소개
시작하는 경우빅 데이터선택할 수있는 많은 도구, 프레임 워크 및 옵션에 압도당하는 것이 일반적입니다. 이 기사에서 나는성분그리고기본 레시피빅 데이터 여정을 시작할 수 있습니다. 제 목표는 다양한 도구를 분류하고 각 도구의 목적과 생태계 내에서 어떻게 적용되는지 설명하는 것입니다.
먼저 몇 가지 고려 사항을 검토하고 실제로 빅 데이터 문제.나는 집중할 것이다오픈 소스배포 할 수있는 솔루션온 프레미스. 클라우드 제공 업체는 데이터 요구 사항에 대한 여러 솔루션을 제공하며 이에 대해 약간 언급하겠습니다. 클라우드에서 실행중인 경우 실제로 사용할 수있는 옵션을 확인하고 비용, 운용성, 관리 용이성, 모니터링 및 출시 시간 차원을 살펴 보는 오픈 소스 솔루션과 비교해야합니다.
데이터 고려 사항
(빅 데이터에 대한 경험이 있다면 다음 섹션으로 건너 뛰십시오…)
빅 데이터는 복잡합니다, 당신이 절대적으로 필요하지 않는 한 그것에 뛰어 들지 마십시오. 통찰력을 얻으려면 작게 시작하거나탄력적 검색과프로 메테우스/Grafana정보 수집을 시작하고 대시 보드를 만들어 비즈니스에 대한 정보를 얻을 수 있습니다. 데이터가 확장됨에 따라 이러한 도구는 유지 관리하기에 충분하지 않거나 비용이 너무 많이들 수 있습니다. 이것은 당신이 고려를 시작해야 할 때입니다데이터 레이크 또는 데이터웨어 하우스;시작하기 위해 마음을 바꿔생각 큰.
을 체크하다데이터 양, 얼마나 보유하고 있으며 얼마나 오래 보관해야합니까? 을 체크하다온도! 시간이 지남에 따라 가치가 손실되는 경우 데이터를 얼마 동안 저장해야합니까? 얼마나 많은 스토리지 레이어 (핫 / 웜 / 콜드)가 필요합니까? 데이터를 보관하거나 삭제할 수 있습니까?
다른질문다음과 같이 자문 해보십시오. 어떤 유형의 데이터를 저장하고 있습니까? 어떤 형식을 사용하십니까? 법적 의무가 있습니까? 데이터를 얼마나 빨리 수집해야합니까? 쿼리에 사용할 수있는 데이터가 얼마나 빨리 필요합니까? 어떤 유형의 쿼리를 기대하십니까? OLTP 또는 OLAP? 인프라 제한은 무엇입니까? 귀하의 데이터는 어떤 유형입니까? 관계? 그래프? 문서? 시행 할 스키마가 있습니까?
이에 대해 여러 기사를 쓸 수 있습니다. 데이터를 이해하는 것이 매우 중요합니다.경계이 레시피가 작동하려면, 요구 사항, 의무 등이 있습니다.
데이터음량하루에 수십억 개의 이벤트 또는 방대한 데이터 세트를 처리하는 경우 파이프 라인에 빅 데이터 원칙을 적용해야합니다. 하나,"를 구분하는 단일 경계가 없습니다.작은"에서"큰”데이터및 기타 측면속도, 귀하의팀 조직, 크기회사, 필요한 분석 유형,하부 구조아니면 그비즈니스 목표빅 데이터 여정에 영향을 미칠 것입니다. 그중 일부를 검토해 보겠습니다.
OLTP 대 OLAP
몇 년 전, 기업은 사용자 및 기타 구조화 된 데이터를 저장하는 데 사용되는 관계형 데이터베이스 (OLTP). 하룻밤 사이에이 데이터는 복잡한 작업을 사용하여데이터웨어 하우스데이터 분석 및 비즈니스 인텔리전스 (OLAP). 기록 데이터는 데이터웨어 하우스에 복사되어 비즈니스 의사 결정에 사용되는 보고서를 생성하는 데 사용되었습니다.
데이터웨어 하우스와 데이터 레이크
데이터가 증가함에 따라 데이터웨어 하우스는 비용이 많이 들고 관리가 어려워졌습니다. 또한 기업들은 이미지 나 로그와 같은 비정형 데이터를 저장하고 처리하기 시작했습니다. 와빅 데이터, 회사는데이터 레이크구조화 된 데이터와 구조화되지 않은 데이터를 중앙 집중화하여 모든 데이터가 포함 된 단일 저장소를 만듭니다.
간단히 말해 데이터 레이크는 데이터를 저장하는 컴퓨터 노드의 집합입니다.하아 파일 시스템및 세트도구데이터를 처리하고 통찰력을 얻을 수 있습니다. 기반지도 축소도구의 거대한 생태계불꽃상용 하드웨어를 사용하여 모든 유형의 데이터를 처리하기 위해 만들어졌습니다.비용 효과적아이디어는 저렴한 하드웨어에서 데이터를 처리하고 저장 한 다음 데이터베이스를 사용하지 않고 나중에 논의 할 파일 형식과 외부 스키마에 의존하여 저장된 파일을 직접 쿼리 할 수 있다는 것입니다. Hadoop은HDFS비용 효율적인 방식으로 데이터를 저장하는 파일 시스템.
에 대한OLTP, 최근 몇 년 동안NoSQL, 데이터베이스 사용MongoDB또는카산드라SQL 데이터베이스의 한계를 넘어 확장 할 수 있습니다. 하나,최근 데이터베이스는 많은 양의 데이터를 처리 할 수 있습니다., OLTP 및 OLAP 모두에 사용할 수 있습니다.스트림 및 배치 처리 모두에 대한 저렴한 비용;같은 트랜잭션 데이터베이스도YugaByteDB엄청난 양의 데이터를 처리 할 수 있습니다. 시스템, 애플리케이션, 소스 및 데이터 유형이 많은 대기업은 분석 요구 사항을 충족하기 위해 데이터웨어 하우스 및 / 또는 데이터 레이크가 필요하지만 회사에 정보 채널이 너무 많지 않거나 클라우드에서 운영하는 경우에는 하나의 대규모 데이터베이스로 충분할 수 있습니다.단순화당신의 아키텍처와 과감하게비용 절감.
Hadoop 또는 No Hadoop
2006 년 출시 이후하둡빅 데이터 세계의 주요 기준이되었습니다. 를 기반으로MapReduce간단한 프로그래밍 모델을 사용하여 많은 양의 데이터를 처리 할 수 있습니다. 생태계는 수년에 걸쳐 기하 급수적으로 성장하여 모든 사용 사례를 처리 할 수있는 풍부한 생태계를 만들었습니다.
최근에 몇 가지비판Hadoop 생태계의 사용이 지난 몇 년 동안 감소하고 있음이 분명합니다. 새로운OLAP자체 데이터 형식을 사용하여 매우 짧은 지연 시간으로 수집 및 쿼리 할 수있는 엔진이 Hadoop에서 가장 일반적인 쿼리 엔진 중 일부를 대체하고 있습니다. 하지만 가장 큰 영향은서버리스 분석빅 데이터 작업을 수행 할 수있는 클라우드 제공 업체에서 출시 한 솔루션인프라 관리없이.
Hadoop 생태계의 규모와 거대한 사용자 기반을 감안할 때, 그것은 죽지 않은 것처럼 보이며 많은 새로운 솔루션은 호환 가능한 API를 만들고 Hadoop 생태계와 통합하는 것 외에는 선택의 여지가 없습니다. HDFS는 생태계의 핵심이지만 클라우드 제공 업체가 더 저렴하고 더 나은 딥 스토리지 시스템을 구축했기 때문에 이제 온 프레미스에서만 사용됩니다.S3또는GCS. 클라우드 제공 업체는 또한관리 형 Hadoop 클러스터상자 밖으로. 따라서 Hadoop은 여전히 살아 있고 시작되지만 Hadoop 생태계 구축을 시작하기 전에 다른 새로운 대안이 있다는 점을 염두에 두어야합니다. 이 기사에서는 어떤 도구가 Hadoop 에코 시스템의 일부인지, 어떤 도구가 호환되는지, 어떤 도구가 Hadoop 에코 시스템의 일부가 아닌지 언급하려고합니다.
배치 대 스트리밍
데이터 온도 분석에 따라 실시간 스트리밍, 일괄 처리 또는 많은 경우에 필요한지 결정해야합니다.양자 모두.
완벽한 세상에서는 실시간으로 실시간 데이터에서 모든 통찰력을 얻고 창 기반 집계를 수행합니다. 그러나 일부 사용 사례에서는 이것이 불가능하고 다른 경우에는 비용 효율적이지 않습니다. 이것이 많은 기업이일괄 처리와 스트림 처리 모두 사용. 비즈니스 요구 사항을 확인하고 자신에게 더 적합한 방법을 결정해야합니다. 예를 들어 일부 보고서를 작성해야하는 경우 일괄 처리로 충분합니다.배치가 더 간단하고 저렴합니다..
최신 처리 엔진은Apache Flink또는Apache Beam, 일컬어4 세대 빅 데이터 엔진, 일괄 처리가 24 시간마다 수행되는 스트림 처리 인 일괄 및 스트리밍 데이터에 대한 통합 프로그래밍 모델을 제공합니다. 이것은 프로그래밍 모델을 단순화합니다.
일반적인 패턴은보고 및 분석을 위해 신용 카드 사기 및 배치와 같은 시간이 중요한 인사이트를위한 스트리밍 데이터를 보유하는 것입니다. 최신 OLAP 엔진을 사용하면 통합 된 방식으로 두 가지를 모두 쿼리 할 수 있습니다.
ETL 대 ELT
사용 사례에 따라 다음을 수행 할 수 있습니다.로드 또는 읽기시 데이터 변환. ELT는 쿼리의 일부로 데이터를 변환하고 집계하는 쿼리를 실행할 수 있음을 의미합니다. SQL을 사용하여 함수를 적용하고, 데이터를 필터링하고, 열 이름을 바꾸고, 뷰를 생성하는 등의 작업을 수행 할 수 있습니다. 이는 BigData OLAP 엔진에서 가능합니다. ELT 방식으로 실시간 및 일괄 쿼리를 수행하는 방법을 제공합니다. 다른 옵션은로드시 데이터를 변환하는 것입니다 (ETL)하지만 처리 중에 조인 및 집계를 수행하는 것은 간단한 작업이 아닙니다. 일반적으로데이터웨어 하우스는 ETL을 사용합니다.고정 된 스키마 (별 또는 눈송이)가 필요한 경향이있는 반면데이터 레이크는 더 유연하고 읽기시 ELT 및 스키마를 수행 할 수 있습니다..
각 방법에는 고유 한 장점과 단점이 있습니다. 요컨대, 읽기에 대한 변환 및 집계는 느리지 만 더 많은 유연성을 제공합니다. 쿼리 속도가 느린 경우 처리 단계에서 사전 조인 또는 집계가 필요할 수 있습니다. 나중에 설명하는 OLAP 엔진은 수집 중에 사전 집계를 수행 할 수 있습니다.
팀 구조 및 방법론
마지막으로회사 정책, 조직, 방법론, 인프라, 팀 구조 및 기술은 빅 데이터 결정에 중요한 역할을합니다.. 예를 들어, 파이프 라인을 생성해야하지만 엄청난 양의 데이터를 처리 할 필요가없는 데이터 문제가있을 수 있습니다.이 경우 수집, 강화 및 변환을 더 쉬운 단일 파이프 라인; 그러나 회사에 이미 데이터 레이크가있는 경우 기존 플랫폼을 사용할 수 있습니다. 이는 처음부터 구축 할 수 없습니다.
