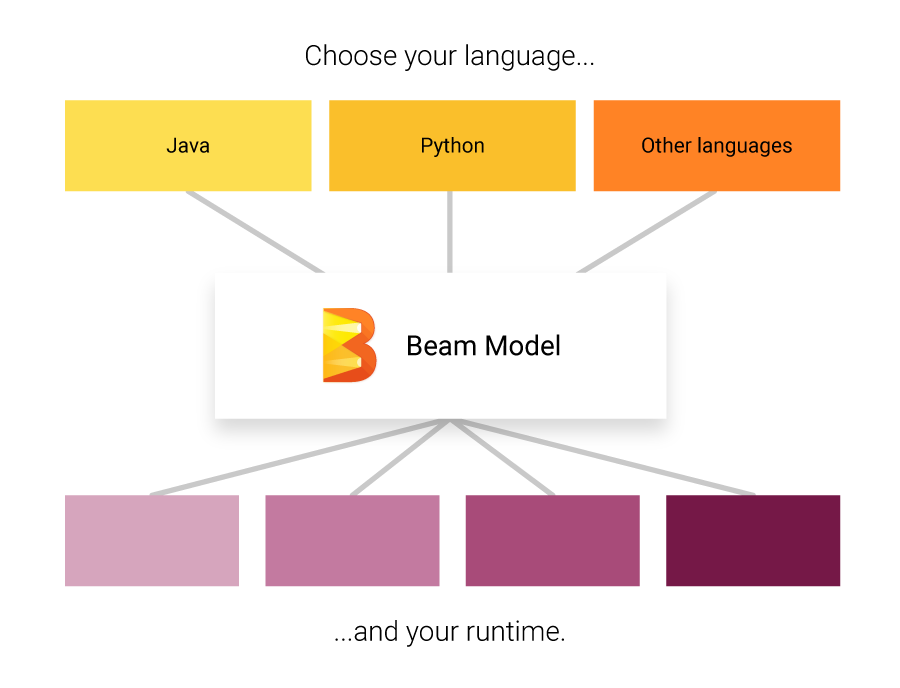
- Apache Beam: Apache Beam it is not an engine itself but a specification of an unified programming model that brings together all the other engines. It provides a programming model that can be used with different languages, so developers do not have to learn new languages when dealing with big data pipelines. Then, it plugs different back ends for the processing step that can run on the cloud or on premises. Beam supports all the engines mentioned before and you can easily switch between them and run them in any platform: cloud, YARN, Mesos, Kubernetes. If you are starting a new project, I really recommend starting with Beam to be sure your data pipeline is future proof.
By the end of this processing phase, you have cooked your data and is now ready to be consumed!, but in order to cook the chef must coordinate with his team…
Orchestration
Data pipeline orchestration is a cross cutting process which manages the dependencies between all the other tasks. If you use stream processing, you need to orchestrate the dependencies of each streaming app, for batch, you need to schedule and orchestrate the jobs.
Tasks and applications may fail, so you need a way to schedule, reschedule, replay, monitor, retry and debug your whole data pipeline in an unified way.
Newer frameworks such Dagster or Prefect add more capabilities and allow you to track data assets adding semantics to your pipeline.
Some of the options are:
- Apache Oozie: Oozie it’s a scheduler for Hadoop, jobs are created as DAGs and can be triggered by time or data availability. It has integrations with ingestion tools such as Sqoop and processing frameworks such Spark.
- Apache Airflow: Airflow is a platform that allows to schedule, run and monitor workflows. Uses DAGs to create complex workflows. Each node in the graph is a task, and edges define dependencies among the tasks. Airflow scheduler executes your tasks on an array of workers while following the specified dependencies described by you. It generates the DAG for you maximizing parallelism. The DAGs are written in Python, so you can run them locally, unit test them and integrate them with your development workflow. It also supports SLAs and alerting. Luigi is an alternative to Airflow with similar functionality but Airflow has more functionality and scales up better than Luigi.
