개발자가 앱과 소프트웨어를 만들기 위해 수많은 앱과 소프트웨어를 사용하는 방식은 아이러니합니다. 시간이 지남에 따라 워크 플로의 일부로 선택한 몇 가지 도구에 대한 강력한 선호도를 개발했습니다. 그러나 일부 소프트웨어가 표준이되었다고해서 항상 다른 소프트웨어를 주시해서는 안되는 것은 아닙니다! 다음은 내가 매일 사용하려고 시도한 가장 과소 평가되었지만 엄청나게 유용한 앱 중 일부이며 여러분도 사용해야한다고 생각합니다!
내 권장 사항이 특정 프로그래밍 틈새에 초점을 맞추지 않기를 원하기 때문에 아래 표시된 앱의 눈에 띄는 부분이 터미널 기반이므로 대부분의 프로그래머 / 개발자를 대상으로합니다.
목차
Ungit
Termius
기민함
뵤부
스페이스 데스크
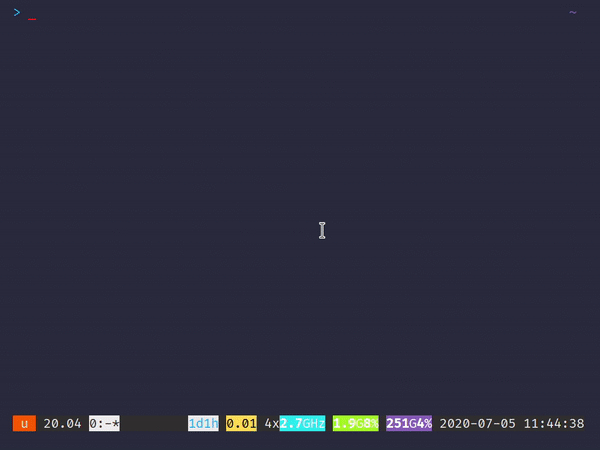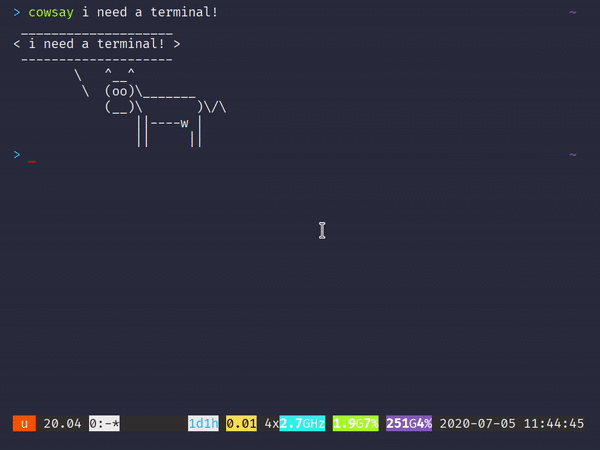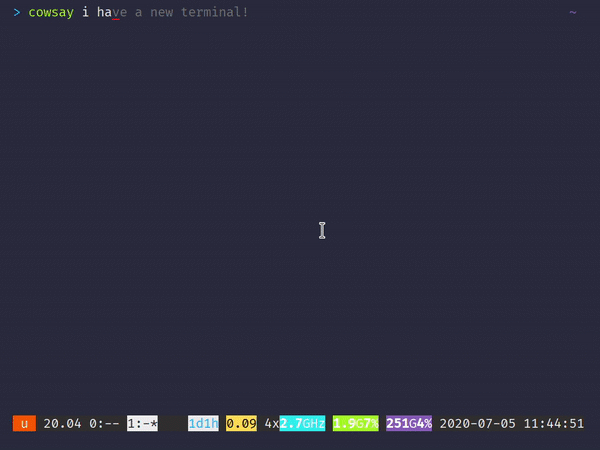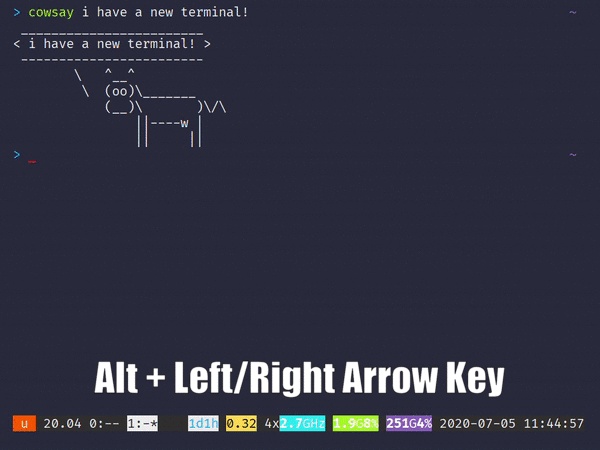