또 다른 예는 ETL 대 ELT입니다. 개발자는 데이터를 간단한 형식으로 쿼리 할 준비가 된 ETL 시스템을 구축하는 경향이 있으므로 비 기술 직원이 대시 보드를 구축하고 통찰력을 얻을 수 있습니다. 그러나 강력한 데이터 분석 팀과 소규모 개발자 팀이있는 경우 개발자가 수집에만 집중하는 ELT 접근 방식을 선호 할 수 있습니다. 데이터 분석가는 복잡한 쿼리를 작성하여 데이터를 변환하고 집계합니다. 이는 빅 데이터 여정에서 팀 구조와 기술을 고려하는 것이 얼마나 중요한지 보여줍니다.
데이터는 전체 조직에서 교차 기능적 측면이므로 서로 다른 기술과 배경을 가진 다양한 팀이 함께 작업하는 것이 좋습니다.데이터 레이크는 데이터 거버넌스 및 보안을 유지하면서 손쉬운 협업을 가능하게하는 데 매우 뛰어납니다..
성분
빅 데이터 세계의 여러 측면을 검토 한 후 기본 요소가 무엇인지 살펴 보겠습니다.
정보 저장소)
가장 먼저 필요한 것은 모든 데이터를 저장할 장소입니다. 안타깝게도 고객의 요구에 맞는 단일 제품이 없기 때문에 사용 사례에 따라 적합한 스토리지를 선택해야합니다.
실시간데이터 수집, 실시간 이벤트를 저장하기 위해 추가 로그를 사용하는 것이 일반적입니다. 가장 유명한 엔진은카프카. 대안은Apache 펄서. 둘 다 스트리밍 기능을 제공 할뿐만 아니라 이벤트를위한 스토리지도 제공합니다. 이것은 비용 효율적이지 않기 때문에 일반적으로 핫 데이터 (데이터 온도를 기억하십시오!)를위한 단기 저장입니다. 다른 도구가 있습니다.Apache NiFi자체 스토리지가있는 데이터를 수집하는 데 사용됩니다. 결국 추가 로그에서 데이터는 데이터베이스 또는 파일 시스템이 될 수있는 다른 스토리지로 전송됩니다.
대규모 데이터베이스
그러나 Hadoop HDFS는 데이터 레이크를위한 가장 일반적인 형식입니다. 대규모 데이터베이스는 파일 시스템 대신 데이터 파이프 라인의 백엔드로 사용할 수 있습니다. 내 이전 기사 확인대규모 데이터베이스 자세한 내용은. 요약하면카산드라,YugaByteDB또는BigTable대량의 데이터를 데이터 레이크보다 훨씬 빠르게 보관하고 처리 할 수 있지만 저렴하지는 않습니다. 그러나 데이터 레이크 파일 시스템과 데이터베이스 간의 가격 격차는 매년 점점 더 작아지고 있습니다. 이것은 당신이 당신의 일부로 고려해야 할 것입니다Hadoop / NoHadoop 결정. 점점 더 많은 기업이 데이터 요구 사항을 위해 데이터 레이크 대신 빅 데이터 데이터베이스를 선택하고 보관 용으로 만 딥 스토리지 파일 시스템을 사용하고 있습니다.
데이터베이스 및 저장소 옵션을 요약하려면Hadoop 생태계 외부고려해야 할 사항은 다음과 같습니다.
- 카산드라:대량의 데이터를 저장할 수있는 NoSQL 데이터베이스는 최종 일관성과 다양한 구성 옵션을 제공합니다. OLTP에 적합하지만 사전 계산 된 집계 (유연하지 않음)가있는 OLAP에 사용할 수 있습니다. 대안은ScyllaDB훨씬 빠르고 좋습니다.OLAP(고급 스케줄러)
- YugaByteDB: 글로벌 트랜잭션을 처리 할 수있는 대규모 관계형 데이터베이스. 관계형 데이터를위한 최상의 옵션입니다.
- MongoDB: 강력한 문서 기반 NoSQL 데이터베이스, 수집 (임시 저장) 또는 대시 보드의 빠른 데이터 레이어로 사용 가능
- InfluxDB시계열 데이터의 경우.
- 프로 메테우스모니터링 데이터.
- ElasticSearch: 대용량 데이터를 저장할 수있는 분산 형 반전 인덱스. 때때로 많은 사람들이 무시하거나 로그 스토리지로만 사용되는 ElasticSearch는 OLAP 분석, 기계 학습, 로그 스토리지, 비정형 데이터 스토리지 등을 포함한 광범위한 사용 사례에 사용될 수 있습니다. 빅 데이터 생태계에 꼭 필요한 도구입니다.
차이점을 기억하십시오SQL 및 NoSQL,NoSQL 세계에서는 데이터를 모델링하지 않고 쿼리를 모델링합니다.
Hadoop 데이터베이스
HBase가장 인기있는 데이터베이스입니다.Hadoop 생태계 내부. 컬럼 형식으로 많은 양의 데이터를 보유 할 수 있습니다. 기반BigTable.
파일 시스템(딥 스토리지)
에 대한데이터 레이크, Hadoop 에코 시스템에서HDFS파일 시스템이 사용됩니다. 그러나 대부분의 클라우드 제공 업체는이를 자체 딥 스토리지 시스템으로 교체했습니다.S3또는GCS.
이러한 파일 시스템 또는 딥 스토리지 시스템은 데이터베이스보다 저렴하지만 기본 스토리지 만 제공하고 강력한산보증.
필요와 예산에 따라 사용 사례에 적합한 스토리지를 선택해야합니다. 예를 들어 예산이 허용되는 경우 수집을 위해 데이터베이스를 사용할 수 있으며 데이터가 변환되면 OLAP 분석을 위해 데이터 레이크에 저장합니다. 또는 관계형 데이터베이스와 같은 빠른 스토리지 시스템에 모든 것을 딥 스토리지에 저장하지만 핫 데이터의 작은 하위 집합을 저장할 수 있습니다.
파일 형식
사용하는 경우 또 다른 중요한 결정HDFS파일을 저장하는 데 사용할 형식입니다. 딥 스토리지 시스템은 데이터를 파일로 저장하고 다른 파일 형식과 압축 알고리즘은 특정 사용 사례에 이점을 제공합니다.데이터 레이크에 데이터를 저장하는 방법은 중요합니다.그리고 당신은 고려할 필요가 있습니다체재,압축특히어떻게분할귀하의 데이터.
가장 일반적인 형식은 CSV, JSON,AVRO,프로토콜 버퍼,쪽매 세공, 및ORC.
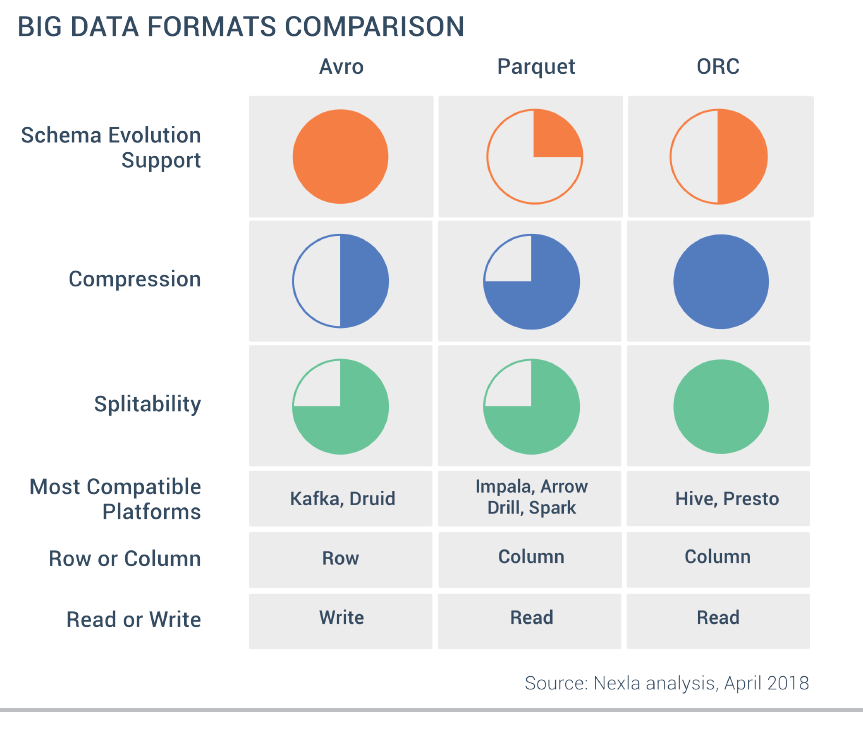
형식을 선택할 때 고려해야 할 사항은 다음과 같습니다.
- 데이터 구조: 일부 형식은 JSON, Avro 또는 Parquet와 같은 중첩 데이터를 허용하고 다른 형식은 허용하지 않습니다. 심지어 그렇게하는 사람들은 그것에 대해 고도로 최적화되지 않을 수 있습니다. Avro는 중첩 된 데이터에 가장 효율적인 형식입니다. Parquet 중첩 유형은 매우 비효율적이므로 사용하지 않는 것이 좋습니다. 프로세스 중첩 JSON도 CPU를 많이 사용합니다. 일반적으로 데이터를 수집 할 때 데이터를 평면화하는 것이 좋습니다.
- 공연: Avro 및 Parquet과 같은 일부 형식은 다른 JSON보다 성능이 뛰어납니다. 다른 사용 사례에 대한 Avro와 Parquet 사이에서도 하나가 다른 것보다 낫습니다. 예를 들어 Parquet는 열 기반 형식이므로 SQL을 사용하여 데이터 레이크를 쿼리하는 것이 좋지만 Avro는 ETL 행 수준 변환에 더 좋습니다.
- 읽기 쉬운: 데이터를 읽을 사람이 필요한지 고려하십시오. JSON 또는 CSV는 텍스트 형식이며 사람이 읽을 수있는 반면 parquet 또는 Avro와 같은보다 성능이 좋은 형식은 바이너리입니다.
- 압축: 일부 형식은 다른 형식보다 높은 압축률을 제공합니다.
- 스키마 진화: 필드 추가 또는 제거는 데이터베이스보다 데이터 레이크에서 훨씬 더 복잡합니다. Avro 또는 Parquet과 같은 일부 형식은 데이터 스키마를 변경하고 데이터를 쿼리 할 수있는 어느 정도의 스키마 진화를 제공합니다. 이러한 도구Delta Lake형식은 스키마 변경을 처리하는 더 나은 도구를 제공합니다.
- 적합성: JSON 또는 CSV는 널리 채택되어 거의 모든 도구와 호환되며 성능이 높은 옵션은 통합 지점이 적습니다.
보시다시피 CSV 및 JSON은 사용하기 쉽고 사람이 읽을 수있는 일반적인 형식이지만 다른 형식의 기능이 부족하여 데이터 레이크를 쿼리하는 데 너무 느립니다.ORC와 마루Hadoop 생태계에서 널리 사용되어쿼리 데이터이므로AvroHadoop 외부에서도 사용되며, 특히 Kafka와 함께 수집에 사용됩니다.행 레벨 ETL처리. 행 지향 형식은 열 지향 형식보다 더 나은 스키마 진화 기능을 가지고있어 데이터 수집을위한 훌륭한 옵션입니다.