- Dagster is a newer orchestrator for machine learning, analytics, and ETL. The main different is that you can track the inputs and outputs of the data, similar to Apache NiFi creating a data flow solution. You can also materialize other values as part of your tasks. It can also run several jobs in parallel, it is easy to add parameters, easy to test, provides simple versioning and much more. It is still a bit immature and due to the fact that it needs to keep track the data, it may be difficult to scale, which is a problem shared with NiFi.
- Prefect is similar to Dagster, provides local testing, versioning, parameter management and much more. What makes Prefect different from the rest is that aims to overcome the limitations of Airflow execution engine such as improved scheduler, Parametrized workflows, dynamic workflows, versioning and improved testing. It has an core open source workflow management system and also a cloud offering which requires no setup at all.
- Apache NiFi: NiFi can also schedule jobs, monitor, route data, alert and much more. It is focused on data flow but you can also process batches. It runs outside of Hadoop but can trigger Spark jobs and connect to HDFS/S3.
In short, if your requirement is just orchestrate independent tasks that do not require to share data use Airflow or Ozzie. For data flow applications that require data lineage and tracking use NiFi for non developers or Dagster or Prefect for developers.
Data Quality
One important aspect in Big Data, often ignore is data quality and assurance. Companies loose every year tons of money because of data quality issues. The problem is that this is still an immature field in data science, developers have been working on this area for decades and they have great test frameworks and methodologies such BDD or TDD, but how do you test your pipeline?
There are two common problems in this field:
- Misunderstood requirements: Quite often the transformation and orchestration logic can become very complex. Business Analyst may write requirements using their domain language which needs to be interpreted by developers who often make mistakes and plan, develop, test and deploy solutions who are technically correct but with the wrong requirements. These type of errors are very costly.
- Data Validation: Pipeline testing is quite different from code. When developing software you test functions, it is black box testing, deterministic. For a given input you always get the same output. For data assets, testing is more complex: you need to assert data types, values, constraints and much more. Moreover, you need to apply aggregations to verify the data set to make sure that the number of rows or columns are corrects. For example, it is very hard to detect if one day you get a 10% drop on your data size, or if certain values correctly populated.
Companies are still at its infancy regarding data quality and testing, this creates a huge technical debt. I really recommend checking this article for more information.
To mitigate these issue, try to follow DDD principles and make sure that boundaries are set and a common language is used. Use frameworks that support data lineage like NiFi or Dagster.
Some tools focused on data quality are:
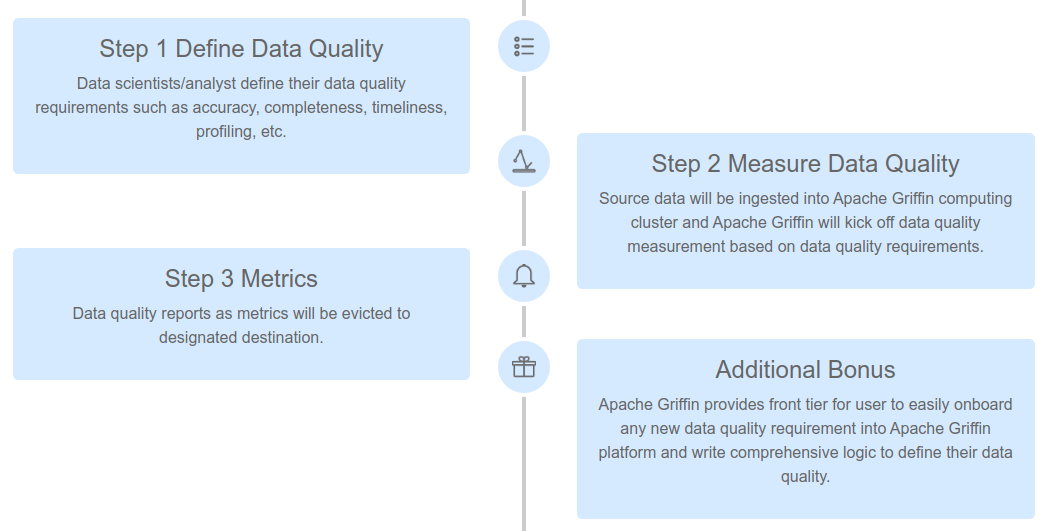
- Apache Griffin: Part of the Hadoop Ecosystem, this tool offers an unified process to measure your data quality from different perspectives, helping you build trusted data assets. It provides a DSL that you can use to create assertions for your data and verify them as part of your pipeline. It is integrated with Spark. You can add rules and assertions for your data set and then run the validation as a Spark job. The problem with Griffin is the fact that the DSL can become difficult to manage(JSON) and it is hard to interpret by non- technical people which means it does not solve the misunderstood requirements issue.