1. Ungit
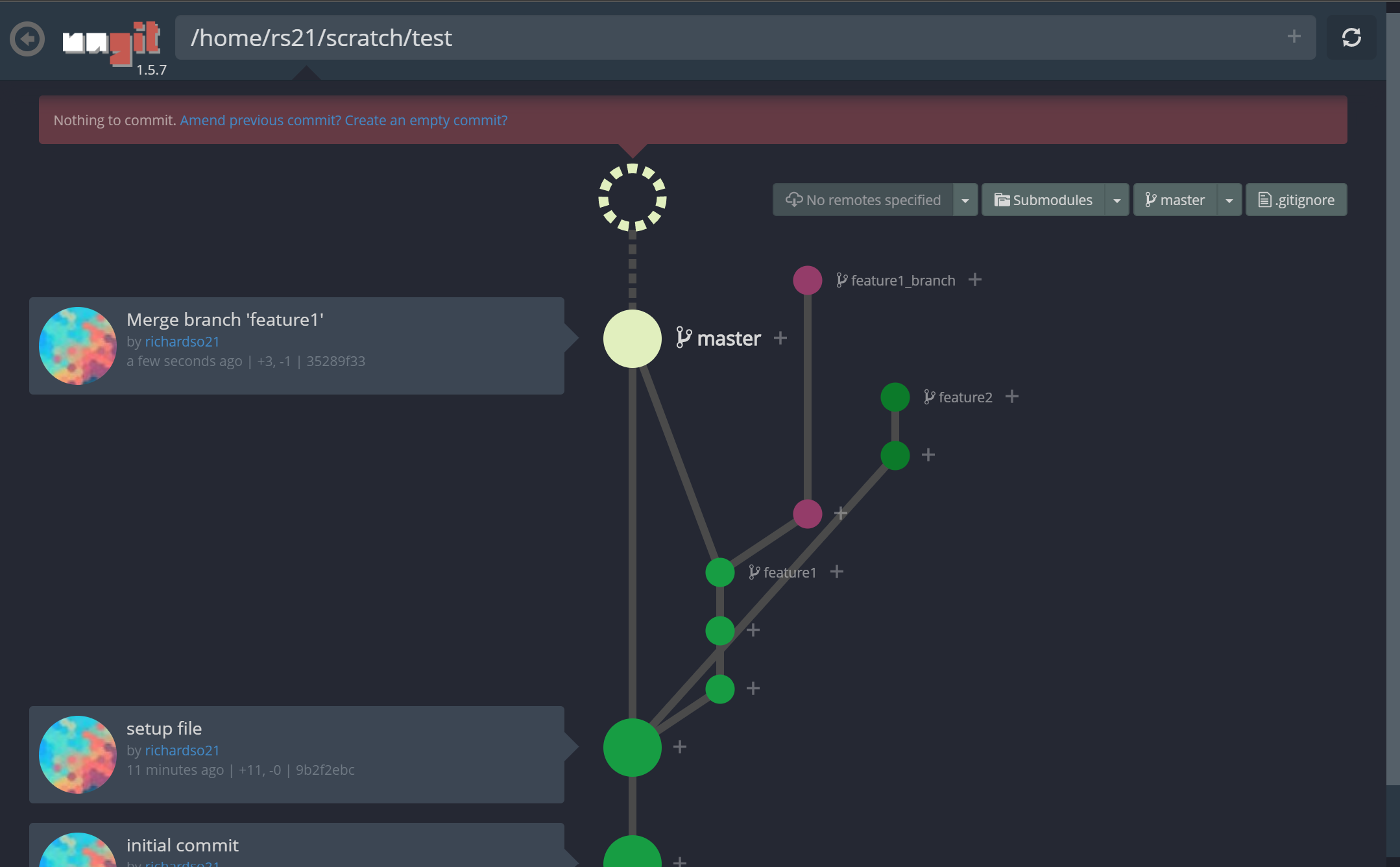
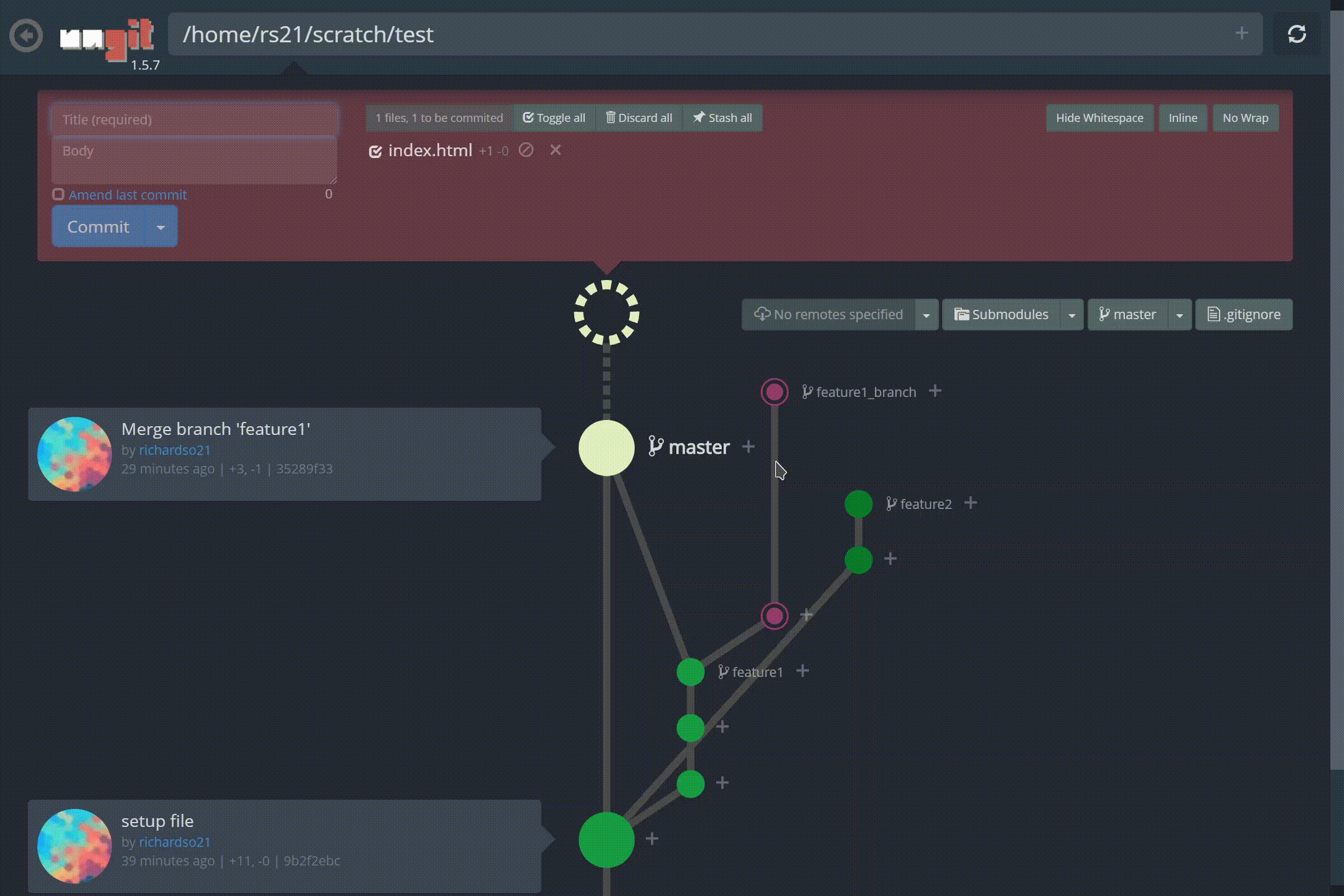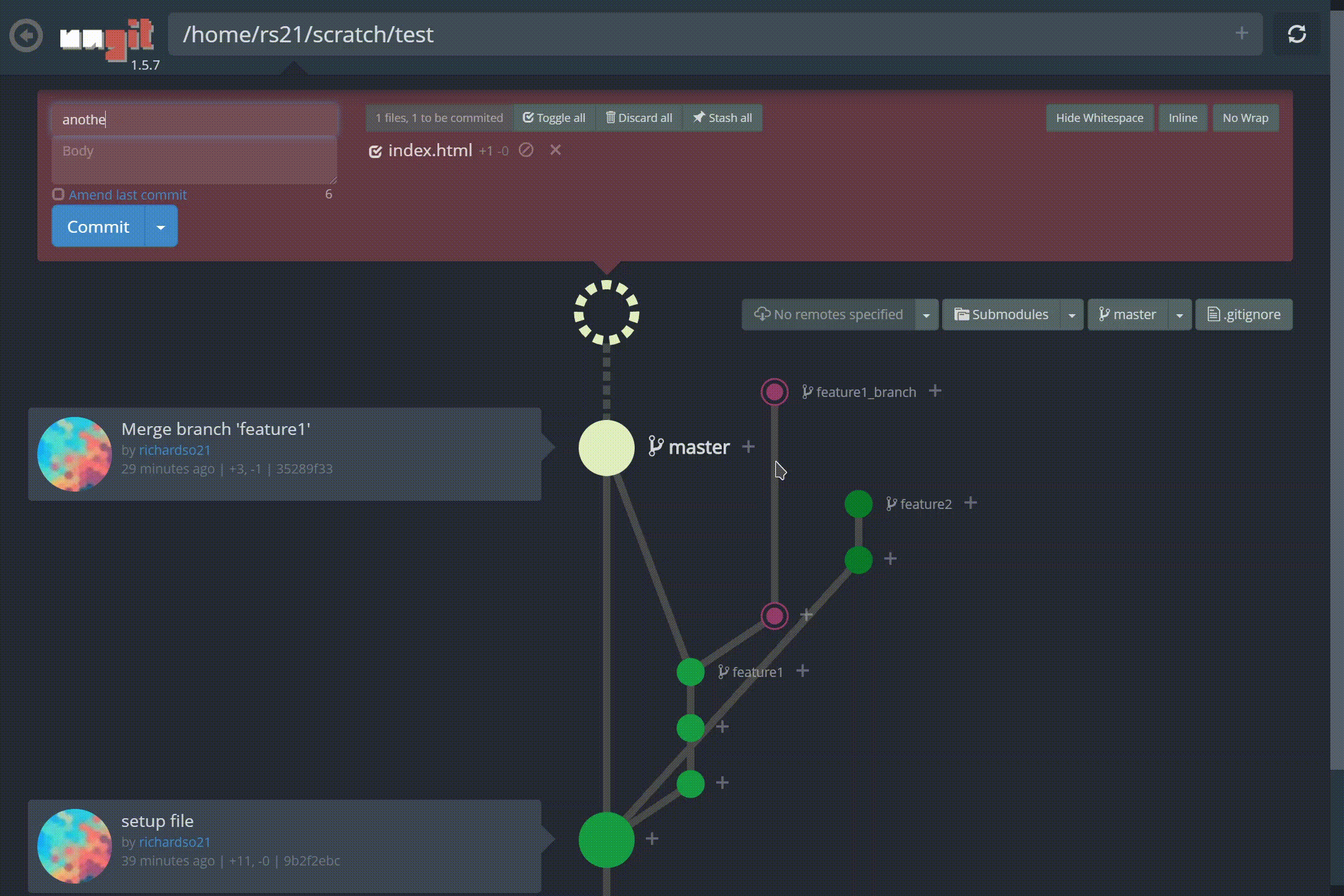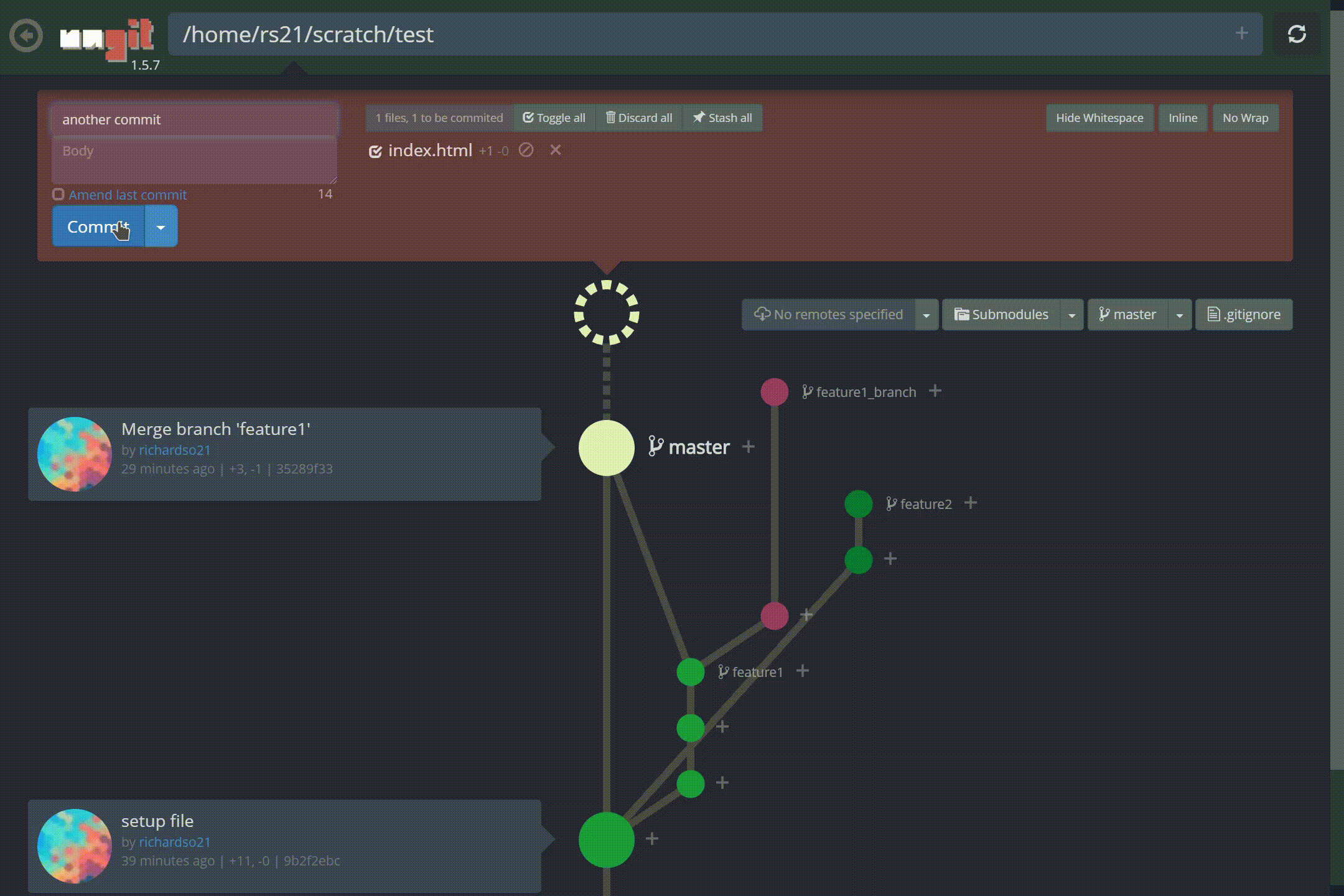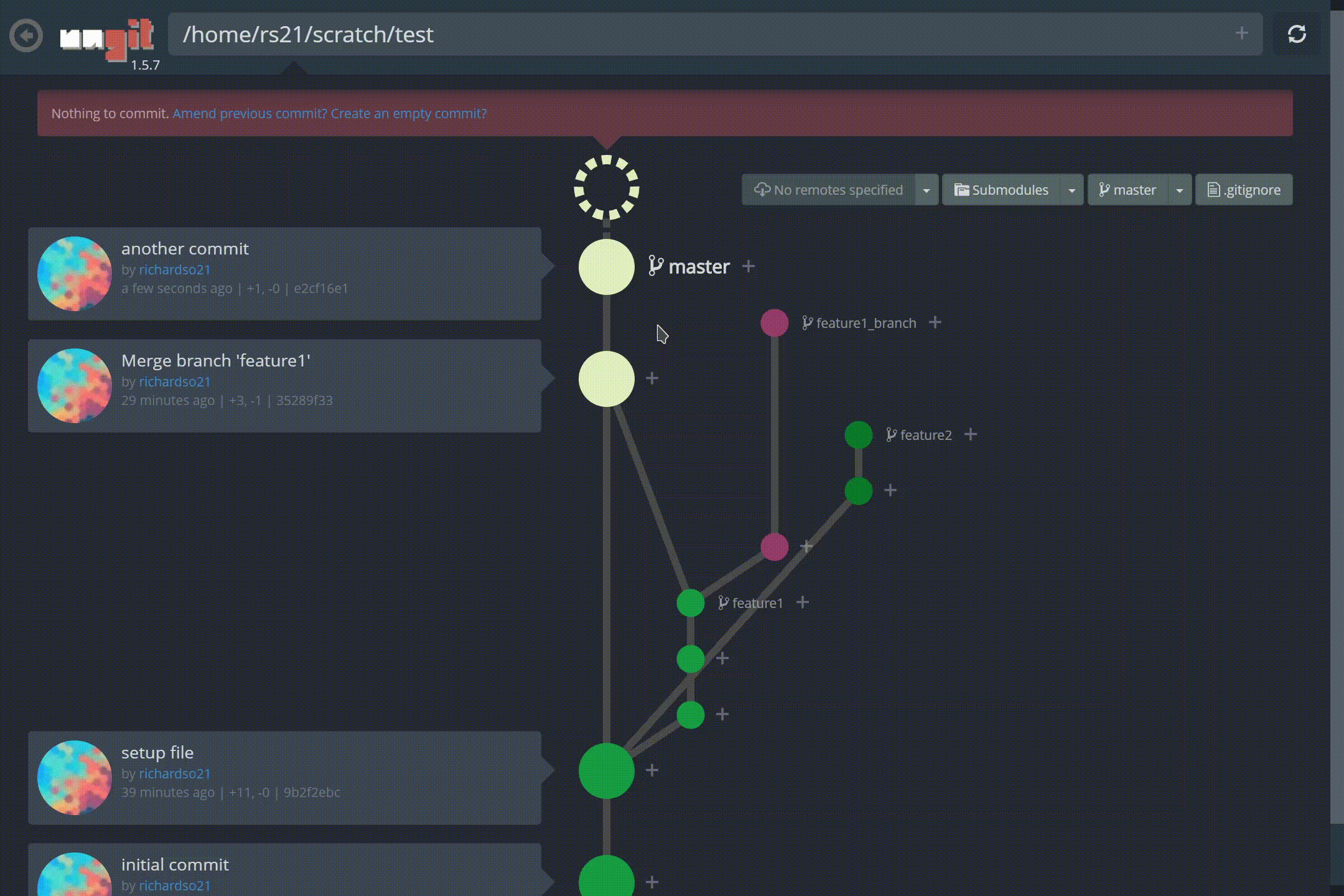
명령 줄 인터페이스를 통해 Git 리포지토리를 관리하는 것은 악명 높을 정도로 어렵습니다. 모든 사람이 사실을 알고 있습니다. 그리고 20 개 정도의 다른 브랜치가있는 프로젝트를 열면 모든 브랜치를 통해 최근 커밋을 따라 가기가 어렵습니다.분기 모델. 더 나쁜 것은 처음으로 Git을 사용하여 버전 제어를 수행하려는 초보자입니다. ㅏCLI는 사용자가 Git의 진정한 의미를 이해하도록 할 수 없습니다.