마지막으로 다음 방법도 고려해야합니다.파일의 데이터 압축파일 크기와 CPU 비용 간의 균형을 고려합니다. 일부 압축 알고리즘은 더 빠르지 만 파일 크기가 더 크고 다른 알고리즘은 더 느리지 만 압축률이 더 좋습니다. 자세한 내용은 여기를 확인하십시오조.
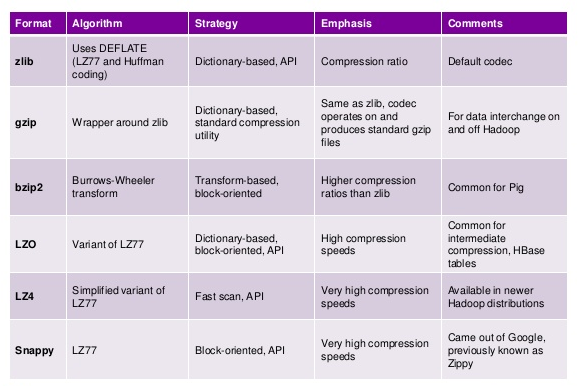
CPU 성능이 너무 많이 필요하지 않기 때문에 스트리밍 데이터에 snappy를 사용하는 것이 좋습니다. 배치의 경우 bzip2는 훌륭한 옵션입니다.
다시 말씀 드리지만, 앞서 언급 한 고려 사항을 검토하고 검토 한 모든 측면을 기반으로 결정해야합니다. 몇 가지 사용 사례를 예로 들어 보겠습니다.
사용 사례
- ETL 파이프 라인의 일부로 추가 처리를 위해 어딘가에서 실시간 데이터 및 스토리지를 수집해야합니다. 성능이 중요하고 예산이 문제가되지 않는다면 Cassandra를 사용할 수 있습니다. 표준 접근 방식은 최적화 된 형식을 사용하여 HDFS에 저장하는 것입니다.AVRO.
- 대기 시간이 중요한 (OLTP) 쿼리를 알고있는 고도의 대화 형 사용자 대면 애플리케이션에서 사용할 어딘가에서 데이터와 스토리지를 처리해야합니다. 이 경우 데이터 볼륨에 따라 Cassandra 또는 다른 데이터베이스를 사용하십시오.
- 처리 된 데이터를 사용자 기반에 제공해야하며 일관성이 중요하며 UI가 고급 쿼리를 제공하기 때문에 쿼리를 미리 알지 못합니다. 이 경우 관계형 SQL 데이터베이스가 필요합니다. 사용자 측에 따라 MySQL과 같은 기존 SQL DB로 충분하거나 YugaByteDB 또는 기타 관계형 대규모 데이터베이스를 사용해야 할 수도 있습니다.
- 내부 팀이 임시 쿼리를 실행하고 보고서를 만들 수 있도록 OLAP 분석을 위해 처리 된 데이터를 저장해야합니다. 이 경우 데이터를 Parquet 또는 ORC 형식으로 딥 스토리지 파일 시스템에 저장할 수 있습니다.
- 기록 데이터의 임시 쿼리를 실행하려면 SQL을 사용해야하지만 1 초 이내에 응답해야하는 대시 보드도 필요합니다. 이 경우 MySQL 데이터베이스와 같은 빠른 스토리지에 데이터의 하위 집합을 저장하고 데이터 레이크에 Parquet 형식의 기록 데이터를 저장하는 하이브리드 접근 방식이 필요합니다. 그런 다음 쿼리 엔진을 사용하여 SQL을 사용하여 여러 데이터 원본을 쿼리합니다.
- 몇 밀리 초 만에 응답해야하는 매우 복잡한 쿼리를 수행해야하며 읽기시 집계를 수행해야 할 수도 있습니다. 이 경우 ElasticSearch를 사용하여 데이터 또는 다음과 같은 최신 OLAP 시스템을 저장하십시오.아파치 피노나중에 논의 할 것입니다.
- 구조화되지 않은 텍스트를 검색해야합니다. 이 경우 ElasticSearch를 사용하십시오.
하부 구조
현재 인프라는 사용할 도구를 결정할 때 옵션을 제한 할 수 있습니다. 첫 번째 질문은 다음과 같습니다.클라우드 대 온 프레미스. 클라우드 제공 업체는 다양한 옵션과 유연성을 제공합니다. 또한 관리 및 모니터링이 더 쉬운 빅 데이터 요구 사항에 대한 서버리스 솔루션을 제공합니다. 확실히 클라우드는 빅 데이터를위한 장소입니다. Hadoop 에코 시스템에서도클라우드 제공 업체는 관리 형 클러스터를 제공합니다.온 프레미스보다 스토리지가 저렴합니다. 클라우드 솔루션에 관한 다른 기사를 확인하십시오.
실행중인 경우온 프레미스다음에 대해 생각해야합니다.
- 내 워크로드는 어디에서 실행합니까?명확히Kubernetes또는Apache메 소스 통합 된 오케스트레이션 프레임 워크를 제공하여 통합 된 방식으로 애플리케이션을 실행합니다. 배포, 모니터링 및 경고 측면은 사용하는 프레임 워크에 관계없이 동일합니다. 반면 베어 메탈에서 실행하는 경우 배포의 모든 교차 절단 측면을 생각하고 관리해야합니다. 이 경우 관리되는 클러스터 및 도구가 라이브러리 및 프레임 워크보다 더 적합합니다.
- 어떤 유형의 하드웨어가 있습니까?빠른 SSD와 고급 서버를 갖춘 특수 하드웨어가 있다면 Cassandra와 같은 방대한 데이터베이스를 배포하고 뛰어난 성능을 얻을 수 있습니다. 상용 하드웨어 만 소유하고 있다면 Hadoop 에코 시스템이 더 나은 옵션이 될 것입니다. 이상적으로는 다양한 워크로드에 대해 여러 유형의 서버를 보유하고자합니다. Cassandra에 대한 요구 사항은 HDFS와 크게 다릅니다.
모니터링 및 경고
다음 요소는 데이터 파이프 라인의 성공에 필수적입니다. 빅 데이터 세계에서지속적인 피드백이 필요합니다프로세스와 데이터에 대해. 당신은메트릭 수집, 로그 수집,시스템을 모니터링하고경고,대시 보드그리고 훨씬 더.
다음과 같은 오픈 소스 도구 사용Prometheus과Grafana모니터링 및 경고 용. 로그 집계 기술을 사용하여 로그를 수집하고 다음과 같은 곳에 저장합니다.ElasticSearch.
클라우드 공급자 기능 활용for monitoring and alerting when possible. Depending on your platform you will use a different set of tools. For Cloud Serverless platform you will rely on your cloud provider tools and best practices. For Kubernetes, you will use open source monitor solutions or enterprise integrations. I really recommend this 웹 사이트다양한 솔루션을 찾아보고 확인하고 자신 만의APM해결책.
Another thing to consider in the Big Data world is auditability and accountability. Because of different regulations, you may be required to trace the data, capturing and recording every change as data flows through the pipeline. This is called data provenance or lineage. Tools like Apache Atlas are used to control, record and govern your data. Other tools such Apache NiFi데이터 계보를 즉시 지원합니다. 에 대한실시간 추적,검사개방형 원격 측정또는저격병.또한 많은 클라우드 서비스가 있습니다. Datadog.
Hadoop 사용의 경우Ganglia.
보안
아파치 레인저 Hadoop 플랫폼을위한 통합 보안 모니터링 프레임 워크를 제공합니다. 중앙 UI에서 모든 보안 관련 작업을 관리 할 수있는 중앙 집중식 보안 관리를 제공합니다. 그것은 제공합니다권한 부여다양한 방법을 사용하고 전체 Hadoop 플랫폼에서 완전한 감사 기능을 사용합니다.
사람들
당신의 팀은 성공의 열쇠입니다. 빅 데이터 엔지니어는 찾기 어려울 수 있습니다. 교육, 숙련도 향상, 워크샵에 투자하십시오. 사일로와 관용구를 제거하고 반복을 간단하게 만들고 사용Domain Driven Design팀 경계와 책임을 설정합니다.
For Big Data you will have 두 가지 넓은 범주:
- 데이터 엔지니어섭취, 농축 및 변형을 위해. 이 엔지니어들은강력한 개발 및 운영 배경and are in charge of creating the data pipeline. Developers, Administrators, DevOps specialists, etc will fall in this category.
- Data Scientist: These can be BI specialists, data analysts, etc. in charge of generation reports, dashboards and gathering insights. Focused on OLAP and with strong business understanding, these people gather the data which will be used to make critical business decisions. SQL에 강함 and visualization but weak in software development. 기계 학습 specialists may also fall into this category.
Budget
이것은 중요한 고려 사항이며 다른 모든 재료를 구입하려면 돈이 필요하며 제한된 자원입니다. 무제한의 돈이 있다면 방대한 데이터베이스를 배포하여 많은 복잡성없이 빅 데이터 요구 사항에 사용할 수 있지만 비용이 많이 듭니다. 따라서이 기사에서 언급 한 각 기술은 사용, 배포 및 유지 관리 할 수있는 기술을 가진 사람이 필요합니다. 일부 기술은 다른 기술보다 더 복잡하므로이 점을 고려해야합니다.
Recipe
이제 재료가 준비 되었으니 빅 데이터 레시피를 만들어 보겠습니다. 안에nutshell과정은 간단합니다. 다른 소스에서 데이터를 수집하고, 보강하고, 어딘가에 저장하고, 메타 데이터 (스키마)를 저장하고, 정리하고, 정규화하고, 처리하고, 잘못된 데이터를 격리하고, 데이터를 최적으로 집계하고, 최종적으로 다운 스트림 시스템에서 사용할 어딘가에 저장해야합니다. .
각 단계에 대해 좀 더 자세히 살펴 보겠습니다.
Ingestion
The first step is to get the data,이 단계의 목표는 필요한 모든 데이터를 가져와 단일 저장소에 원시 형식으로 저장하는 것입니다.This is usually owned by other teams who push their data into Kafka or a data store.
For simple pipelines with not huge amounts of data you can build a simple microservices workflow that can ingest, enrich and transform the data in a single pipeline(ingestion + transformation), you may use tools such Apache Airflow to orchestrate the dependencies. However, for Big Data it is recommended that you separate ingestion from processing, massive processing engines that can run in parallel are not great to handle blocking calls, retries, back pressure, etc. So, it is recommended that all the data is saved before you start processing it. You should enrich your data as part of the ingestion by calling other systems to make sure all the data, including reference data has landed into the lake before processing.
There are two modes of ingestion:
- Pull: Pull the data from somewhere like a database, file system, a queue or an API
- Push: Applications can also push data into your lake but it is always recommended to have a messaging platform as Kafka in between. A common pattern is Change Data Capture(CDC) which allows us to move data into the lake in real time from databases and other systems.