- Great Expectations: This is a newer tool written in Python and focused on data quality, pipeline testing and quality assurance. It can be easily integrated with Airflow or other orchestration tools and provide automated data validation. What set this tool apart is the fact that is human readable and can be used by data analyst, BAs and developers. It provides a intuitive UI but also full automation so you can run the validations as part of your production pipeline and view the results in a nice UI. The assertions can be written by non technical people using Notebooks which provide documentation and formal requirements that developers can easily understand, translate to code and use for testing. BAs or testers write the data assertions (Expectations) which are transformed to human readable test in the UI so everyone can see them and verify them. It can also do data profiling to generate some assertions for you. It can connect directly to your databases or file systems on-prem or in the cloud. It is very easy to use and to manage. The expectations can be committed to the source code repository and then integrated in your pipeline. Great Expectations creates a common language and framework for all parties involved in data quality, making it very easy to automate and test your pipeline with minimal effort.
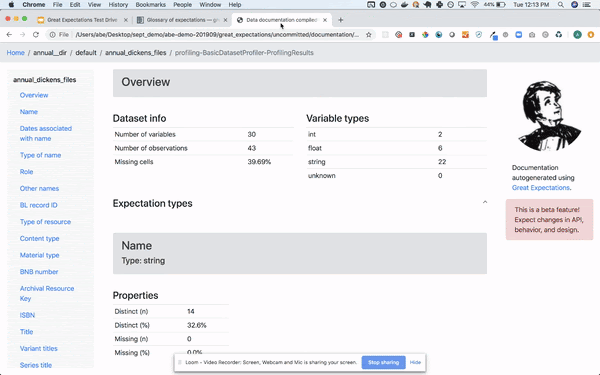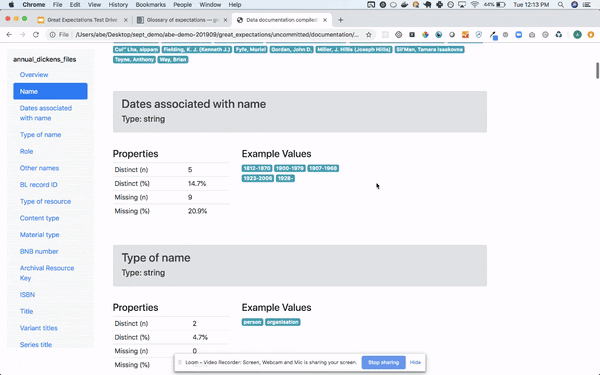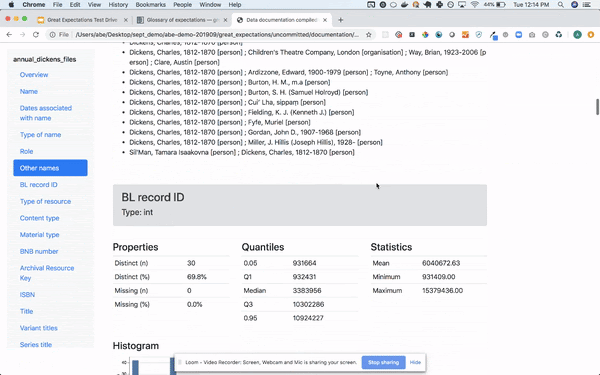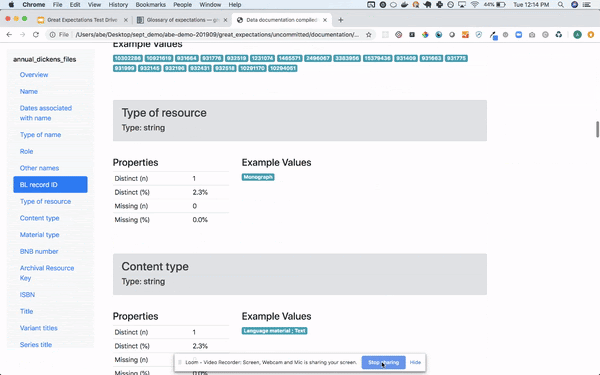
Query your data
Now that you have your cooked recipe, it is time to finally get the value from it. By this point, you have your data stored in your data lake using some deep storage such HDFS in a queryable format such Parquet or in a OLAP database.