저 가지 좀 봐! 또한 커밋을 만드는 것이 그 어느 때보 다 쉬워졌습니다.재미있는 애니메이션과 결합하여느낌커밋이 완료되었습니다— 명령 줄이 유도 할 수없는 것 :
ungit에서 새 커밋 만들기
지점 간 체크 아웃도 비교적 간단합니다.UI를 통해 현재있는 브랜치와 관련된 커밋 내역을 볼 수 있습니다.:
ungit의 동일한 저장소에서 다른 분기 간 전환 (체크 아웃)
Ungit분기 병합, 태그 지정 등을 지원합니다! YouTube에서보다 포괄적 인 데모를 찾을 수 있습니다.여기.
2. Termius
격리 시간 (적어도이 글을 쓰는 시점)이므로 모두가 집에서 합리적으로 일하고 있습니다. 직장에서 컴퓨터 나 서버에 액세스해야하는 경우 어떻게합니까? 글쎄, 당신은 서버에 SSH를 사용하여 해당 컴퓨터의 터미널에 대한 액세스 권한을 부여합니다. 이것은 간단한 것으로 할 수 있지만ssh명령, 왜 안돼스타일와Termius?
TermiusMosh와 호환되는 SSH 클라이언트로, Electron을 기반으로 구축 된 것 같습니다. Windows, macOS, Linux, iOS, Android 등 상상할 수있는 모든 플랫폼에서 작동합니다.
원격 서버, Termius에서`sl` 실행 😎
Termius에 대한 사용자 지정 옵션
이 앱은 원하는대로 사용자 지정할 수있는 다양한 테마, 글꼴 및 글꼴 크기를 지원합니다. 말할 것도없이이 앱은 이미 기본 사전 설정으로 꽤 매끄럽게 보입니다.
가장 매력적인 기능 중 하나Termius, 외관과 SSH 기능을 제외하고는포트 포워딩, 내가 자주 사용하는Jupyter.
또한 여러 호스트를 기억할 수 있습니다.동조이동 중에 원격 서버 프로세스를 처리 할 때 모바일 장치로 동기화는 계정을 통해 이루어지며 무료로 등록하거나 추가 혜택을 위해 약간의 비용을 지불 할 수 있습니다.
3. 기민성
터미널에 대해 말하면기민함내 로컬 터미널 에뮬레이터로 이동합니다. Windows, macOS 및 많은 Linux 배포에서 지원됩니다. 최고의 판매 포인트 중 하나기민함그것입니다GPU 가속 지원. 이 때문에 터미널 에뮬레이터 제작자는대체 제품에 비해 놀랍도록 빠른 성능을 자랑합니다..
기민함Termius에 비해 훨씬 더 간단한 패키지로 제공되지만 사용자 정의가 부족하다는 의미는 아닙니다. 앱은 구성 파일 (형식의.yml파일)에서 제공하는그들의 레포. 거기에서 색 구성표에서 키보드 바인딩, 심지어 배경 불투명도까지 터미널에 대한 거의 모든 것을 사용자 지정할 수 있습니다! 터미널 고급 사용자이거나 로컬 디렉토리에 액세스하는 데 필요한 경우기민함!
4. 뵤부
이건 아니야기술적으로앱이나 소프트웨어이지만 개인적으로 워크 플로에서이 기능을 많이 사용했기 때문에이 기사에서이 기능을 소개해야한다고 느꼈습니다.It’s a terminal multiplexer & window manager— 사실, 실제로는 래퍼입니다.tmux및 / 또는GNU 화면,들어 보셨을 멀티플렉서입니다. 원격 서버 (Termius 😉)에서 작업 중이거나 자신의 컴퓨터에서 여러 터미널 창을 자주 여는 경우뵤부확실히 당신을위한 것입니다.
여러 터미널 인스턴스를 여는 대신뵤부하나의 인터페이스에서 모든 터미널 인스턴스를 처리합니다.. 작업을 위해 2 개의 터미널이 열려 있고이 모든 것에 동시에 쉽게 액세스해야한다고 가정 해 보겠습니다. 이것이 실제로 작동하는지 봅시다 :
Byobu를 사용하여 한 곳에서 터미널 세션 / 인스턴스 처리
재미있는 사실 : 여기 Byobu가 Alacritty로 실행 중입니다!
보시다시피 새 터미널 인스턴스를 만들고 둘 사이를 전환하는 것은 매우 간단합니다. 인스턴스 (또는 문서에 기반한 "창")는 상태 표시 줄에 아래에 나열되어 있습니다.이 표시 줄은 이미 자체적으로 좋은 정보로 채워져 있습니다.그리고 이것은 상자에서 바로 나옵니다!
Byobu의기본상태 표시 줄
여기서 그치지 않습니다. 실제로 각 창에서 개별 분할 창을 설정하여완전한터미널 레이아웃.
Byobu의 분할 창
내 생각에 Byobu는 다른 멀티플렉서에 비해 배우기가 훨씬 쉽습니다. 뵤부F1, F2, F3… 등과 같은 기능 키를 사용합니다. — 기본 키보드 바인딩 용. 적어도 나에게는 모든 것을 한 줄에 두는 것이 일부 바인딩이 손 경련을 유발할 수 있더라도 모든 것을 여기에 두는 것보다 더 좋은 생각입니다. 길을 잃었거나 초보자라면 언제든지Shift + F1치트 시트를 보려면.
5. 스페이스 데스크
최근에이 앱에 대한 기사를 작성했습니다.여기. 이에 대한 자세한 내용을 원하시면 해당 기사로 넘어가십시오!
원래,스페이스 데스크iPad, Wi-Fi가 지원되는 구형 노트북 또는 휴대폰을 메인 컴퓨터의 보조 모니터로 변환 할 수 있습니다.어디에서나 Alt-Tabbing을 사용하는 데 얼마나 많은 시간을 소비하는지 깨닫는 경우를 제외하고는 지금 매우 틈새 시장처럼 들릴 수 있습니다.
따라서 두 번째 모니터를 구입하거나 예비 부품으로 DIY 모니터를 만드는 대신이 앱으로 시간과 비용을 절약 할 수 있습니다. 개인적으로 저는 이것을 사용하여 이전 노트북을 새로운 목적으로 되 살렸고 문제 나 버그가 거의 또는 전혀 보이지 않았습니다. 그만큼앱이 완전히 무선으로 실행됩니다., 따라서 더 나은 편의와 케이블 부족을 위해 인터넷 연결 상태에 따라 마일리지가 달라질 수 있습니다.
스페이스 데스크아직 베타 단계에 있지만 올해 말에 첫 번째 릴리스 버전이 될 예정 이니 계속 지켜봐 주시기 바랍니다.
결론
오늘부터 사용해야하는 과소 평가 된 앱 / 소프트웨어에 대한 내용입니다! 내가 나열한 것에 대한 생각이나 대안이 있으면 언제든지 알려 주시고 아래에서 대화를 시작하세요.언제나처럼 즐거운 코딩입니다. 여러분!
"=="와 "is"는 모두 Python (Python의 운영자 페이지에 링크). 초보자의 경우 "a == b"를 "a는 b와 같음", "a는 b"로 해석하고 "a는 b"로 해석 할 수 있습니다. 아마도 이것이 초보자들이 파이썬에서 "=="와 "is"를 혼동하는 이유 일 것입니다.
심층 토론을하기 전에 먼저“==”와“is”를 사용하는 몇 가지 예를 보여 드리고자합니다.
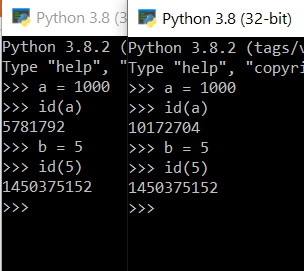
>>> a = 5 >>> b = 5 >>> a == b True >>> a is b True
간단 하죠?a == b과a는 b둘 다 반환진실. 그런 다음 다음 예제로 이동하십시오.
>>> a = 1000 >>> b = 1000 >>> a == b True >>> a is b False
뭐야?!? 첫 번째 예제에서 두 번째 예제로의 유일한 변경은 a와 b의 값이 5에서 1000까지입니다. 그러나 결과는 이미 "=="와 "is"사이에서 다릅니다. 다음으로 이동하십시오.
>>> a = [] >>> b = [] >>> a == b True >>> a is b False
당신의 마음이 여전히 날아 가지 않은 경우 마지막 예가 있습니다.
>>> a = 1000 >>> b = 1000 >>> a == b True >>> a is b False >>> a = b >>> a == b True >>> a is b True
"=="에 대한 공식적인 연산은 평등이고 "is"에 대한 연산은 동일성입니다. 두 개체의 값을 비교하려면 "=="를 사용합니다. "a == b"는 "a의 값이 b의 값과 같은지 여부"로 해석되어야합니다. 위의 모든 예에서 a의 값은 항상 b의 값과 같습니다 (빈 목록 예의 경우에도). 따라서“a == b”는 항상 참입니다.
정체성을 설명하기 전에 먼저신분증함수. 다음을 사용하여 개체의 ID를 얻을 수 있습니다.신분증함수. 이 아이덴티티는 시간 내내이 객체에 대해 고유하고 일정합니다. 이것을이 객체의 주소로 생각할 수 있습니다. 두 개체의 ID가 동일한 경우 해당 값도 동일해야합니다.