As we already mentioned, It is extremely common to use Kafka or Pulsar as a mediator for your data ingestion to enable persistence, back pressure, parallelization and monitoring of your ingestion. Then, use Kafka Connect to save the data into your data lake. The idea is that your OLTP systems will publish events to Kafka and then ingest them into your lake. Avoid ingesting data in batch directly through APIs; you may call HTTP end-points for data enrichment but remember that ingesting data from APIs it’s not a good idea in the big data world because it is slow, error prone(network issues, latency…) and can bring down source systems. Although, APIs are great to set domain boundaries in the OLTP world, these boundaries are set by data stores(batch) or topics(real time) in Kafka in the Big Data world. Of course, it always depends on the size of your data but try to use Kafka or Pulsar when possible and if you do not have any other options; pull small amounts of data in a streaming fashion from the APIs, not in batch. For databases, use tools such Debezium to stream data to Kafka (CDC).
To minimize dependencies, it is always easier if the source system push data to Kafka rather than your team pulling the data since you will be tightly coupled with the other source systems. If this is not possible and you still need to own the ingestion process, we can look at two broad categories for ingestion:
- Un Managed Solutions: These are applications that you develop to ingest data into your data lake; you can run them anywhere. This is very common when ingesting data from APIs or other I/O blocking systems that do not have an out of the box solution, or when you are not using the Hadoop ecosystem. The idea is to use streaming libraries to ingest data from different topics, end-points, queues, or file systems. Because you are developing apps, you have full flexibility. Most libraries provide retries, back pressure, monitoring, batching and much more. This is a code yourself approach, so you will need other tools for orchestration and deployment. You get more control and better performance but more effort involved. You can have a single monolith or microservices communicating using a service bus or orchestrated using an external tool. Some of the libraries available are Apache Camel or Akka Ecosystem (Akka HTTP + Akka Streams + Akka Cluster + Akka Persistence + Alpakka). You can deploy it as a monolith or as microservices depending on how complex is the ingestion pipeline. If you use Kafka or Pulsar, you can use them as ingestion orchestration tools to get the data and enrich it. Each stage will move data to a new topic creating a DAG in the infrastructure itself by using topics for dependency management. If you do not have Kafka and you want a more visual workflow you can use Apache Airflow to orchestrate the dependencies and run the DAG. The idea is to have a series of services that ingest and enrich the date and then, store it somewhere. After each step is complete, the next one is executed and coordinated by Airflow. Finally, the data is stored in some kind of storage.
- Managed Solutions:이 경우 클러스터에 배포되고 수집에 사용되는 도구를 사용할 수 있습니다. 이는 다음과 같은 도구가있는 Hadoop 에코 시스템에서 일반적입니다.Sqoop to ingest data from your OLTP databases and 플룸 to ingest streaming data. These tools provide monitoring, retries, incremental load, compression and much more.
NiFi is one of these tools that are difficult to categorize. It is a beast on its own. It can be used for ingestion, orchestration and even simple transformations. So in theory, it could solve simple Big Data problems. It is a managed solution. It has a visual interface구성 요소를 드래그 앤 드롭하고이를 사용하여 데이터를 수집하고 강화할 수 있습니다. 그것은 가지고있다over 300 built in processors which perform many tasks and you can extend it by implementing your own.

It has its own architecture, so it does not use any database HDFS but it has integrations with many tools in the Hadoop Ecosystem. You can call APIs, integrate with Kafka, FTP, many file systems and cloud storage. You can manage the data flow performing routing, filtering and basic ETL. For some use cases, NiFi may be all you need.
그러나 NiFi는 클러스터에서 10 개 이상의 노드 간 통신이 비효율적이기 때문에 특정 지점 이상으로 확장 할 수 없습니다. 수직적으로 더 잘 확장되는 경향이 있지만 특히 복잡한 ETL의 경우 한계에 도달 할 수 있습니다. 그러나 Spark와 같은 도구와 통합하여 데이터를 처리 할 수 있습니다.NiFi is a great tool for ingesting and enriching your data.
현대OLAP engines such 드루이드 or 피노또한 배치 및 스트리밍 데이터의 자동 수집을 제공합니다. 이에 대해서는 다른 섹션에서 설명하겠습니다.
You can also do some initial validation and data cleaning during the ingestion, as long as they are not expensive computations or do not cross over the bounded context, remember that a null field may be irrelevant to you but important for another team.
The last step is to decide where to land the data, we already talked about this. You can use a database or a deep storage system. For a data lake, it is common to store it in HDFS, the format will depend on the next step; if you are planning to perform row level operations, Avro훌륭한 옵션입니다. Avro는 또한외부 레지스트리which will allow you to change the schema for your ingested data relatively easily.
메타 데이터
데이터를 저장 한 후 다음 단계는 메타 데이터 (데이터 자체에 대한 정보)를 저장하는 것입니다. 가장 일반적인 메타 데이터는schema. By using an external metadata repository, the different tools in your data lake or data pipeline can query it to infer the data schema.
If you use Avro for raw data, then the external registry좋은 선택입니다. 이렇게하면 처리에서 수집을 쉽게 분리 할 수 있습니다.
데이터가 수집되면 OLAP 엔진에서 쿼리하기 위해 사용하는 것이 매우 일반적입니다. SQL DDL. The most used data lake/data warehouse tool in the Hadoop ecosystem is Apache Hive,which provides a metadata store so you can use the data lake like a data warehouse with a defined schema. You can run SQL queries on top of Hive and connect many other tools such SparkSQL 쿼리를 실행하려면Spark SQL. Hive는 Hadoop 생태계 내에서 중요한 도구입니다.중앙 집중식 메타 데이터베이스분석 쿼리를 위해. 기타 도구Apache TajoHive 위에 구축되어 데이터 레이크에서 데이터웨어 하우징 기능을 제공합니다.
Apache Impala 원주민이다분석 데이터베이스 for Hadoop which provides metadata store, you can still connect to Hive for metadata using Hcatalog.
Apache Phoenixhas also a metastore and can work with Hive. Phoenix focuses on OLTP트랜잭션에 대한 ACID 속성을 사용하여 쿼리를 활성화합니다. 유연하고 다음을 활용하여 NoSQL 세계의 스키마 읽기 기능을 제공합니다.HBase as its backing store. Apache 드루이드또는피노 메타 데이터 저장소도 제공합니다.
가공
이 단계의 목표는단일 스키마를 사용하여 데이터를 정리, 정규화, 처리 및 저장합니다.최종 결과는잘 정의 된 스키마가있는 신뢰할 수있는 데이터 세트.
일반적으로 다음과 같은 처리를 수행해야합니다.
- Validation: 데이터 유효성 검사 및 불량 데이터는 별도의 저장소에 저장하여 격리합니다. 데이터 품질 요구 사항에 따라 특정 임계 값에 도달하면 경고를 보냅니다.
- 랭 글링 및 클렌징: 데이터를 정리하고 추가 처리를 위해 다른 형식으로 저장합니다 (예 : 비효율적 인 JSON을 Avro로 대체).
- 표준화과표준화가치의
- Rename필드
- …
목표는trusted data set that later can be used for downstream systems. This is a key role of a data engineer. This can be done in a stream or batch fashion.
파이프 라인 처리는 다음과 같이 나눌 수 있습니다.세 단계 in case of 일괄 처리:
- 전처리 단계: 원시 데이터가 깨끗하지 않거나 올바른 형식이 아닌 경우 사전 처리해야합니다. 이 단계에는 몇 가지 기본 유효성 검사가 포함되지만 목표는효율적으로 처리 할 데이터 준비다음 단계를 위해. 이 단계에서는 다음을 시도해야합니다.데이터를 평면화하고 이진 형식으로 저장그런 Avro. 이렇게하면 추가 처리 속도가 빨라집니다. 아이디어는 다음 단계에서 행 수준 작업을 수행하고 중첩 쿼리는 비용이 많이 들기 때문에 지금 데이터를 평면화하면 다음 단계 성능이 향상된다는 것입니다.
- 신뢰할 수있는 단계: Data is 검증, 정리, 정규화 및 변환 to a common schema stored in 하이브. The goal is to create a trusted common data set understood by the data owners. Typically, a data 사양데이터 엔지니어의 역할은 사양과 일치하도록 변환을 적용하는 것입니다. 최종 결과는쪽매 세공쉽게 쿼리 할 수있는 형식입니다. 올바른 파티션을 선택하고 데이터를 최적화하여 내부 쿼리를 수행하는 것이 중요합니다. 쿼리 성능을 향상시키기 위해이 단계에서 일부 집계를 부분적으로 미리 계산할 수 있습니다.
- 보고 단계:이 단계는 선택 사항이지만 종종 필수입니다. 안타깝게도 데이터 레이크를 사용할 때a single schema will not serve all use cases; 이것은 데이터웨어 하우스와 데이터 레이크의 한 가지 차이점입니다. HDFS 쿼리는 데이터베이스 또는 데이터웨어 하우스만큼 효율적이지 않으므로 추가 최적화가 필요합니다. 이 단계에서는 다음을 수행해야 할 수 있습니다.비정규 화서로 다른 이해 관계자가 더 효율적으로 쿼리 할 수 있도록 서로 다른 파티션을 사용하여 데이터를 저장합니다. 아이디어는견해다양한 다운 스트림 시스템 (데이터 마트). In this phase you can also compute aggregations if you do not use an OLAP engine (see next section). The trusted phase does not know anything about who will query the data,이 단계는 소비자를 위해 데이터를 최적화합니다.. 클라이언트가 매우 상호 작용적인 경우 다음을 수행 할 수 있습니다.빠른 저장 계층 도입이 단계에서는 빠른 쿼리를위한 관계형 데이터베이스와 같습니다. 또는 나중에 논의 할 OLAP 엔진을 사용할 수 있습니다.
스트리밍의 경우 논리는 동일하지만 정의 된 DAG 내에서 스트리밍 방식으로 실행됩니다. Spark를 사용하면 스트림을 기록 데이터와 조인 할 수 있지만한계. 나중에 논의 할 것입니다.OLAP engines, 실시간 데이터를 기록 데이터와 병합하는 데 더 적합합니다.
Processing Frameworks
처리에 사용할 수있는 도구는 다음과 같습니다.
- Apache Spark: 이것은 일괄 처리를위한 가장 잘 알려진 프레임 워크입니다. Hadoop 에코 시스템의 일부입니다.관리놀라운 제공 클러스터parallelism, 모니터링 및 훌륭한 UI. 또한 스트림 처리 (구조적 스트리밍). 기본적으로 Spark는 메모리에서 MapReduce 작업을 실행하여 일반 MapReduce 성능의 최대 100 배까지 증가합니다. Hive와 통합하여SQLHive 테이블, 뷰를 생성하거나 데이터를 쿼리하는 데 사용할 수 있습니다. 그것은 많은 통합을 가지고 있으며 다양한 형식을 지원하며 거대한 커뮤니티를 가지고 있습니다. 모든 클라우드 제공 업체에서 지원합니다. 실행할 수 있습니다.실Hadoop 클러스터의 일부로, Kubernetes 및 기타 플랫폼에서도 마찬가지입니다. SQL 또는 기계 학습과 같은 특정 사용 사례를위한 많은 라이브러리가 있습니다.
- Apache Flink: The first engine to unify batch and streaming but heavily focus on 스트리밍. Kafka와 같은 마이크로 서비스의 백본으로 사용할 수 있습니다. 실행할 수 있습니다.실Hadoop 클러스터의 일부이지만 처음부터 Kubernetes 또는 Mesos와 같은 다른 플랫폼에 최적화되었습니다. 그것은매우 빠름실시간 스트리밍을 제공하므로 Spark보다 나은 옵션입니다.low latency 스트림 처리, 특히상태 저장 streams. It also has libraries for SQL, Machine Learning and much more.