There are a wide range of tools used to query the data, each one has its advantages and disadvantages. Most of them focused on OLAP but few are also optimized for OLTP. Some use standard formats and focus only on running the queries whereas others use their own format/storage to push processing to the source to improve performance. Some are optimized for data warehousing using star or snowflake schema whereas others are more flexible. To summarize these are the different considerations:
- Data warehouse vs data lake
- Hadoop vs Standalone
- OLAP vs OLTP
- Query Engine vs. OLAP Engines
We should also consider processing engines with querying capabilities.
Processing Engines
Most of the engines we described in the previous section can connect to the metadata server such as Hive and run queries, create views, etc. This is a common use case to create refined reporting layers.
Spark SQL provides a way to seamlessly mix SQL queries with Spark programs, so you can mix the DataFrame API with SQL. It has Hive integration and standard connectivity through JDBC or ODBC; so you can connect Tableau, Looker or any BI tool to your data through Spark.

Apache Flink also provides SQL API. Flink’s SQL support is based on Apache Calcite which implements the SQL standard. It also integrates with Hive through the HiveCatalog. For example, users can store their Kafka or ElasticSearch tables in Hive Metastore by using HiveCatalog, and reuse them later on in SQL queries.
Query Engines
This type of tools focus on querying different data sources and formats in an unified way. The idea is to query your data lake using SQL queries like if it was a relational database, although it has some limitations. Some of these tools can also query NoSQL databases and much more. These tools provide a JDBC interface for external tools, such as Tableau or Looker, to connect in a secure fashion to your data lake. Query engines are the slowest option but provide the maximum flexibility.
- Apache Pig: It was one of the first query languages along with Hive. It has its own language different from SQL. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets. It is now in decline in favor of newer SQL based engines.
- Presto: Released as open source by Facebook, it’s an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes. Presto allows querying data where it lives, including Hive, Cassandra, relational databases and file systems. It can perform queries on large data sets in a manner of seconds. It is independent of Hadoop but integrates with most of its tools, especially Hive to run SQL queries.
- Apache Drill: Provides a schema-free SQL Query Engine for Hadoop, NoSQL and even cloud storage. It is independent of Hadoop but has many integrations with the ecosystem tools such Hive. A single query can join data from multiple datastores performing optimizations specific to each data store. It is very good at allowing analysts to treat any data like a table, even if they are reading a file under the hood. Drill supports fully standard SQL. Business users, analysts and data scientists can use standard BI/analytics tools such as Tableau, Qlik and Excel to interact with non-relational datastores by leveraging Drill’s JDBC and ODBC drivers. Furthermore, developers can leverage Drill’s simple REST API in their custom applications to create beautiful visualizations.
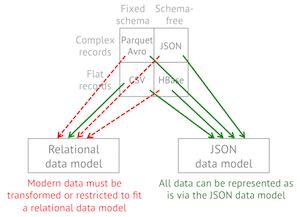
OLTP Databases
Although, Hadoop is optimized for OLAP there are still some options if you want to perform OLTP queries for an interactive application.
HBase has very limited ACID properties by design, since it was built to scale and does not provides ACID capabilities out of the box but it can be used for some OLTP scenarios.
Apache Phoenix is built on top of HBase and provides a way to perform OTLP queries in the Hadoop ecosystem. Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce. It also can store metadata and it supports table creation and versioned incremental alterations through DDL commands. It is quite fast, faster than using Drill or other query engine.