>>> id(a) 2047616
연산자 "is"는 두 개체의 ID가 동일한 지 여부를 비교하는 것입니다. “a is b”는“a의 정체는 b의 정체와 같다”는 의미입니다.
"=="및 "is"의 실제 의미를 알고 나면 위의 예를 자세히 살펴볼 수 있습니다.
첫 번째는 첫 번째와 두 번째 예의 다른 결과입니다. 다른 결과를 보여주는 이유는 파이썬이 각 정수에 대해 고정 된 ID로 -5에서 256까지의 정수 배열 목록을 저장하기 때문입니다. 이 범위 내의 정수 변수를 할당하면 Python은이 변수의 ID를 배열 목록 내의 정수에 대한 ID로 할당합니다. 결과적으로 첫 번째 예에서 a와 b의 ID는 모두 배열 목록에서 가져 오므로 해당 ID는 물론 동일하므로a는 b사실이다.
>>> a = 5 >>> id(a) 1450375152 >>> b = 5 >>> id(b) 1450375152
그러나 일단이 변수의 값이이 범위를 벗어나면 내부 파이썬에는 그 값을 가진 객체가 없기 때문에 파이썬은이 변수에 대한 새로운 ID를 만들고이 변수에 값을 할당합니다. 이전에 말했듯이 ID는 각 생성에 대해 고유하므로 두 변수의 값이 동일하더라도 ID는 동일하지 않습니다. 그래서a는 b두 번째 예에서는 False입니다.
>>> a = 1000 >>> id(a) 12728608 >>> b = 1000 >>> id(b) 13620208
(추가 : 두 개의 콘솔을 열면 값이 여전히 범위 내에 있으면 동일한 ID를 얻을 수 있습니다. 그러나 값이 범위를 벗어나는 경우에는 해당되지 않습니다.)
첫 번째 예제와 두 번째 예제의 차이점을 이해하면 세 번째 예제의 결과를 쉽게 이해할 수 있습니다. 파이썬은 "빈 목록"객체를 저장하지 않기 때문에 파이썬은 하나의 새 객체를 만들고 "빈 목록"값을 할당합니다. 두 목록이 비어 있거나 동일한 요소가 있어도 결과는 동일합니다.
>>> a = [1,10,100,1000] >>> b = [1,10,100,1000] >>> a == b True >>> a is b False >>> id(a) 12578024 >>> id(b) 12578056
마지막으로 마지막 예제로 이동합니다. 두 번째 예제와 마지막 예제의 유일한 차이점은 코드가 한 줄 더 있다는 것입니다.a = b. 그러나이 코드 줄은 변수의 운명을 변경합니다.ㅏ. 아래 결과는 그 이유를 알려줍니다.
>>> a = 1000 >>> b = 2000 >>> id(a) 2047616 >>> id(b) 5034992 >>> a = b >>> id(a) 5034992 >>> id(b) 5034992 >>> a 2000 >>> b 2000
보시다시피a = b, 정체성ㅏ신원 변경비.a = b신원을 할당비...에ㅏ. 그래서 둘 다ㅏ과비동일한 정체성을 가지므로ㅏ지금은 가치와 동일합니다비, 즉 2000입니다.
마지막 예는 특히 개체가 목록 인 경우 예고없이 실수로 개체의 값을 변경할 수 있다는 중요한 메시지를 알려줍니다.
>>> a = [1,2,3] >>> id(a) 5237992 >>> b = a >>> id(b) 5237992 >>> a.append(4) >>> a [1, 2, 3, 4] >>> b [1, 2, 3, 4]
위의 예에서, 둘 다ㅏ과비동일한 신원을 가지고, 그 값은 동일해야합니다. 따라서 새 요소를 추가 한 후ㅏ, 의 가치비또한 영향을받습니다. 이러한 상황을 방지하기 위해 동일한 ID를 참조하지 않고 한 개체에서 다른 개체로 값을 복사하려는 경우 모든 방법에 대한 방법은 다음을 사용하는 것입니다.딥 카피모듈에서부(Python 문서에 링크). 목록의 경우 수행 할 수도 있습니다.b = a [:].
Scikit-learn (sklearn)강력한 오픈 소스입니다기계 학습 라이브러리Python 프로그래밍 언어 위에 구축되었습니다. 이 라이브러리에는 다양한 분류, 회귀 및 클러스터링 알고리즘을 포함하여 기계 학습 및 통계 모델링을위한 많은 효율적인 도구가 포함되어 있습니다.
이 기사에서는 scikit-learn 라이브러리와 관련된 6 가지 트릭을 보여 주어 특정 프로그래밍 방식을 좀 더 쉽게 할 수 있습니다.
1. 임의 더미 데이터 생성
임의의 '더미'데이터를 생성하기 위해make_classification ()의 경우 기능분류 데이터, 및make_regression ()의 경우 기능회귀 데이터. 이것은 디버깅 할 때나 (작은) 임의의 데이터 세트에서 특정 작업을 시도하려는 경우에 매우 유용합니다.
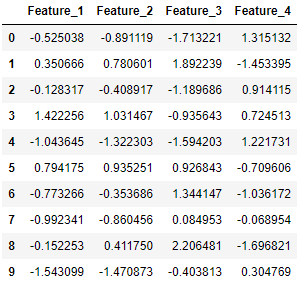
아래에서는 4 개의 특성 (X에 있음)과 클래스 레이블 (y에 있음)로 구성된 10 개의 분류 데이터 포인트를 생성합니다. 여기서 데이터 포인트는 네거티브 클래스 (0) 또는 포지티브 클래스 (1)에 속합니다.
from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=10, n_features=4, n_classes=2, random_state=123)
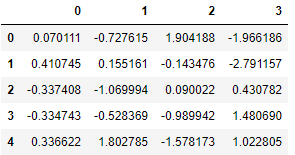
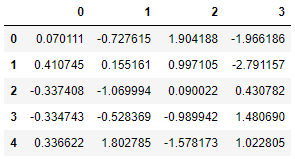
Scikit-learn은돌리다누락 된 값. 여기에서는 두 가지 접근 방식을 고려합니다. 그만큼SimpleImputer클래스는 결 측값을 대치하기위한 기본 전략을 제공합니다 (예 : 평균 또는 중앙값을 통해). 보다 정교한 접근 방식KNNImputer클래스는 다음을 사용하여 결 측값을 채우기위한 대치를 제공합니다.K- 최근 접 이웃접근하다. 각 누락 된 값은n_neighbors특정 기능에 대한 값이있는 최근 접 이웃. 이웃 값은 균일하게 평균화되거나 각 이웃까지의 거리에 따라 가중치가 부여됩니다.
아래에서는 두 대치 방법을 사용하는 예제 응용 프로그램을 보여줍니다.
from sklearn.experimental import enable_iterative_imputer from sklearn.impute import SimpleImputer, KNNImputer from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=5, n_features=4, n_classes=2, random_state=123) X = pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])print(X.iloc[1,2])
>>> 2.21298305
X [1, 2]를 누락 된 값으로 변환합니다.
X.iloc[1, 2] = float('NaN')X
먼저 우리는단순 전가:
imputer_simple = SimpleImputer()
pd.DataFrame(imputer_simple.fit_transform(X))
결과 값-0.143476.
다음으로 우리는KNN 입력, 2 개의 가장 가까운 이웃이 고려되고 이웃에 균일 한 가중치가 부여됩니다.
그만큼관로scikit-learn의 도구는 기계 학습 모델을 단순화하는 데 매우 유용합니다. 파이프 라인을 사용하여 여러 단계를 하나로 연결하여 데이터가 고정 된 일련의 단계를 거치도록 할 수 있습니다. 따라서 모든 단계를 개별적으로 호출하는 대신 파이프 라인은 모든 단계를 하나의 시스템으로 연결합니다. 이러한 파이프 라인을 생성하기 위해 우리는make_pipeline함수.
아래에는 파이프 라인이 누락 된 값 (있는 경우)을 대치하는 대치 자와 로지스틱 회귀 분류기로 구성된 간단한 예가 나와 있습니다.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import pandas as pdX, y = make_classification(n_samples=25, n_features=4, n_classes=2, random_state=123)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
scikit-learn을 통해 생성 된 파이프 라인 모델은 다음을 사용하여 쉽게 저장할 수 있습니다.joblib. 모델에 큰 데이터 배열이 포함 된 경우 각 배열은 별도의 파일에 저장됩니다. 로컬에 저장되면 새 응용 프로그램에서 사용할 모델을 쉽게로드 (또는 복원) 할 수 있습니다.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import joblibX, y = make_classification(n_samples=20, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
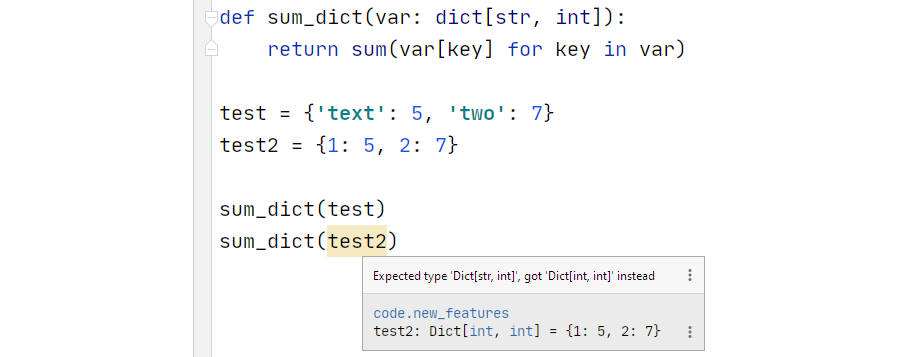
가장 잘 알려진 분류 알고리즘 중 하나는의사 결정 트리, 특징매우 직관적 인 나무 모양의 시각화. 의사 결정 트리의 아이디어는 설명 기능을 기반으로 데이터를 더 작은 영역으로 분할하는 것입니다. 그런 다음 테스트 관찰이 속한 지역에서 훈련 관찰 중 가장 일반적으로 발생하는 클래스는 예측입니다. 데이터가 지역으로 분할되는 방법을 결정하려면 다음을 적용해야합니다.분할 측정각 기능의 관련성과 중요성을 결정합니다. 잘 알려진 분할 측정으로는 정보 이득, 지니 지수 및 교차 엔트로피가 있습니다.
아래에서는 사용 방법에 대한 예를 보여줍니다.plot_treescikit-learn의 기능 :
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier, plot_tree from sklearn.datasets import make_classification
X, y = make_classification(n_samples=50, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
이 예에서는 네거티브 클래스 (0) 또는 포지티브 클래스 (1)에 속하는 40 개의 훈련 관찰에 대한 의사 결정 트리를 피팅하고 있습니다.이진 분류 문제. 트리에는 두 가지 종류의 노드가 있습니다.내부 노드(예측 자 공간이 더 분할 된 노드) 또는터미널 노드(종료점). 두 노드를 연결하는 트리의 세그먼트를가지.
의사 결정 트리의 각 노드에 대해 제공되는 정보를 자세히 살펴 보겠습니다.