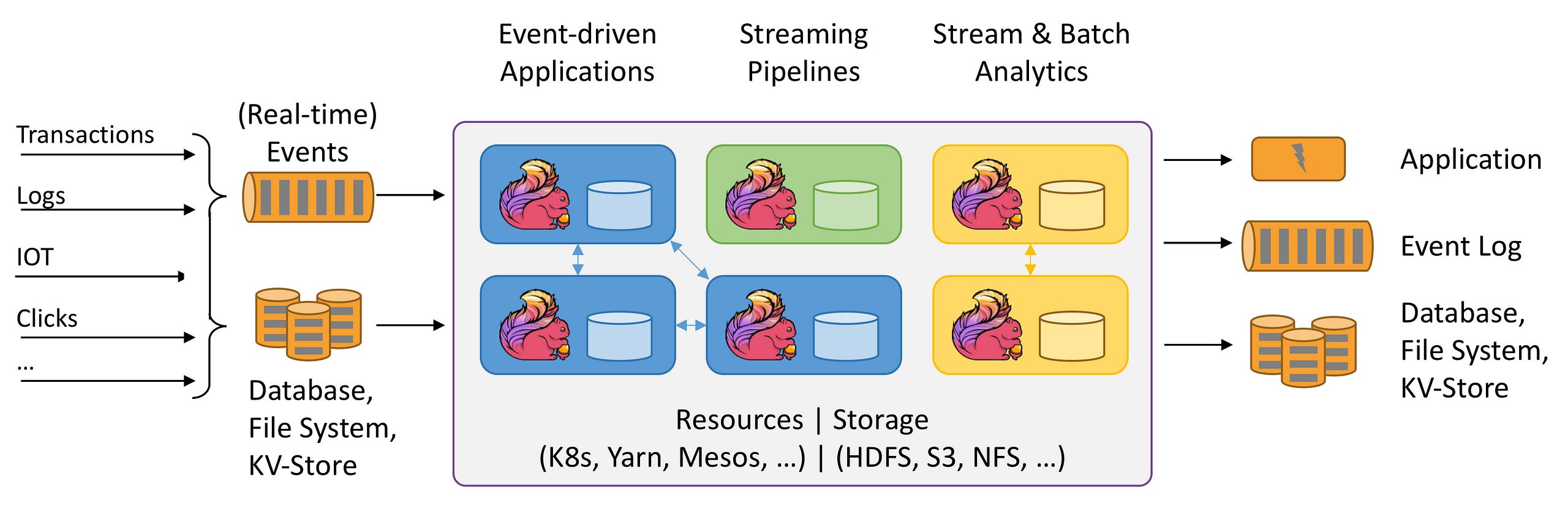
- Apache Storm: Apache Storm은 무료 오픈 소스 분산 실시간 계산 시스템으로 스트리밍에 중점을 두며 Hadoop 생태계의 관리 솔루션 부분입니다. 확장 가능하고 내결함성이 있으며 데이터 처리를 보장하며 설정 및 작동이 쉽습니다.
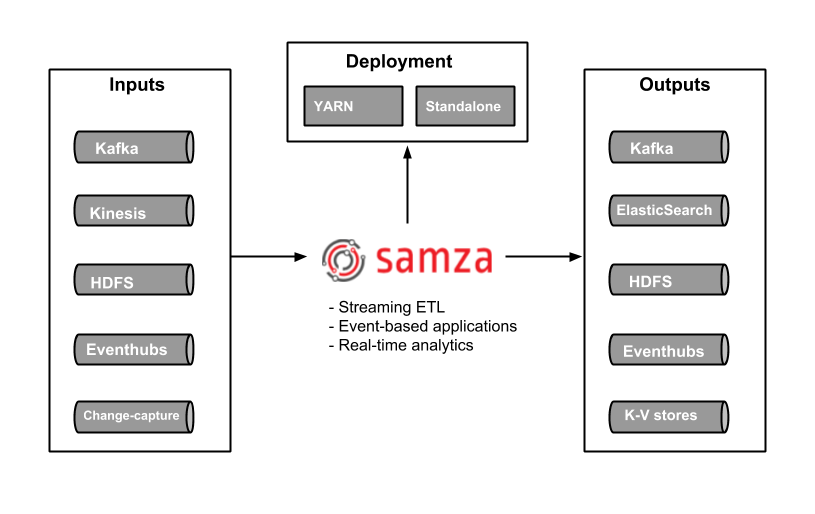
- Apache Samza: 또 다른 훌륭한 상태 저장 스트림 처리 엔진. Samza를 사용하면 Apache Kafka를 비롯한 여러 소스의 데이터를 실시간으로 처리하는 상태 저장 애플리케이션을 빌드 할 수 있습니다. YARN 위에서 실행되는 Hadoop 생태계의 관리 형 솔루션 부분입니다.
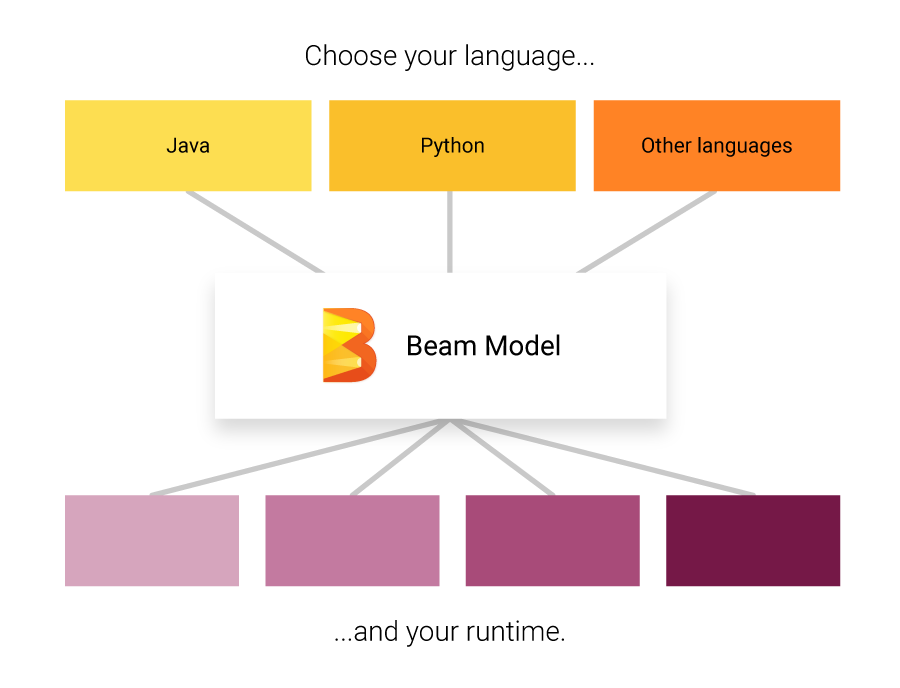
- Apache Beam: Apache Beam은 엔진 자체가 아니라사양의unified programming model다른 모든 엔진을 통합합니다. 다음과 함께 사용할 수있는 프로그래밍 모델을 제공합니다.다른 언어들, 따라서 개발자는 빅 데이터 파이프 라인을 다룰 때 새로운 언어를 배울 필요가 없습니다. 그런 다음 플러그다른 백엔드클라우드 또는 온 프레미스에서 실행할 수있는 처리 단계에 사용됩니다. Beam은 앞서 언급 한 모든 엔진을 지원하며 클라우드, YARN, Mesos, Kubernetes 등 모든 플랫폼에서 쉽게 전환하고 실행할 수 있습니다. 새 프로젝트를 시작하는 경우 데이터 파이프 라인이 미래를 대비할 수 있도록 Beam으로 시작하는 것이 좋습니다.
이 처리 단계가 끝날 때까지 데이터를 요리했고 이제 사용할 준비가되었습니다!하지만 요리를하려면 요리사가 그의 팀과 협력해야합니다.
관현악법
Data pipeline orchestration is a cross cutting process which manages the dependencies between all the other tasks. If you use stream processing, you need to orchestrate the dependencies of each streaming app, for batch, you need to schedule and orchestrate the jobs.
작업 및 응용 프로그램이 실패 할 수 있으므로 다음 방법이 필요합니다.시간표, 일정 변경,다시 하다, 감시 장치, 다시 해 보다통합 된 방식으로 전체 데이터 파이프 라인을 디버깅합니다.
새로운 프레임 워크Dagster또는지사더 많은 기능을 추가하고 파이프 라인에 의미를 추가하는 데이터 자산을 추적 할 수 있습니다.
일부옵션아르:
- Apache Oozie: Oozie 그것은스케줄러Hadoop의 경우 작업은 DAG로 생성되며 시간 또는 데이터 가용성에 따라 트리거 될 수 있습니다. 다음과 같은 수집 도구와 통합되어 있습니다.SqoopSpark와 같은 프레임 워크를 처리합니다.
- Apache Airflow: Airflow는schedule, run and monitor workflows. DAG를 사용하여 복잡한 워크 플로를 만듭니다. 그래프의 각 노드는 작업이며 간선은 작업 간의 종속성을 정의합니다. Airflow 스케줄러는 사용자가 설명하는 지정된 종속성을 따르는 동안 작업자 배열에서 작업을 실행합니다. 최대화를 위해 DAG를 생성합니다.병행. DAG는파이썬,이를 통해 로컬에서 실행하고 단위 테스트하고 개발 워크 플로와 통합 할 수 있습니다. 그것은 또한 지원합니다SLA 및 경고.루이지유사한 기능을 가진 Airflow의 대안이지만 Airflow는 Luigi보다 더 많은 기능을 가지고 있으며 더 잘 확장됩니다.
- Dagster 머신 러닝, 분석 및 ETL을위한 최신 오케 스트레이터입니다. 주요 차이점은 다음과 유사하게 데이터의 입력 및 출력을 추적 할 수 있다는 것입니다.Apache NiFi 데이터 흐름 솔루션을 만듭니다. 작업의 일부로 다른 값을 구체화 할 수도 있습니다. 또한 여러 작업을 병렬로 실행할 수 있으며 매개 변수 추가, 테스트 및 간단한 버전 관리 등을 제공합니다. 아직 미성숙하고 데이터를 추적해야한다는 사실 때문에 확장이 어려울 수 있으며 이는 NiFi와 공유되는 문제입니다.
- 지사 Dagster와 유사하며 로컬 테스트, 버전 관리, 매개 변수 관리 등을 제공합니다. Prefect를 나머지와 다른 점은기류의 한계 개선 된 스케줄러, 매개 변수화 된 워크 플로우, 동적 워크 플로우, 버전 관리 및 개선 된 테스트와 같은 실행 엔진. 핵심 오픈 소스 워크 플로 관리 시스템과구름설정이 전혀 필요하지 않은 제품입니다.
- Apache NiFi: NiFi는 또한 작업을 예약하고, 모니터링하고, 데이터를 라우팅하고, 경고 등을 할 수 있습니다. 데이터 흐름에 중점을 두지 만 일괄 처리도 가능합니다. Hadoop 외부에서 실행되지만 Spark 작업을 트리거하고 HDFS / S3에 연결할 수 있습니다.
요컨대, 요구 사항이 데이터 공유가 필요하지 않은 독립적 인 작업을 조정하는 것이라면 Airflow 또는 Ozzie를 사용하십시오. 데이터 계보 및 추적이 필요한 데이터 흐름 애플리케이션의 경우 개발자가 아닌 경우 NiFi를 사용하고 개발자를위한 Dagster 또는 Prefect를 사용합니다.