You may use any massive scale database outside the Hadoop ecosystem such as Cassandra, YugaByteDB, ScyllaDB for OTLP.
Finally, it is very common to have a subset of the data, usually the most recent, in a fast database of any type such MongoDB or MySQL. The query engines mentioned above can join data between slow and fast data storage in a single query.
Distributed Search Indexes
These tools provide a way to store and search unstructured text data and they live outside the Hadoop ecosystem since they need special structures to store the data. The idea is to use an inverted index to perform fast lookups. Besides text search, this technology can be used for a wide range of use cases like storing logs, events, etc. There are two main options:
- Solr: it is a popular, blazing-fast, open source enterprise search platform built on Apache Lucene. Solr is reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. It is great for text search but its use cases are limited compared to ElasticSearch.
- ElasticSearch: It is also a very popular distributed index but it has grown into its own ecosystem which covers many use cases like APM, search, text storage, analytics, dashboards, machine learning and more. It is definitely a tool to have in your toolbox either for DevOps or for your data pipeline since it is very versatile. It can also store and search videos and images.
ElasticSearch can be used as a fast storage layer for your data lake for advanced search functionality. If you store your data in a key-value massive database, like HBase or Cassandra, which provide very limited search capabilities due to the lack of joins; you can put ElasticSearch in front to perform queries, return the IDs and then do a quick lookup on your database.
It can be used also for analytics; you can export your data, index it and then query it using Kibana, creating dashboards, reports and much more, you can add histograms, complex aggregations and even run machine learning algorithms on top of your data. The Elastic Ecosystem is huge and worth exploring.

OLAP Databases
In this category we have databases which may also provide a metadata store for schemas and query capabilities. Compared to query engines, these tools also provide storage and may enforce certain schemas in case of data warehouses (star schema). These tools use SQL syntax and Spark and other frameworks can interact with them.
- Apache Hive: We already discussed Hive as a central schema repository for Spark and other tools so they can use SQL, but Hive can also store data, so you can use it as a data warehouse. It can access HDFS or HBase. When querying Hive it leverages on Apache Tez, Apache Spark, or MapReduce, being Tez or Spark much faster. It also has a procedural language called HPL-SQL.
- Apache Impala: It is a native analytic database for Hadoop, that you can use to store data and query it in an efficient manner. It can connect to Hive for metadata using Hcatalog. Impala provides low latency and high concurrency for BI/analytic queries on Hadoop (not delivered by batch frameworks such as Apache Hive). Impala also scales linearly, even in multitenant environments making a better alternative for queries than Hive. Impala is integrated with native Hadoop security and Kerberos for authentication, so you can securely managed data access. It uses HBase and HDFS for data storage.
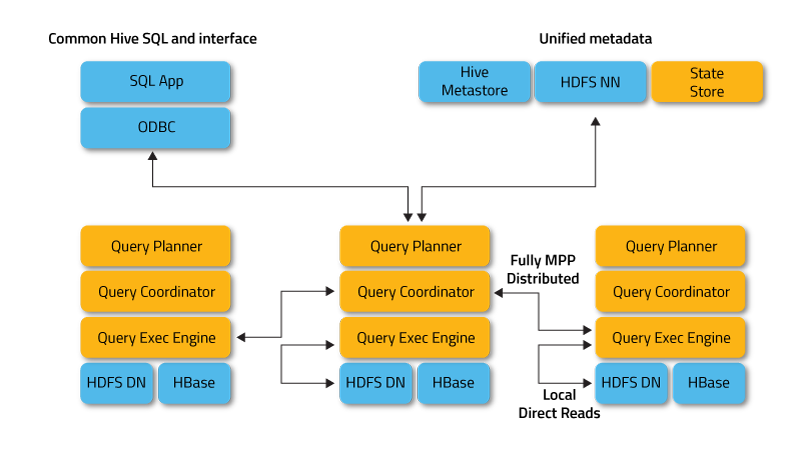
- Apache Tajo: It is another data warehouse for Hadoop. Tajo is designed for low-latency and scalable ad-hoc queries, online aggregation, and ETL on large-data sets stored on HDFS and other data sources. It has integration with Hive Metastore to access the common schemas. It has many query optimizations, it is scalable, fault tolerant and provides a JDBC interface.