그만큼분할 기준 used in the particular node is shown as e.g. ‘F2 <= -0.052’. This means that every data point that satisfies the condition that the value of the second feature is below -0.052 belongs to the newly formed region to the left, and the data points that do not satisfy the condition belong to the region to the right of the internal node.
그만큼지니 지수여기서 분할 측정으로 사용됩니다. 지니 지수 (불결)는 특정 요소가 무작위로 선택되었을 때 잘못 분류되는 정도 또는 확률을 측정합니다.
노드의 '샘플'은 특정 노드에서 발견 된 훈련 관찰의 수를 나타냅니다.
노드의 '값'은 각각 네거티브 클래스 (0)와 포지티브 클래스 (1)에서 찾은 훈련 관찰의 수를 나타냅니다. 따라서 value = [19,21]은 19 개의 관측치가 네거티브 클래스에 속하고 21 개의 관측치가 해당 특정 노드의 포지티브 클래스에 속함을 의미합니다.
결론
이 기사에서는 sklearn에서 기계 학습 모델을 개선하기위한 6 가지 유용한 scikit-learn 트릭을 다뤘습니다. 이 트릭이 어떤 식 으로든 도움이 되었기를 바랍니다. scikit-learn 라이브러리를 사용할 때 다음 프로젝트에서 행운을 빕니다!
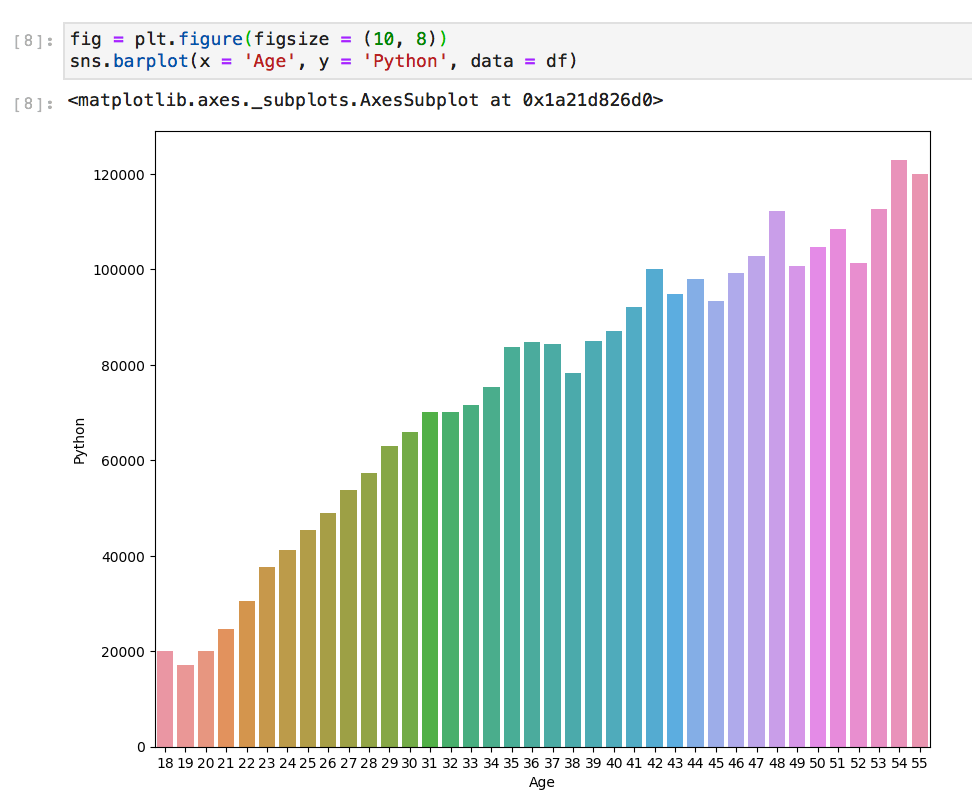
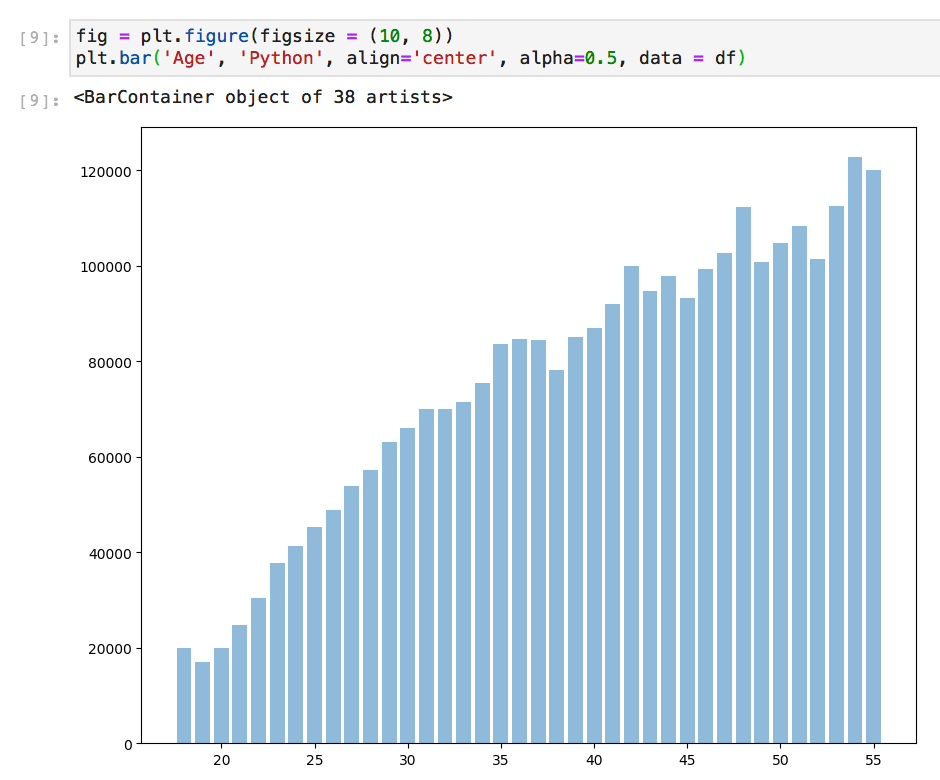
Flatiron School NYC에서 제 연구의 첫 번째 모듈을 마친 후 Seaborn과 Matplotlib를 사용하여 플롯 사용자 정의 및 디자인을 시작했습니다. 수업 중 낙서와 마찬가지로, 저는 jupyter 노트북에 다른 스타일의 플롯을 코딩하기 시작했습니다.
이 기사를 읽고 나면 모든 노트북에 대해 최소한 하나의 빠른 스타일의 플롯 코드를 염두에 두어야합니다.
더 이상 기본값, 상점 브랜드, 기본 플롯,부디!
아무것도 할 수 없다면 Seaborn을 사용하십시오.
괜찮아 보이는 플롯을 만드는 데 5 초가 주어지지 않으면 세상이 붕괴 될 것입니다. Seaborn을 사용하십시오!
Matplotlib를 사용하여 빌드 된 Seaborn은 즉각적인 디자인 업그레이드가 될 수 있습니다. x 및 y 값의 레이블과 기본이 아닌 기본 색 구성표를 자동으로 할당합니다. (— IMO : 좋은, 명확하고, 잘 포맷 된 열 레이블링과 데이터 정리를 통해 보상합니다.) Matplotlib는이를 자동으로 수행하지 않지만 플롯하려는 항목에 따라 항상 x와 y를 정의하도록 요청하지 않습니다.
다음은 Seaborn을 사용하는 것과 사용자 정의가없는 Matplotlib를 사용하는 동일한 플롯입니다.
In this post I would like to describe in detail our setup and development environment (hardware & software) and how to get it, step by step.
저는 많은 회사에서 거의 변경 (주로 하드웨어 개선)없이이 설정을 5 년 이상 사용해 왔으며 수십 개의 데이터 프로젝트 개발에 도움을주었습니다. 사용하는 동안 하나의 기능을 놓치지 않았습니다. 이것은 표준 설정입니다.페드로과나를사용WhiteBox.
왜이 가이드인가? 시간이 지남에 따라 몇 가지 기본 기능을 갖춘 견고한 환경을 찾고있는 많은 학생과 동료 데이터 과학자를 발견했습니다.
Python, R 및 해당 라이브러리와 같은 표준 데이터 과학 도구는 설치 및 유지 관리가 쉽습니다.
대부분의 라이브러리는 추가 구성없이 바로 작동합니다.
스몰 데이터에서 빅 데이터까지, 그리고 표준 머신 러닝 모델에서 딥 러닝 프로토 타이핑에 이르기까지 데이터 관련 작업의 전체 스펙트럼을 다룰 수 있습니다.
값 비싼 하드웨어와 소프트웨어를 구입하기 위해 은행 계좌를 깰 필요가 없습니다.
하드웨어
노트북에는 다음이 있어야합니다.
최소 16GB RAM. 이는 Dask 또는 Spark와 같은 도구를 사용하지 않고 메모리에서 쉽게 처리 할 수있는 데이터의 양을 제한하므로 가장 중요한 기능입니다. 많을수록 좋습니다. 여유가 있다면 32GB를 사용하십시오.
강력한 프로세서. 코어가 4 개인 Intel i5 또는 i7 이상. 명백한 이유로 데이터를 처리하는 동안 많은 시간을 절약 할 수 있습니다.
최소 4GB RAM의 NVIDIA GPU. 간단한 딥 러닝 모델을 프로토 타입하거나 미세 조정해야하는 경우에만 가능합니다. 해당 작업에 대해 거의 모든 CPU보다 훨씬 빠릅니다.랩톱에서 처음부터 심각한 딥 러닝 모델을 훈련 할 수는 없습니다..
좋은 냉각 시스템. 최소한 몇 시간 동안 워크로드를 실행합니다. 노트북이 녹지 않고 처리 할 수 있는지 확인하십시오.
256GB 이상의 SSD이면 충분합니다.
더 큰 SSD, 더 많은 RAM을 추가하거나 배터리를 쉽게 교체하는 등의 기능을 업그레이드 할 수 있습니다.
개인적으로 추천하는 것은 중고 Thinkpad 워크 스테이션 노트북입니다. 나는 초침이있다P50위에 나열된 모든 기능을 충족하는 500 유로에 구입했습니다.