데이터 품질
빅 데이터의 중요한 측면 중 하나는 데이터 품질과 보증입니다. 기업은 데이터 품질 문제로 인해 매년 엄청난 돈을 잃습니다. 문제는 이것이 여전히 데이터 과학 분야에서 미성숙 한 분야이고 개발자들은이 분야에서 수십 년 동안 작업 해 왔으며 다음과 같은 훌륭한 테스트 프레임 워크와 방법론을 가지고 있다는 것입니다.BDD또는TDD,하지만 파이프 라인을 어떻게 테스트합니까?
이 분야에는 두 가지 일반적인 문제가 있습니다.
- 오해 된 요구 사항: 종종 변환 및 오케스트레이션 논리가 매우 복잡해질 수 있습니다. 비즈니스 분석가는 종종 실수를 저지르고 기술적으로 정확하지만 요구 사항이 잘못된 솔루션을 계획, 개발, 테스트 및 배포하는 개발자가 해석해야하는 도메인 언어를 사용하여 요구 사항을 작성할 수 있습니다. 이러한 유형의 오류는 비용이 많이 듭니다.
- 데이터 유효성 검사: 파이프 라인 테스트는 코드와 상당히 다릅니다. 소프트웨어를 개발할 때 기능을 테스트하는 것은 결정론적인 블랙 박스 테스트입니다. 주어진 입력에 대해 항상 동일한 출력을 얻습니다. 데이터 자산의 경우 테스트는 더 복잡합니다. 데이터 유형, 값, 제약 조건 등을 주장해야합니다. 또한 집계를 적용하여 데이터 세트를 확인하여 행 또는 열의 수가 올바른지 확인해야합니다. 예를 들어, 언젠가 데이터 크기가 10 % 감소했는지 또는 특정 값이 올바르게 채워 졌는지 감지하기가 매우 어렵습니다.
기업은 데이터 품질 및 테스트와 관련하여 아직 초기 단계에 있습니다., this creates a 막대한 기술적 부채. 나는 이것을 확인하는 것이 좋습니다조자세한 내용은.
이러한 문제를 완화하려면 다음을 따르십시오.DDD principles and make sure that boundaries are set and a common language is used. Use frameworks that support data lineage like NiFi or Dagster.
데이터 품질에 중점을 둔 일부 도구는 다음과 같습니다.
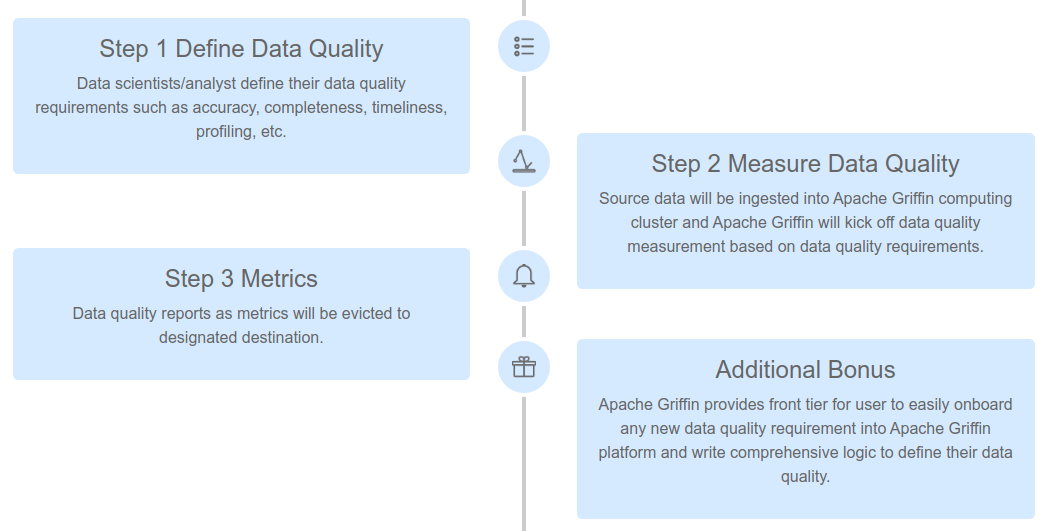
- Apache Griffin: Hadoop 에코 시스템의 일부인이 도구는 다양한 관점에서 데이터 품질을 측정하는 통합 프로세스를 제공하여 신뢰할 수있는 데이터 자산을 구축하는 데 도움을줍니다. 데이터에 대한 어설 션을 생성하고 파이프 라인의 일부로 검증하는 데 사용할 수있는 DSL을 제공합니다. Spark와 통합됩니다. 데이터 세트에 대한 규칙 및 어설 션을 추가 한 다음 Spark 작업으로 유효성 검사를 실행할 수 있습니다. 그리핀의 문제점은 DSL이 관리하기 어려워지고 (JSON) 기술이 아닌 사람이 해석하기 어렵 기 때문에 오해 된 요구 사항 문제를 해결하지 못한다는 사실입니다.
- 큰 기대: 이것은 작성된 새로운 도구입니다파이썬데이터 품질, 파이프 라인 테스트 및 품질 보증에 중점을 둡니다. Airflow 또는 기타 오케스트레이션 도구와 쉽게 통합 할 수 있으며 자동화 된 데이터 유효성 검사를 제공합니다. 이 도구를 차별화하는 것은human readable데이터 분석가, BA 및 개발자가 사용할 수 있습니다. 직관적 인 UI뿐만 아니라 완전 자동화를 제공하므로 프로덕션 파이프 라인의 일부로 유효성 검사를 실행하고 멋진 결과를 볼 수 있습니다.UI. 기술적 인 사람이 아닌 사람이 주장을 작성할 수 있습니다.노트북 which provide documentation and formal requirements that developers can easily understand, translate to code and use for testing. BAs or testers write the data assertions (기대) 모든 사람이보고 확인할 수 있도록 UI에서 사람이 읽을 수있는 테스트로 변환됩니다. 또한 데이터 프로파일 링을 수행하여 일부 어설 션을 생성 할 수 있습니다. 온 프레미스 또는 클라우드에서 데이터베이스 또는 파일 시스템에 직접 연결할 수 있습니다. 사용 및 관리가 매우 쉽습니다. 기대치를 소스 코드 리포지토리에 커밋 한 다음 파이프 라인에 통합 할 수 있습니다.Great Expectations는 데이터 품질에 관련된 모든 당사자를위한 공통 언어와 프레임 워크를 만듭니다., 그것을 만들기대단히 파이프 라인 자동화 및 테스트 용이최소한의 노력으로.
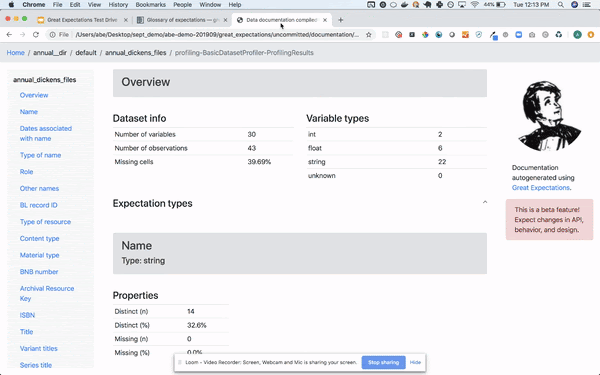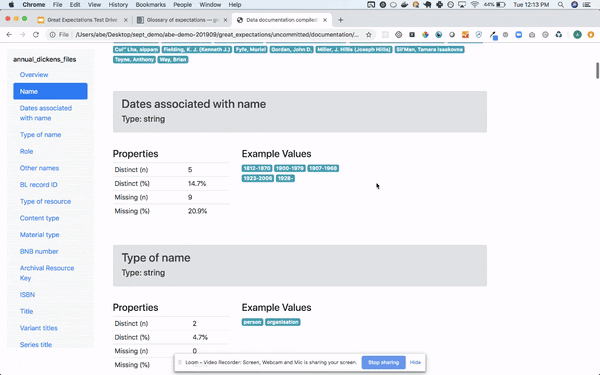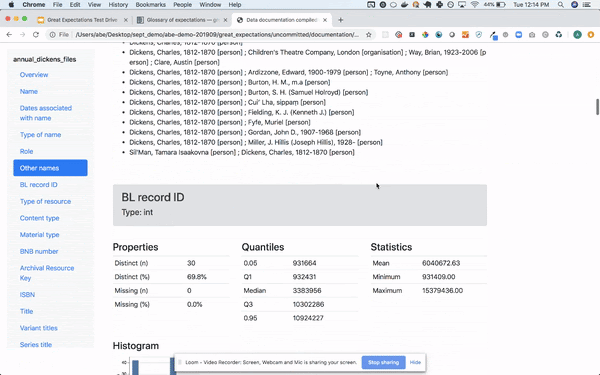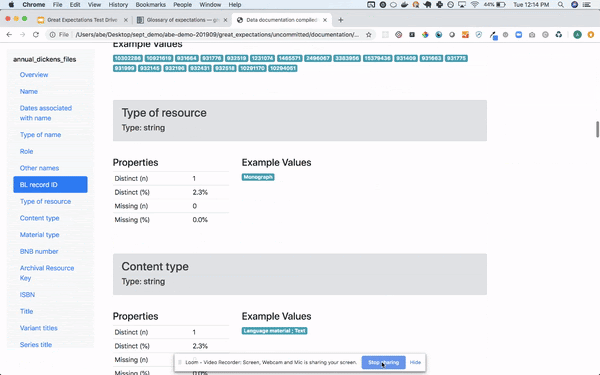
Query your data
Now that you have your cooked recipe, it is time to finally get the value from it. By this point, you have your data stored in your data lake using some deep storage such HDFSParquet 또는 OLAP와 같은 쿼리 가능한 형식database.
데이터를 쿼리하는 데 사용되는 다양한 도구가 있으며 각 도구에는 장단점이 있습니다. 그들 대부분은OLAP그러나 OLTP에 최적화 된 것은 거의 없습니다. 일부는 표준 형식을 사용하고 쿼리 실행에만 집중하는 반면 다른 일부는 자체 형식 / 스토리지를 사용하여 처리를 소스로 푸시하여 성능을 향상시킵니다. 일부는 별표 또는 눈송이 스키마를 사용하여 데이터웨어 하우징에 최적화 된 반면 다른 일부는 더 유연합니다. 요약하면 다음과 같은 다양한 고려 사항이 있습니다.
- 데이터웨어 하우스와 데이터 레이크
- Hadoop vs Standalone
- OLAP vs OLTP
- 쿼리 엔진 대 OLAP 엔진
쿼리 기능이있는 처리 엔진도 고려해야합니다.
처리 엔진
이전 섹션에서 설명한 대부분의 엔진은 다음과 같은 메타 데이터 서버에 연결할 수 있습니다.Hive and run queries, create views, etc. This is a common use case to create refined reporting layers.
Spark SQLSQL 쿼리를 Spark 프로그램과 원활하게 혼합하는 방법을 제공하므로DataFrameSQL을 사용하는 API. JDBC 또는 ODBC를 통한 Hive 통합 및 표준 연결이 있습니다. 그래서 당신은 연결할 수 있습니다Tableau,Looker또는 Spark를 통해 데이터에 BI 도구를 추가합니다.