- Apache Kylin: Apache Kylin is a newer distributed Analytical Data Warehouse. Kylin is extremely fast, so it can be used to complement some of the other databases like Hive for use cases where performance is important such as dashboards or interactive reports, it is probably the best OLAP data warehouse but it is more difficult to use, another problem is that because of the high dimensionality, you need more storage. The idea is that if query engines or Hive are not fast enough, you can create a “Cube” in Kylin which is a multidimensional table optimized for OLAP with pre computed values which you can query from your dashboards or interactive reports. It can build cubes directly from Spark and even in near real time from Kafka.
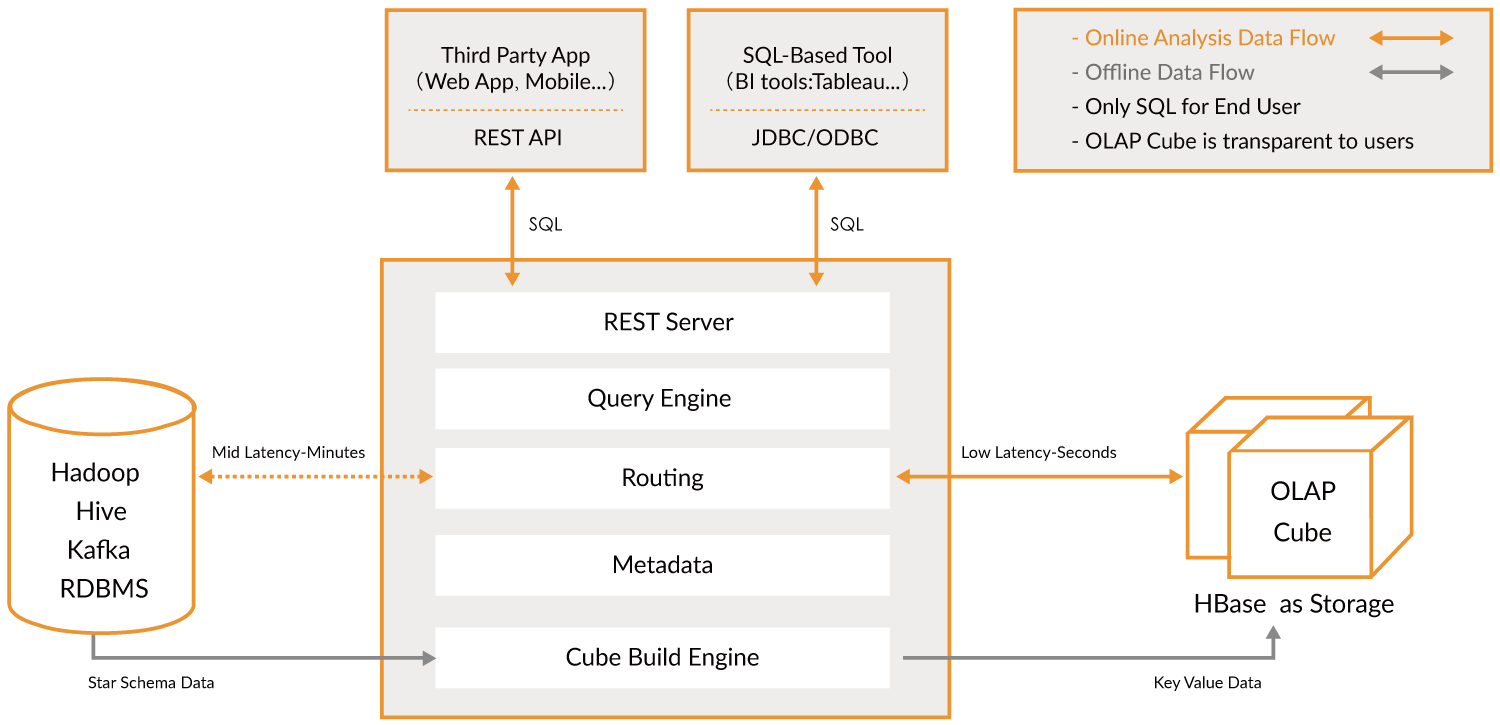
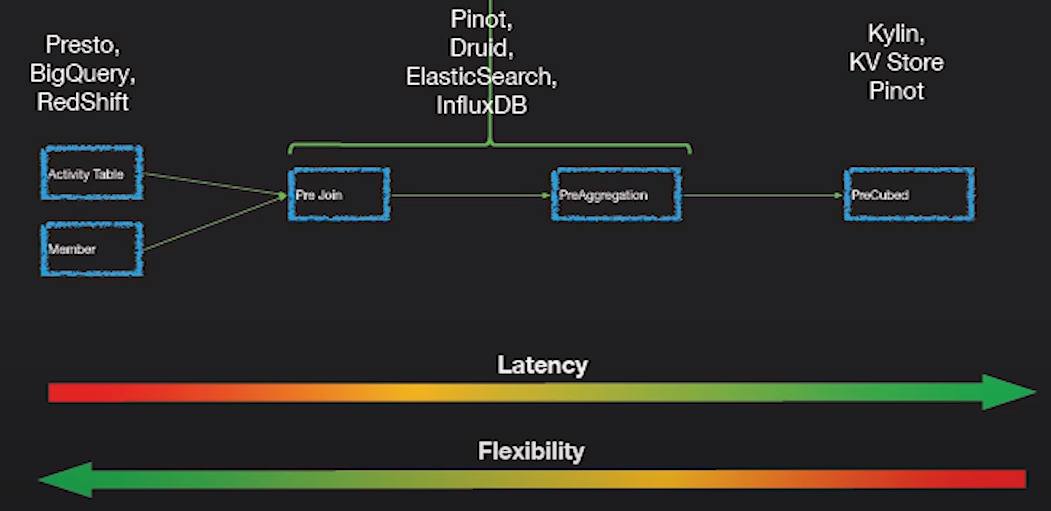
OLAP Engines
In this category, I include newer engines that are an evolution of the previous OLAP databases which provide more functionality creating an all-in-one analytics platform. Actually, they are a hybrid of the previous two categories adding indexing to your OLAP databases. They live outside the Hadoop platform but are tightly integrated. In this case, you would typically skip the processing phase and ingest directly using these tools.
They try to solve the problem of querying real time and historical data in an uniform way, so you can immediately query real-time data as soon as it’s available alongside historical data with low latency so you can build interactive applications and dashboards. These tools allow in many cases to query the raw data with almost no transformation in an ELT fashion but with great performance, better than regular OLAP databases.