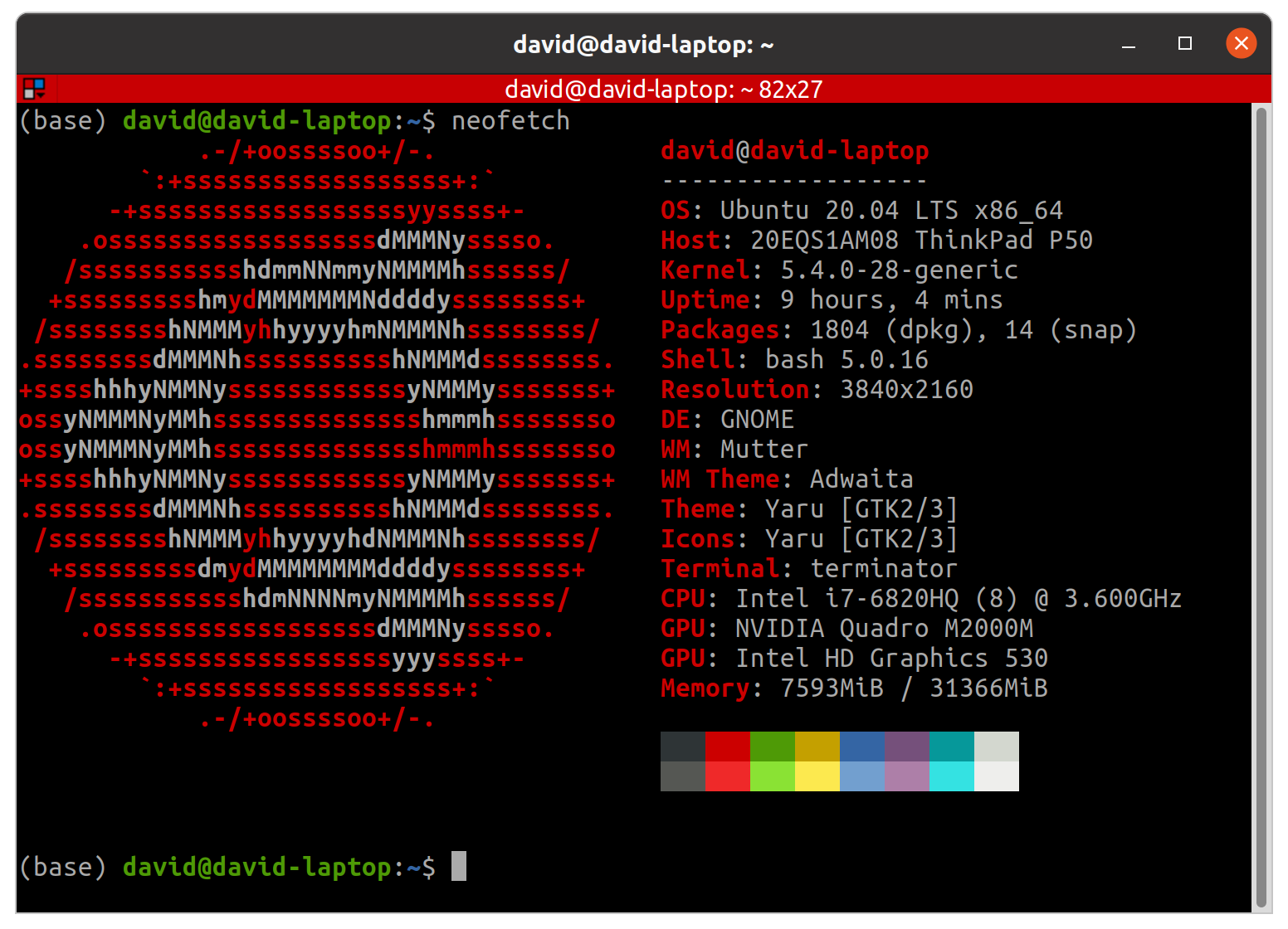
david-laptop 사양
Thinkpad는 우리가 수년 동안 사용해 왔지만 결코 실패한 적이없는 뛰어난 전문가 용 노트북입니다. 핸디캡은 가격이지만 많은 대기업이 임대 계약을 맺고 2 년마다 랩톱을 폐기하므로 사용 조건이 매우 좋은 중고 씽크 패드를 많이 찾을 수 있습니다. 이러한 노트북 중 상당수는 중고 시장에서 끝납니다. 다음에서 검색을 시작할 수 있습니다.
이러한 중고 시장의 대부분은 보증 및 송장을 제공 할 수 있습니다 (귀하가 회사 인 경우). 이 게시물을 읽고 중대형 조직에 속한 경우 가장 좋은 방법은 제조업체와 직접 임대 계약에 도달하는 것입니다.
Lenovo Thinkpad P52
Apple MacBook을 피하십시오:
여러 가지 이유로 OSX를 정말 좋아하지 않는 한 Apple 노트북을 피해야합니다. 그들은디자인 분야의 전문가와 음악 제작자를위한, 사진 작가, 동영상 및 사진 편집자, UX / UI, 웹 개발자와 같이 무거운 작업을 실행할 필요가없는 개발자도 마찬가지입니다. 2011 년부터 2016 년까지 제 주 노트북은 맥북 이었기 때문에 그 한계를 잘 알고 있습니다. 하나를 사지 않는 주된 이유는 다음과 같습니다.
동일한 하드웨어에 대해 훨씬 더 많은 비용을 지불하게됩니다.
끔찍한 공급 업체 종속으로 인해 다른 대안으로 변경하는 데 막대한 비용이 듭니다.
NVIDIA GPU를 사용할 수 없으므로 랩톱에서 딥 러닝 프로토 타이핑은 잊어 버리십시오.
마더 보드에 납땜되어 있으므로 하드웨어를 업그레이드 할 수 없습니다. 더 많은 RAM이 필요한 경우 새 노트북을 구입해야합니다.
울트라 북 (일반)을 피하십시오:
대부분의 울트라 북은 가벼운 워크로드, 웹 브라우징, 사무 생산성 소프트웨어 등을 위해 설계되었습니다. 대부분은 위에 나열된 냉각 시스템 요구 사항을 충족하지 못하며 수명이 짧습니다. 또한 업그레이드 할 수 없습니다.
운영 체제
데이터 과학 용으로 사용되는 운영 체제는 Ubuntu의 최신 LTS (장기 지원)입니다. 이 글을 쓰는 시점에서Ubuntu 20.04 LTS최신입니다.
Ubuntu 20.04 LTS
Ubuntu는 데이터 과학자로서 다른 운영 체제 및 기타 Linux 배포판에 비해 몇 가지 이점을 제공합니다.
가장 성공적인 데이터 과학 도구는 오픈 소스이며 무료 오픈 소스 인 Ubuntu에서 설치 및 사용하기 쉽습니다. 이러한 도구의 대부분의 개발자는 아마도 Linux를 사용하고있을 것입니다. TensorFlow, PyTorch 등과 같은 GPU를 지원하는 딥 러닝 프레임 워크의 경우 특히 그렇습니다.
데이터 작업을 할 때 보안은 설정의 핵심이되어야합니다. Linux는 기본적으로 Windows 또는 OS X보다 더 안전하며 소수의 사람들이 사용하기 때문에 대부분의 악성 소프트웨어는 Linux에서 실행되도록 설계되지 않았습니다.
데스크탑과 서버 모두에서 가장 많이 사용되는 Linux 배포판이며 훌륭하고 지원적인 커뮤니티입니다. 제대로 작동하지 않는 문제를 발견하면 도움을 받거나 문제 해결 방법에 대한 정보를 찾는 것이 더 쉽습니다.
대부분의 서버는 Linux 기반입니다., 해당 서버에 코드를 배포하고 싶을 것입니다. 프로덕션에 배포 할 환경에 가까울수록 좋습니다. 이것이 Linux를 플랫폼으로 사용하는 주된 이유 중 하나입니다.
운이 좋으면 전용 GPU를 사용할 수있는 경우 그래픽 전용 드라이버를 설치하지 마십시오 (설치하는 동안 확인란이 선택되지 않음). 기본 드라이버가 버그가 있고 특정 GPU (제 경우와 같이)에서 외부 모니터가 제대로 작동하지 않을 수 있으므로 나중에 설치할 수 있습니다.
설치하는 동안 타사 소프트웨어 선택 취소
설치 USB를 올바르게 만드십시오. Linux에 액세스 할 수 있으면 사용할 수 있습니다.시동 디스크 작성기, Windows 또는 OSX의 경우balenaEtcher확실한 선택입니다.
NVIDIA 드라이버
NVIDIA Linux 지원은 수년 동안 커뮤니티의 불만 중 하나였습니다. 유명한 것을 기억하십시오.
NVIDIA: 젠장!
Linus Torvalds가 NVIDIA에 대해 이야기
운 좋게도 상황이 바뀌었고 지금은 여전히 엉덩이에 통증이 있지만 모든 것이 더 쉽습니다.
conda를 초기화했는지 확인하십시오.예설치 스크립트가 물어볼 때!) 해당 줄이.bashrc파일:
# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$('/home/david/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__conda_setup" else if [ -f "/home/david/miniconda3/etc/profile.d/conda.sh" ]; then . "/home/david/miniconda3/etc/profile.d/conda.sh" else export PATH="/home/david/miniconda3/bin:$PATH" fi fi unset __conda_setup # <<< conda initialize <<<
콘다 앱이 추가됩니다.통로언제든지 액세스 할 수 있습니다. conda가 제대로 설치되었는지 확인하려면 다음을 입력하십시오.콘다터미널에서 :
콘다 도움말
conda 가상 환경에서 원하는 Python 버전은 물론 R, Java, Julia, Scala 등을 설치할 수 있습니다.
conda 및 pip 패키지 관리자 모두에서 라이브러리를 설치할 수도 있으며 동일한 가상 환경에서 완벽하게 호환되므로 둘 중 하나를 선택할 필요가 없습니다.
conda에 대해 한 가지 더 :
conda는 코드 배포를위한 고유 한 기능을 제공합니다. 라는 도서관입니다콘다 팩그리고 그것은절대로 필요한 것우리를 위해. 여러 번 액세스 할 수없는 인터넷 격리 클러스터에 라이브러리를 배포하는 데 도움이되었습니다.씨, 아니python3필요한 것을 설치하는 간단한 방법이 없습니다.
이 라이브러리를 사용하면.tar.gz원하는 곳에서 압축을 풀 수 있습니다. 그런 다음 환경을 활성화하고 평소처럼 사용할 수 있습니다.
Jupyter는 대화 형 프로그래밍 환경이 필요한 개발을 위해 데이터 과학자에게 필수입니다.
제가 몇 년 동안 배운 비결은 로컬 JupyterHub 서버를 만들고 시스템 서비스로 구성하여 매번 서버를 시작할 필요가 없도록하는 것입니다 (노트북이 시작 되 자마자 서버가 항상 가동되고 대기합니다). 또한 모든 환경에서 Python / R 커널을 감지하고 Jupyter에서 자동으로 사용할 수 있도록하는 라이브러리를 설치합니다.
9. 이제 다음으로 이동할 수 있습니다.localhost : 8000및 로그인Linux 사용자 및 비밀번호로:
JupyterHub 로그인 페이지
10. 로그인 후 클래식 모드에서 본격적인 Jupyter 서버에 액세스 할 수 있습니다 (/나무) 또는 최신 JupyterLab (/랩) :
Jupyter (클래식)
Jupyter (실험실)
이 Jupyter 설정의 가장 흥미로운 기능은 모든 conda 환경에서 커널을 감지하므로 여기에서 번거 로움없이 해당 커널에 액세스 할 수 있다는 것입니다. 해당 커널을 설치하십시오.원하는 환경에서(conda 설치 ipykernel, 또는conda 설치 irkernel) 및 JupyterHub 제어판에서 Jupyter 서버를 다시 시작합니다.
JupyterHub 제어판
커널을 설치하려는 환경을 이전에 활성화해야합니다! (conda activate <env_name>).