Apache Flink또한 제공합니다SQLAPI. Flink의 SQL 지원은Apache CalciteSQL 표준을 구현합니다. 또한 다음과 통합됩니다.하이브통해HiveCatalog. For example, users can store their Kafka or ElasticSearch tables in Hive Metastore by using HiveCatalog, and reuse them later on in SQL queries.
쿼리 엔진
이러한 유형의 도구는 쿼리에 중점을 둡니다.통합 된 방식으로 다양한 데이터 소스 및 형식. The idea is to query your data lake using SQL queries like if it was a relational database, although it has some limitations. Some of these tools can also query NoSQL databases and much more. These tools provide a JDBC interface for external tools, such as Tableau or Looker, 안전한 방식으로 데이터 레이크에 연결합니다.쿼리 엔진은 가장 느린 옵션이지만 최대한의 유연성을 제공합니다.
- Apache Pig: Hive와 함께 첫 번째 쿼리 언어 중 하나였습니다. SQL과 다른 자체 언어가 있습니다. Pig 프로그램의 두드러진 특성은 구조가 상당히병렬화, which in turns enables them to handle very large data sets. It is now in decline in favor of newer SQL based engines.
- 프레스토 악장: 페이스 북에서 오픈 소스로 출시, 오픈 소스분산 SQL 쿼리 엔진모든 크기의 데이터 소스에 대해 대화 형 분석 쿼리를 실행합니다. Presto를 사용하면 Hive, Cassandra, 관계형 데이터베이스 및 파일 시스템을 포함하여 데이터가있는 곳에서 쿼리 할 수 있습니다. 대용량 데이터 세트에 대한 쿼리를 몇 초 만에 수행 할 수 있습니다. Hadoop과 독립적이지만 대부분의 도구, 특히 Hive와 통합하여 SQL 쿼리를 실행합니다.
- Apache Drill: Provides a schema-free SQL Query Engine for Hadoop, NoSQL and even cloud storage. It is independent of Hadoop but has many integrations with the ecosystem tools such Hive. A single query can join data from multiple datastores performing optimizations specific to each data store. It is very good at allowing analysts to treat any data like a table, even if they are reading a file under the hood. Drill은 완전한 표준 SQL을 지원합니다. 비즈니스 사용자, 분석가 및 데이터 과학자는 다음과 같은 표준 BI / 분석 도구를 사용할 수 있습니다.Tableau,Qlik및 Excel은 Drill의 JDBC 및 ODBC 드라이버를 활용하여 비 관계형 데이터 저장소와 상호 작용합니다. 또한 개발자는 맞춤형 애플리케이션에서 Drill의 간단한 REST API를 활용하여 멋진 시각화를 만들 수 있습니다.
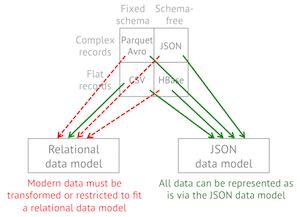
OLTP Databases
Although, Hadoop is optimized for OLAP there are still some options if you want to perform OLTP queries for an interactive application.
HBase 확장 할 수 있도록 만들어졌고 ACID 기능을 즉시 제공하지 않기 때문에 설계 상 매우 제한된 ACID 속성을 갖지만 일부 OLTP 시나리오에 사용할 수 있습니다.
Apache PhoenixHBase를 기반으로 구축되었으며 Hadoop 에코 시스템에서 OTLP 쿼리를 수행하는 방법을 제공합니다. Apache Phoenix는 Spark, Hive, Pig, Flume 및 Map Reduce와 같은 다른 Hadoop 제품과 완전히 통합됩니다. 또한 메타 데이터를 저장할 수 있으며 DDL 명령을 통해 테이블 생성 및 버전 별 증분 변경을 지원합니다. 꽤fast, faster than using Drill or other query engine.
You may use any massive scale database outside the Hadoop ecosystem such as Cassandra, YugaByteDB, ScyllaDB for OTLP.
Finally, it is very common to have a subset of the data, usually the most recent, in a fast database of any type such MongoDB or MySQL. The 쿼리 엔진 mentioned above can join data between slow and fast data storage in a single query.
분산 검색 인덱스
These tools provide a way to store and search unstructured text data and they live outside the Hadoop ecosystem since they need special structures to store the data. The idea is to use an inverted index to perform fast lookups. Besides text search, this technology can be used for a wide range of use cases like storing logs, events, etc. There are two main options:
- Solr: Apache를 기반으로 구축 된 인기 있고 빠른 속도의 오픈 소스 엔터프라이즈 검색 플랫폼입니다.Lucene. Solr is reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. It is great for text search but its use cases are limited compared to ElasticSearch.
- ElasticSearch: It is also a very popular distributed index but it has grown into its own ecosystem which covers many use cases like APM, search, text storage, analytics, dashboards, machine learning and more. It is definitely a tool to have in your toolbox either for DevOps or for your data pipeline since it is very versatile. It can also store and search videos and images.
ElasticSearch로 사용할 수 있습니다 fast storage layer for your data lake for advanced search functionality. If you store your data in a key-value massive database, like HBase or Cassandra, which provide very limited search capabilities due to the lack of joins; you can put ElasticSearch in front to perform queries, return the IDs and then do a quick lookup on your database.
그것은 또한 사용할 수 있습니다analytics; 데이터를 내보내고 색인을 생성 한 다음Kibana, 대시 보드, 보고서 등을 생성하고 히스토그램, 복잡한 집계를 추가하고 데이터 위에 기계 학습 알고리즘을 실행할 수도 있습니다. Elastic Ecosystem은 거대하고 탐험 할 가치가 있습니다.

OLAP 데이터베이스
In this category we have databases which may also provide a metadata store for schemas and query capabilities. Compared to query engines, these tools also provide storage and may enforce certain schemas in case of data warehouses (star schema). These tools use SQL syntax and Spark and other frameworks can interact with them.
- Apache Hive: We already discussed Hive as a central schema repository for Spark and other tools so they can use SQL, but Hive can also store data, so you can use it as a data warehouse. It can access HDFS or HBase. When querying Hive it leverages on Apache Tez, Apache Spark, or MapReduce, Tez 또는 Spark가 훨씬 빠릅니다. 또한 HPL-SQL이라는 절차 언어도 있습니다.
- Apache Impala: It is a native분석 데이터베이스 for Hadoop, that you can use to store data and query it in an efficient manner. It can connect to Hive for metadata using Hcatalog. Impala provides 짧은 지연 시간과 높은 동시성Hadoop의 BI / 분석 쿼리 용 (Apache Hive와 같은 배치 프레임 워크에서 제공되지 않음). Impala는 또한 다중 테넌트 환경에서도 선형 적으로 확장되므로 Hive보다 쿼리를위한 더 나은 대안이됩니다. Impala는 인증을 위해 기본 Hadoop 보안 및 Kerberos와 통합되므로 데이터 액세스를 안전하게 관리 할 수 있습니다. 그것은 사용합니다HBase and HDFS for data storage.
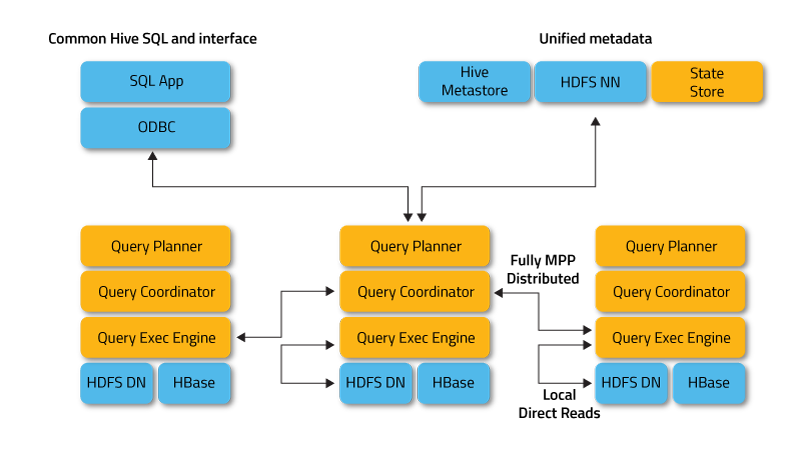
- Apache Tajo: 또 다른data warehouse for Hadoop. Tajo is designed for low-latency and scalable ad-hoc queries, online aggregation, and ETL on large-data sets stored on HDFS and other data sources. It has integration with 하이브 메타 스토어 to access the common schemas. It has many query optimizations, it is scalable, fault tolerant and provides a JDBC interface.
- Apache Kylin: Apache Kylin is a newer distributed Analytical Data Warehouse. Kylin is extremely fast, so it can be used to complement some of the other databases like Hive for use cases where 공연다음과 같이 중요합니다.dashboards or interactive reports, it is probably the best OLAP data warehouse but it is more difficult to use, another problem is that because of the high dimensionality, you need more storage. The idea is that if query engines or Hive are not fast enough, you can create a “입방체” in Kylin which is a multidimensional table optimized for OLAP with 사전 계산대시 보드 또는 대화 형 보고서에서 쿼리 할 수있는 값입니다. Spark에서 직접 큐브를 만들 수 있으며 Kafka에서 거의 실시간으로도 만들 수 있습니다.