What they have in common is that they provided a unified view of the data, real time and batch data ingestion, distributed indexing, its own data format, SQL support, JDBC interface, hot-cold data support, multiple integrations and a metadata store.
- Apache Druid: It is the most famous real time OLAP engine. It focused on time series data but it can be used for any kind of data. It uses its own columnar format which can heavily compress the data and it has a lot of built in optimizations like inverted indices, text encoding, automatic data roll up and much more. Data is ingested in real time using Tranquility or Kafka which has very low latency, data is kept in memory in a row format optimized for writes but as soon as it arrives is available to be query just like previous ingested data. A background task in in charge of moving the data asynchronously to a deep storage system such HDFS. When data is moved to deep storage it is converted into smaller chunks partitioned by time called segments which are highly optimized for low latency queries. Each segment has a timestamp, several dimensions which you can use to filter and perform aggregations; and metrics which are pre computed aggregations. For batch ingestion, it saves data directly into Segments. It support push and pull ingestion. It has integrations with Hive, Spark and even NiFi. It can use Hive metastore and it supports Hive SQL queries which then are converted to JSON queries used by Druid. The Hive integration supports JDBC so you can connect any BI tool. It also has its own metadata store, usually MySQL. It can ingest vast amounts of data and scale very well. The main issue is that it has a lot of components and it is difficult to manage and deploy.