아시다시피 저는FOSS특히 데이터 생태계의 솔루션입니다. 소수 중 하나소유권여기서 추천 할 소프트웨어는 우리가 사용하는 소프트웨어입니다.IDE:PyCharm. 코드에 대해 진지하게 생각한다면 PyCharm과 같은 IDE를 사용하고 싶을 것입니다.
코드 완성 및 환경 검사.
네이티브 conda 지원을 포함한 Python 환경.
디버거.
Docker 통합.
Git 통합.
과학 모드 (pandas DataFrame 및 NumPy 배열 검사).
PyCharm Professional
다른 인기있는 선택에는 Pycharm의 안정성과 기능이 없습니다.
Visual Studio Code : IDE보다 텍스트 편집기에 가깝습니다. 플러그인을 사용하여 확장 할 수 있다는 것을 알고 있지만 PyCharm만큼 강력하지는 않습니다. 여러 언어로 된 프로젝트가있는 웹 개발자라면 Visual Studio Code가 좋은 선택 일 수 있습니다. 웹 개발자이고 Python이 백엔드 용으로 선택한 언어라면 데이터에 있지 않더라도 Pycharm을 사용하십시오.
Jupyter: if you have doubts about when you should be using Jupyter or PyCharm and call yourself a Data <whatever>, please attend 부트 캠프 중 하나우리는 최대한 빨리 가르칩니다.
PyCharm 설치에 대한 우리의 조언은스냅이므로 설치가 자동으로 업데이트되고 나머지 시스템과 격리됩니다. 커뮤니티 (무료) 버전 :
sudo snap install pycharm-community --classic
스칼라
Scala는 기본 Spark로 빅 데이터 프로젝트에 사용하는 언어이지만 PySpark로 전환하고 있습니다.
여기에서 우리의 추천은IntelliJ IDEA. PyCharm 개발자 (JetBrains)의 JVM 기반 언어 (Java, Kotlin, Groovy, Scala) 용 IDE입니다. 가장 좋은 기능은 Scala에 대한 기본 지원과 PyCharm과의 유사점입니다. Eclipse에서 온 경우 키 바인딩 및 단축키를 수정하여 Eclipse를 복제 할 수 있습니다.
Dask: 일을 많이 단순화하는 Dask는 일종의 Python 용 기본 Spark입니다. pandas 및 NumPy API에 더 가깝지만 경험상 Spark만큼 강력하지는 않습니다. 우리는 때때로 그것을 사용합니다.
모딘: 멀티 코어 및 아웃 오브 코어 계산을 지원하는 Pandas API를 복제합니다. 많은 코어 (32, 64)가있는 강력한 분석 서버에서 작업하고 pandas를 사용하려는 경우 특히 유용합니다. 일반적으로 코어 당 성능이 좋지 않기 때문에 Modin을 사용하면 계산 속도를 높일 수 있습니다.
데이터베이스 도구
때로는 다양한 DB 기술과 연결하고 쿼리를 만들고 데이터를 탐색 할 수있는 도구가 필요합니다. 우리의 선택은DBeaver:
DBeaver 커뮤니티
DBeaver는 다양한 데이터베이스의 드라이버를 자동으로 다운로드하는 도구입니다. 다음을 지원합니다.
데이터베이스, 스키마, 테이블 및 열 이름 완성.
연결을위한 고급 네트워킹 요구 사항 (예 : SSH 터널 등)
다음과 같이 DBeaver를 설치할 수 있습니다.
sudo snap install dbeaver-ce
가작 :
DataGrip: JetBrains의 데이터베이스 IDE는 때때로 DBeaver와 매우 유사하며 지원되는 기술은 적지 만 매우 안정적입니다.sudo snap install datagrip --classic
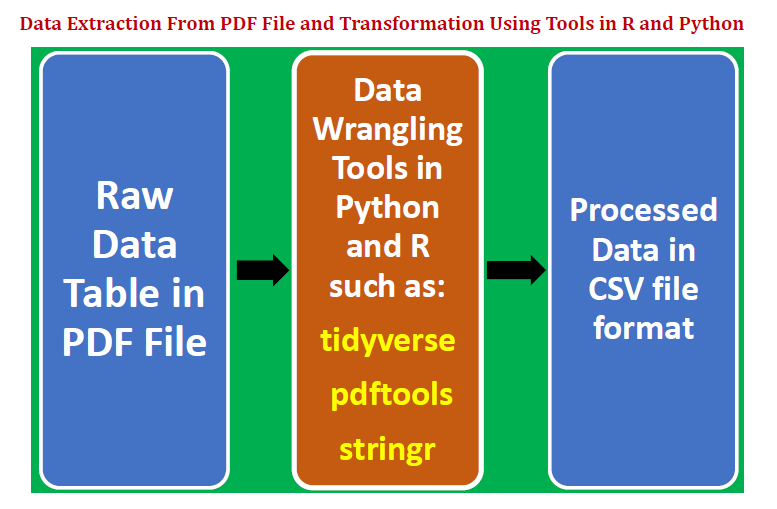
데이터는 추론 분석, 예측 분석 또는 규범 분석과 같은 데이터 과학의 모든 분석에서 핵심입니다. 모델의 예측력은 모델 구축에 사용 된 데이터의 품질에 따라 달라집니다. 데이터는 텍스트, 표, 이미지, 음성 또는 비디오와 같은 다양한 형태로 제공됩니다. 대부분의 경우 분석에 사용되는 데이터는 추가 분석에 적합한 형식으로 렌더링하기 위해 마이닝, 처리 및 변환되어야합니다.
대부분의 분석에 사용되는 가장 일반적인 유형의 데이터 세트는 쉼표로 구분 된 값 (csv) 테이블. 그러나 휴대용 문서 형식 (pdf)파일은 가장 많이 사용되는 파일 형식 중 하나입니다. 모든 데이터 과학자는pdf파일을 만들고 데이터를 "csv”그런 다음 분석 또는 모델 구축에 사용할 수 있습니다.
에서 데이터 복사pdf줄 단위 파일은 너무 지루하며 프로세스 중 인적 오류로 인해 종종 손상 될 수 있습니다. 따라서 데이터를 가져 오는 방법을 이해하는 것이 매우 중요합니다.pdf효율적이고 오류없는 방식으로.
이 기사에서는 데이터 테이블을 추출하는 데 초점을 맞출 것입니다.pdf파일. 텍스트 또는 이미지와 같은 다른 유형의 데이터를 추출하기 위해 유사한 분석을 수행 할 수 있습니다.pdf파일. 이 기사는 pdf 파일에서 숫자 데이터를 추출하는 데 중점을 둡니다. pdf 파일에서 이미지를 추출하기 위해 python에는 다음과 같은 패키지가 있습니다.광산 수레PDF에서 이미지, 텍스트 및 모양을 추출하는 데 사용할 수 있습니다.
데이터 테이블을pdf파일을 추가 분석 및 모델 구축에 적합한 형식으로 변환합니다. 하나는 Python을 사용하고 다른 하나는 R을 사용하는 두 가지 예를 제시합니다.이 기사에서는 다음 사항을 고려합니다.
에서 데이터 테이블 추출pdf파일.
데이터 랭 글링 및 문자열 처리 기술을 사용하여 데이터를 정리, 변환 및 구조화합니다.
깨끗하고 깔끔한 데이터 테이블을csv파일.
R에서 데이터 랭 글링 및 문자열 처리 패키지를 소개합니다."순수한",“pdftools”, 및"스트링거".
예제 1 : Python을 사용하여 PDF 파일에서 테이블 추출
아래 표를 a에서 추출한다고 가정 해 보겠습니다.pdf파일.
— — — — — — — — — — — — — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — — — — — — — — — —
a) 테이블을 복사하여 Excel에 붙여넣고 파일을 table_1_raw.csv로 저장합니다.
안반복자는__다음__방법. 상태가 있습니다. 상태는 반복 중에 실행을 기억하는 데 사용됩니다. 따라서 반복기는 현재 상태를 알고 있으며 이는 메모리를 효율적으로 만듭니다. 이것이 반복기가 메모리 효율적이고 빠른 애플리케이션에서 사용되는 이유입니다.
무한한 데이터 스트림 (파일 읽기 등)을 열고 다음 항목 (예 : 파일의 다음 줄)을 가져올 수 있습니다. 그런 다음 항목에 대한 작업을 수행하고 다음 항목으로 진행할 수 있습니다. 이것은 현재 항목 만 인식하면되므로 무한한 수의 요소를 반환하는 반복기를 가질 수 있음을 의미 할 수 있습니다.
반복에서 다음 값을 반환하고 다음 항목을 가리 키도록 상태를 업데이트하는 __next__ 메서드가 있습니다. 반복자는 우리가 실행할 때 항상 스트림에서 다음 항목을 가져옵니다.다음 (반복자)
반환 할 다음 항목이 없으면 반복기가 StopIteration 예외를 발생시킵니다.
결과적으로 반복자를 사용하여 린 애플리케이션을 구현할 수 있습니다.
목록, 문자열, 파일 행, 사전, 튜플 등과 같은 컬렉션은 모두 이터레이터입니다.
참고 : 반복 가능이란 무엇입니까?
안반복 가능반복자를 반환 할 수있는 개체입니다. 그것은__iter__반환하는 메서드반복자.
iterable은 반복 할 수 있고 iter ()를 호출 할 수있는 객체입니다. 그것은__getitem__0부터 시작하는 순차 인덱스를 가져 와서IndexError인덱스가 더 이상 유효하지 않을 때).
이 섹션에서는 반복 종료의 강력한 기능을 설명합니다. 이러한 기능은 다음과 같은 여러 가지 이유로 사용할 수 있습니다.
여러 반복 가능 항목이있을 수 있으며 단일 시퀀스에서 모든 반복 가능 항목의 요소에 대해 하나씩 작업을 수행하려고합니다.
또는 iterable의 모든 단일 요소에 대해 수행하려는 여러 함수가있을 때
또는 때로는 술어가 참인 한 iterable에서 요소를 삭제하고 다른 요소에 대해 조치를 수행하려고합니다.
체인
이 메서드를 사용하면 남은 요소가 없을 때까지 시퀀스의 모든 입력 이터 러블에서 요소를 반환하는 이터레이터를 만들 수 있습니다. 따라서 연속 시퀀스를 단일 시퀀스로 처리 할 수 있습니다.
chain = it.chain([1,2,3], ['a','b','c'], ['End']) for i in chain: print(i)
다음과 같이 인쇄됩니다.
1 2 삼 ㅏ 비 씨 종료
동안 드롭
이터 러블을 조건과 함께 전달할 수 있으며이 메서드는 조건이 요소에 대해 False를 반환 할 때까지 각 요소에 대한 조건 평가를 시작합니다. 조건이 요소에 대해 False로 평가 되 자마자이 함수는 이터 러블의 나머지 요소를 반환합니다.
예를 들어 작업 목록이 있고 요소를 반복하고 조건이 충족되지 않는 즉시 요소를 반환하려고한다고 가정합니다. 조건이 False로 평가되면 반복기의 나머지 요소를 반환 할 것으로 예상됩니다.
jobs = ['job1', 'job2', 'job3', 'job10', 'job4', 'job5'] dropwhile = it.dropwhile(lambda x : len(x)==4, jobs) for i in dropwhile: print(i)
이 메서드는 다음을 반환합니다.