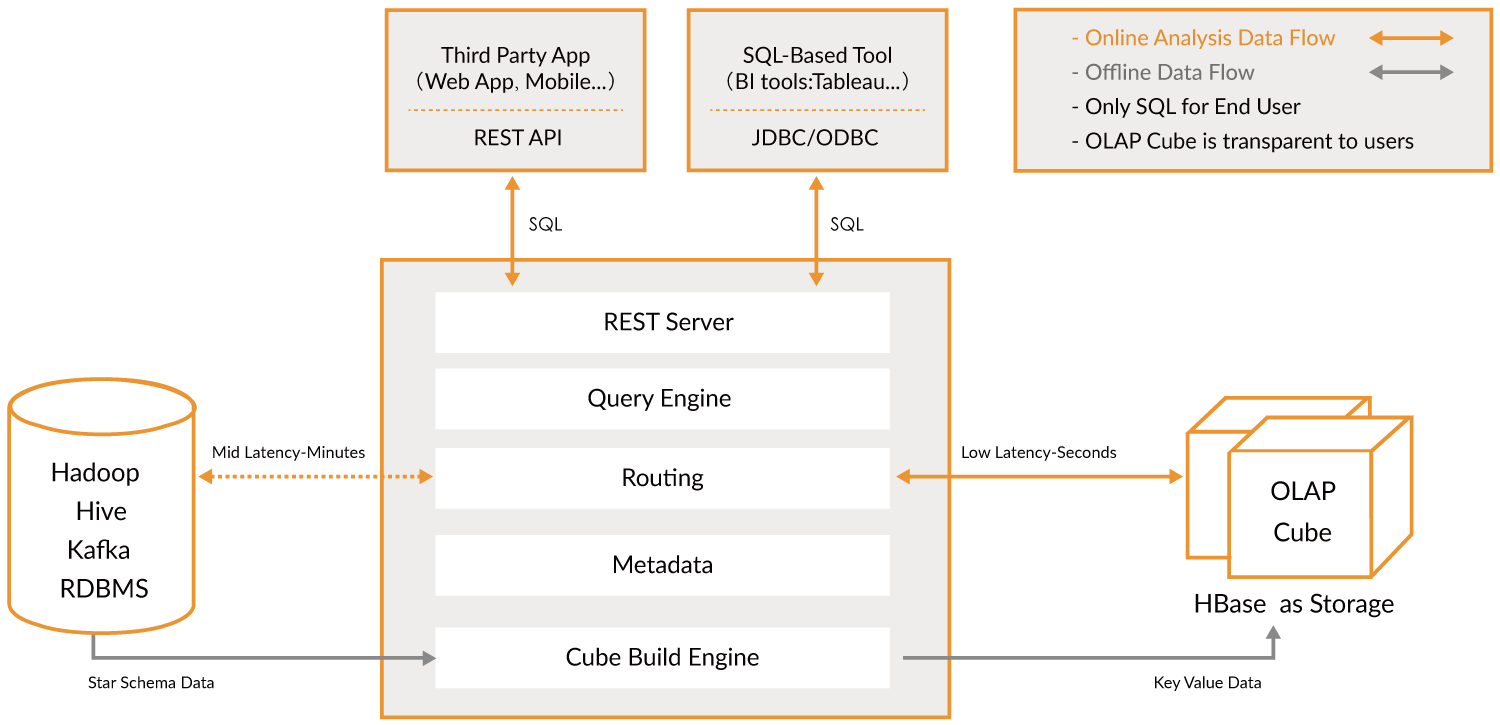
OLAP Engines
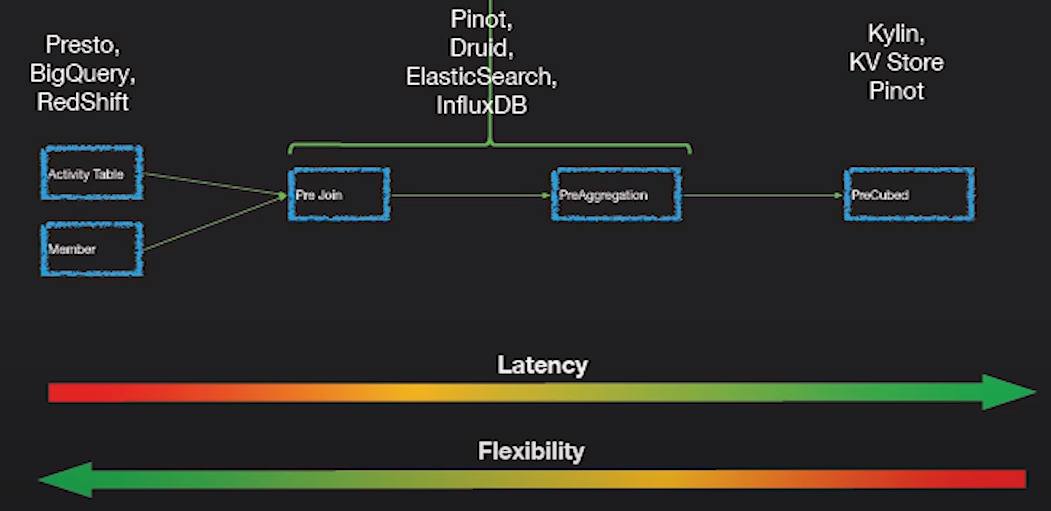
In this category, I include newer engines that are an evolution of the previous OLAP databases which provide more functionality creating an all-in-one analytics platform. Actually, they are a 잡종이전 두 카테고리 중인덱싱OLAP 데이터베이스에. 그들은 Hadoop 플랫폼 외부에 있지만 긴밀하게 통합되어 있습니다. 이 경우 일반적으로 처리 단계를 건너 뛰고 이러한 도구를 사용하여 직접 수집합니다.
그들은 문제를 해결하려고실시간 및 과거 데이터 쿼리 in an uniform way, so you can immediately query real-time data as soon as it’s available alongside historical data with low latency so you can build interactive applications and dashboards. These tools allow in many cases to query the raw data with almost no transformation in an ELT패션이지만 일반 OLAP 데이터베이스보다 우수한 성능을 제공합니다.
공통점은unified view of the data, real time and batch data ingestion, distributed indexing, its own data format, SQL support, JDBC interface, hot-cold data support, multiple integrations 그리고metadata store.
- Apache Druid: It is the most famous real time OLAP engine. It focused on time series data but it can be used for any kind of data. It uses its own columnar format데이터를 크게 압축 할 수 있으며 다음과 같은 많은 최적화 기능이 내장되어 있습니다.inverted indices, text encoding, automatic data roll up and much more. Data is ingested in real time using 평온 or Kafka which has very low latency, data is kept in memory in a row format optimized for writes but as soon as it arrives is available to be query just like previous ingested data. A background task in in charge of moving the data asynchronously to a deep storage system such HDFS. When data is moved to deep storage it is converted into smaller chunks partitioned by time called segments지연 시간이 짧은 쿼리에 최적화되어 있습니다. 각 세그먼트에는 집계를 필터링하고 수행하는 데 사용할 수있는 여러 차원 인 타임 스탬프가 있습니다. 및 사전 계산 된 집계 인 메트릭입니다. 일괄 처리의 경우 데이터를 세그먼트에 직접 저장합니다. 푸시 및 풀 섭취를 지원합니다. 그것은 가지고있다integrations와하이브, 스파크and even NiFi.Hive 메타 스토어를 사용할 수 있으며 Druid에서 사용하는 JSON 쿼리로 변환되는 Hive SQL 쿼리를 지원합니다. Hive 통합은 JDBC를 지원하므로 모든 BI 도구를 연결할 수 있습니다. 또한 자체 메타 데이터 저장소 (일반적으로 MySQL)도 있습니다. 방대한 양의 데이터를 수집하고 매우 잘 확장 할 수 있습니다. 주요 문제는 구성 요소가 많고difficult to manage and deploy.
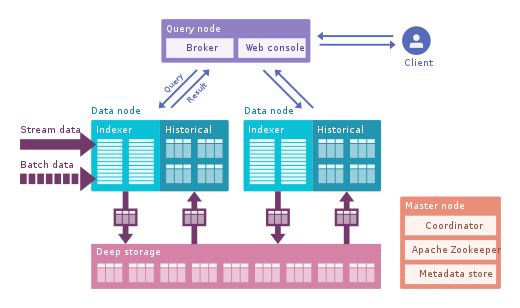
- Apache Pinot: It is a newer alternative to Druid open sourced by LinkedIn. Compared to Druid, it offers 낮은 지연 thanks to the 스타 트리부분적인 사전 계산을 제공하는 인덱스로 사용자 대면 앱에 사용할 수 있습니다 (LinkedIn 피드를 가져 오는 데 사용됨). 그것은정렬 된 색인 instead of inverted index which is faster. It has an extendable plugin architecture and also has many integrations but does not support Hive. It also unifies batch and real time, provides fast ingestion, smart index and stores the data in segments. It is easier to deploy and faster compared to Druid but it is a bit immature at the moment.
- 클릭 하우스: Written in C++, this engine provides incredible performance for OLAP queries, especially aggregations. It looks like a relational database so you can model the data very easily. It is very easy to set up and has many integrations.

이것을 확인하십시오article세 엔진을 자세히 비교합니다. 다시 말하지만, 작게 시작하여 결정을 내리기 전에 데이터를 파악하십시오. 이러한 새로운 엔진은강력하지만 사용하기 어렵다. 몇 시간을 기다릴 수 있다면 일괄 처리와 Hive 또는 Tajo와 같은 데이터베이스를 사용하십시오. 그런 다음 Kylin을 사용하여 OLAP 쿼리를 가속화하여보다 대화 형으로 만듭니다. 충분하지 않고 더 짧은 지연 시간과 실시간 데이터가 필요한 경우 OLAP 엔진을 고려하십시오. Druid는 실시간 분석에 더 적합합니다. Kylin은 OLAP 사례에 더 중점을 둡니다. Druid는 실시간 스트리밍으로 Kafka와 잘 통합되어 있습니다. Kylin은 Hive 또는 Kafka에서 일괄 적으로 데이터를 가져옵니다. 실시간 수집은 가까운 장래에 계획되어 있습니다.
Finally, Greenplum더 많은 기능을 갖춘 또 다른 OLAP 엔진입니다.AI에 집중.
마지막으로심상 you have several commercial tools such Qlik,보는 사람또는Tableau. For Open Source, check SuperSet, an amazing tool that support all the tools we mentioned, has a great editor and it is really fast. 메타베이스 or 매다른 훌륭한 옵션입니다.
결론
우리는데이터: 다양한 모양, 형식, 처리 방법, 저장 방법 등. 생각해 내다:데이터와 비즈니스 모델 파악. 반복적 인 프로세스를 사용하고빅 데이터 플랫폼 구축을 천천히 시작하십시오; 새로운 프레임 워크를 도입하는 것이 아니라올바른 질문을하고 올바른 답변을 제공하는 최고의 도구를 찾습니다.
데이터에 대한 다양한 고려 사항을 검토하고 데이터 모델 (SQL), 쿼리 (NoSQL), 인프라 및 예산에 따라 적절한 스토리지를 선택하십시오. 기억해클라우드 제공 업체와 협력빅 데이터 (구매 대 빌드)에 대한 클라우드 제공을 평가합니다. 로 시작하는 것은 매우 일반적입니다.서버리스분석 파이프 라인을 사용하고 비용이 증가함에 따라 천천히 오픈 소스 솔루션으로 이동합니다.
데이터 수집은 중요하고 복잡합니다.제어 할 수없는 시스템에 대한 종속성으로 인해; 이러한 종속성을 관리하고 신뢰할 수있는 데이터 흐름을 만들어 데이터를 적절하게 수집합니다. 가능한 경우 다른 팀이 데이터 수집을 소유하도록합니다. 데이터를 추적하려면 측정 항목, 로그 및 추적을 추가해야합니다. 스키마 진화를 활성화하고 플랫폼에 적절한 보안을 설정했는지 확인하십시오.
작업에 적합한 도구 사용씹을 수있는 것보다 더 많이 섭취하지 마십시오. Cassandra, Druid 또는 ElasticSearch와 같은 도구는 놀라운 기술이지만 제대로 사용하고 관리하려면 많은 지식이 필요합니다. 임시 쿼리 및 보고서에 대한 OLAP 일괄 분석 만 필요한 경우 Hive 또는 Tajo를 사용합니다. 더 나은 성능이 필요하면 Kylin을 추가하십시오. 다른 데이터 소스와 조인해야하는 경우 Drill 또는 Presto와 같은 쿼리 엔진을 추가합니다. 또한 실시간 및 일괄 쿼리가 필요한 경우 ClickHouse, Druid 또는 Pinot를 사용하십시오.
자유롭게들어와접촉질문이 있거나 조언이 필요한 경우.
이 기사가 재미 있었기를 바랍니다. 의견을 남기거나이 게시물을 공유하십시오. 따르다나를 향후 게시물을 위해.
'Data Analytics(ko)' 카테고리의 다른 글
| How To Make Money Using Web Scraping -번역 (0) | 2020.10.12 |
|---|---|
| Automating your daily tasks with Python -번역 (0) | 2020.10.11 |
| 5 Underrated Apps for Programmers You Should Use Right Now -번역 (0) | 2020.10.09 |
| 🔝Top 29 Useful Python Snippets 🔝 That Save You Time -번역 (0) | 2020.10.08 |
| You are telling people that you are a Python beginner if you ask this question. -번역 (0) | 2020.10.07 |