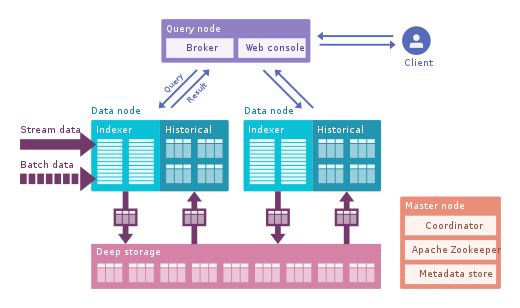
- Apache Pinot: It is a newer alternative to Druid open sourced by LinkedIn. Compared to Druid, it offers lower latency thanks to the Startree index which offer partial pre computation, so it can be used for user facing apps(it’s used to get the LinkedIn feeds). It uses a sorted index instead of inverted index which is faster. It has an extendable plugin architecture and also has many integrations but does not support Hive. It also unifies batch and real time, provides fast ingestion, smart index and stores the data in segments. It is easier to deploy and faster compared to Druid but it is a bit immature at the moment.
- ClickHouse: Written in C++, this engine provides incredible performance for OLAP queries, especially aggregations. It looks like a relational database so you can model the data very easily. It is very easy to set up and has many integrations.

Check this article which compares the 3 engines in detail. Again, start small and know your data before making a decision, these new engines are very powerful but difficult to use. If you can wait a few hours, then use batch processing and a data base such Hive or Tajo; then use Kylin to accelerate your OLAP queries to make them more interactive. If that’s not enough and you need even lower latency and real time data, consider OLAP engines. Druid is more suitable for real-time analysis. Kylin is more focused on OLAP cases. Druid has good integration with Kafka as real-time streaming; Kylin fetches data from Hive or Kafka in batches; although real time ingestion is planned for the near future.
Finally, Greenplum is another OLAP engine with more focus on AI.
Finally, for visualization you have several commercial tools such Qlik, Looker or Tableau. For Open Source, check SuperSet, an amazing tool that support all the tools we mentioned, has a great editor and it is really fast. Metabase or Falcon are other great options.
Conclusion
We have talked a lot about data: the different shapes, formats, how to process it, store it and much more. Remember: Know your data and your business model. Use an iterative process and start building your big data platform slowly; not by introducing new frameworks but by asking the right questions and looking for the best tool which gives you the right answer.
Review the different considerations for your data, choose the right storage based on the data model (SQL), the queries(NoSQL), the infrastructure and your budget. Remember to engage with your cloud provider and evaluate cloud offerings for big data(buy vs. build). It is very common to start with a Serverless analysis pipeline and slowly move to open source solutions as costs increase.
Data Ingestion is critical and complex due to the dependencies to systems outside of your control; try to manage those dependencies and create reliable data flows to properly ingest data. If possible have other teams own the data ingestion. Remember to add metrics, logs and traces to track the data. Enable schema evolution and make sure you have setup proper security in your platform.
Use the right tool for the job and do not take more than you can chew. Tools like Cassandra, Druid or ElasticSearch are amazing technologies but require a lot of knowledge to properly use and manage. If you just need to OLAP batch analysis for ad-hoc queries and reports, use Hive or Tajo. If you need better performance, add Kylin. If you also need to join with other data sources add query engines like Drill or Presto. Furthermore, if you need to query real time and batch use ClickHouse, Druid or Pinot.
Feel free to get in touch if you have any questions or need any advice.
I hope you enjoyed this article. Feel free to leave a comment or share this post. Follow me for future post.
'Data Analytics(en)' 카테고리의 다른 글
| How To Make Money Using Web Scraping (0) | 2020.10.12 |
|---|---|
| Automating your daily tasks with Python (0) | 2020.10.11 |
| 5 Underrated Apps for Programmers You Should Use Right Now (0) | 2020.10.09 |
| 🔝Top 29 Useful Python Snippets 🔝 That Save You Time (0) | 2020.10.08 |
| You are telling people that you are a Python beginner if you ask this question. (0) | 2020.10.07 |