직업 10 직업 4 직업 5
이 메소드는 job10 요소의 길이가 4자가 아니므로 job10 및 나머지 요소가 리턴되기 때문에 위의 세 항목을 리턴했습니다.
입력 조건과 이터 러블도 복잡한 객체가 될 수 있습니다.
잠시
이 메서드는 dropwhile () 메서드와 반대입니다. 기본적으로 첫 번째 조건이 False를 반환하고 다른 요소를 반환하지 않을 때까지 iterable의 모든 요소를 반환합니다.
예를 들어, 작업 목록이 있고 조건이 충족되지 않는 즉시 작업 반환을 중지하려고한다고 가정합니다.
jobs = ['job1', 'job2', 'job3', 'job10', 'job4', 'job5'] takewhile = it.takewhile(lambda x : len(x)==4, jobs) for i in takewhile: print(i)
이 메서드는 다음을 반환합니다.
직업 1 직업 2 job3
이는‘job10’의 길이가 4자가 아니기 때문입니다.
GroupBy
이 함수는 이터 러블의 연속 요소를 그룹화 한 후 이터레이터를 생성합니다. 이 함수는 키, 값 쌍의 반복자를 반환합니다. 여기서 키는 그룹 키이고 값은 키로 그룹화 된 연속 요소의 컬렉션입니다.
다음 코드 스 니펫을 고려하십시오.
iterable = 'FFFAARRHHHAADDMMAAALLIIKKK' my_groupby = it.groupby(iterable) for key, group in my_groupby: print('Key:', key) print('Group:', list(group))
그룹 속성은 반복 가능하므로 목록으로 구체화했습니다.
결과적으로 다음과 같이 인쇄됩니다.
키 : F 그룹 : [‘F’,‘F’,‘F’] 키 : A 그룹 : [‘A’,‘A’] 키 : R 그룹 : [‘R’,‘R’] 키 : H 그룹 : [‘H’,‘H’,‘H’] 키 : A 그룹 : [‘A’,‘A’] 키 : D 그룹 : [‘D’,‘D’] 키 : M 그룹 : [‘M’,‘M’] 키 : A 그룹 : [‘A’,‘A’,‘A’] 키 : L 그룹 : [‘L’,‘L’] 키 : I 그룹 : [‘I’,‘I’] 키 : K 그룹 : [‘K’,‘K’,‘K’]
복잡한 논리로 그룹화하려는 경우 키 함수를 두 번째 인수로 전달할 수도 있습니다.
티
이 메소드는 이터 러블을 분할하고 입력에서 새 이터 러블을 생성 할 수 있습니다. 출력은 주어진 항목 수에 대한 반복 가능 항목을 반환하는 반복기이기도합니다. 더 잘 이해하려면 아래 스 니펫을 검토하세요.
iterable = 'FM' tee = it.tee(iterable, 5) for i in tee: print(list(i))
고객이 회사에 투자하도록 설득하려고한다고 상상해보십시오. 모든 직원의 기록과 성과를 막대 차트 나 원형 차트가 아닌 엑셀 시트 형식으로 표시합니다. 고객의 입장에서 자신을 상상해보십시오. 그러면 어떻게 반응할까요? (너무 많은 데이터가 그렇게 압도적이지 않을까요?). 여기에서 데이터 시각화가 등장합니다.
데이터 시각화는 원시 데이터를 시각적 플롯과 그래프로 변환하여 인간의 두뇌가 더 쉽게 해석 할 수 있도록하는 방법입니다. 주요 목표는 연구 및 데이터 분석을 더 빠르게 수행하고 추세, 패턴을 효과적으로 전달하는 것입니다.
티인간의 두뇌는 긴 일반 텍스트보다 시각적으로 매력적인 데이터를 더 잘 이해하도록 프로그래밍되어 있습니다.
이 기사에서는 데이터 세트를 가져 와서 요구 사항에 따라 데이터를 정리하고 데이터 시각화를 시도해 보겠습니다. 데이터 세트는 Kaggle에서 가져옵니다. 찾을 수 있습니다여기.
먼저 외부 소스에서 데이터를로드하고 정리하기 위해 Pandas 라이브러리를 사용합니다. 이전 기사에서 팬더에 대해 더 많이 공부할 수 있습니다.여기.
사용하려면 Pandas 라이브러리를 가져와야합니다. 그것을 사용하여 가져올 수 있습니다.
import pandas as pd
Kaggle에서 가져온 CSV 파일을로드하고 이에 대해 자세히 알아 보겠습니다.
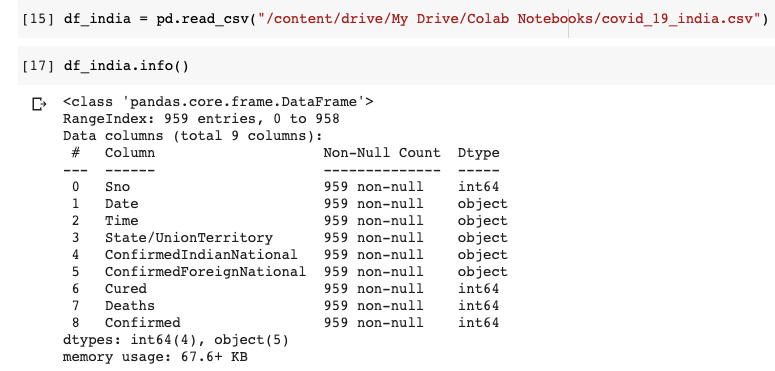
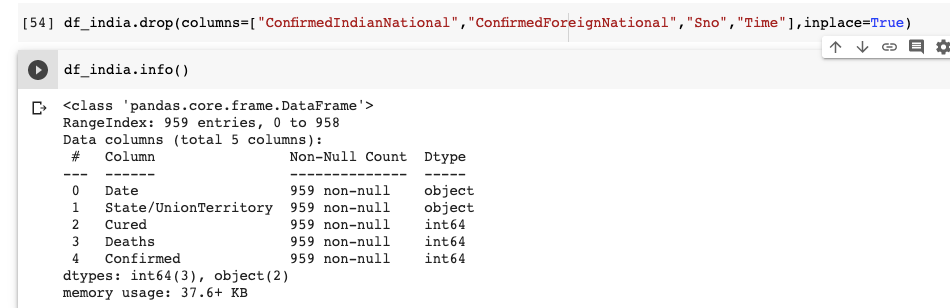
데이터 세트에 총 9 개의 열이 있음을 이해할 수 있습니다. 날짜 및 시간 열은 마지막으로 업데이트 된 날짜 및 시간을 나타냅니다. ConfirmedIndianNational 및 ConfirmedForeignNational 열은 사용하지 않습니다. 따라서이 두 개의 열을 삭제하겠습니다. 시간 열도 중요하지 않습니다. 우리도 그것을 떨어 뜨리 자. 데이터 프레임에 이미 인덱스가 있으므로 Serial No (Sno) 열도 필요하지 않습니다.
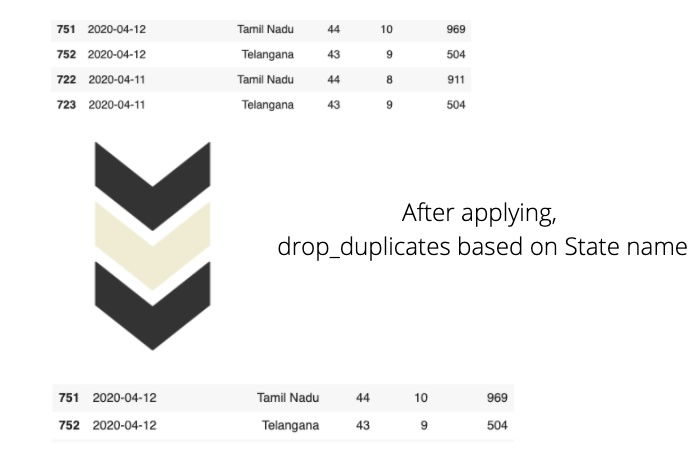
바로 데이터 프레임에 5 개의 열만 있음을 알 수 있습니다. 중복 데이터를 유지하면 불필요한 공간을 차지하고 잠재적으로 런타임이 저하 될 수 있으므로 중복 데이터를 삭제하는 것이 좋습니다.
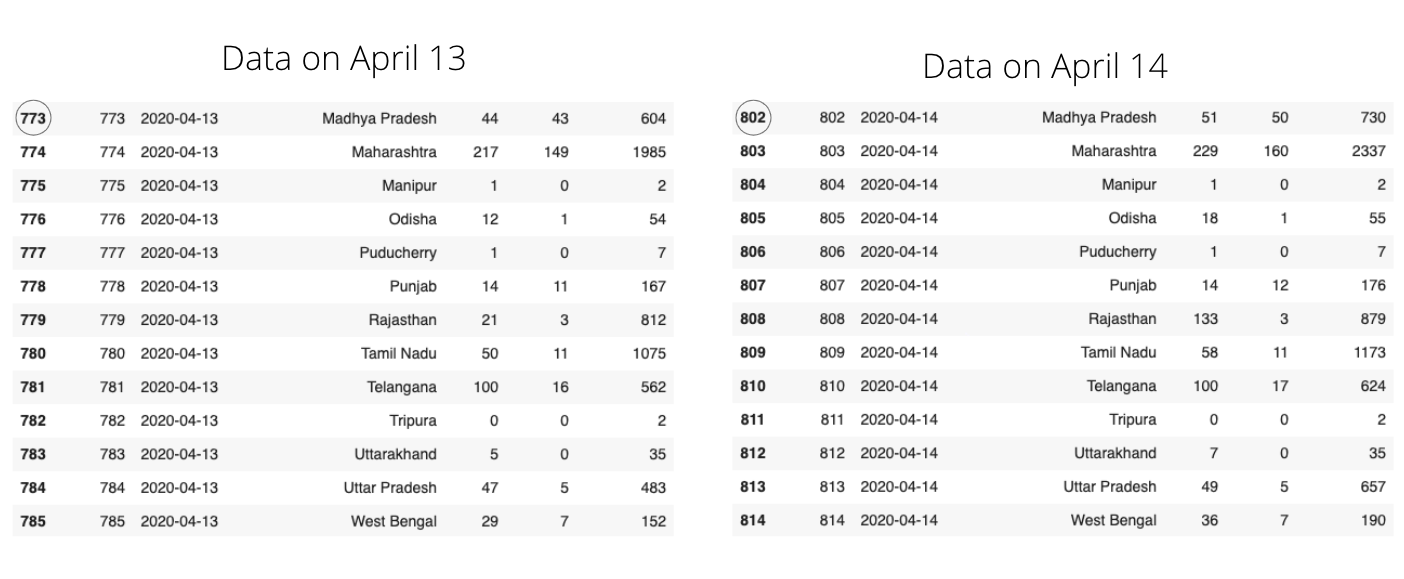
여기에서 Kaggle 데이터 세트는 매일 업데이트됩니다. 기존 데이터를 덮어 쓰는 대신 새 데이터가 추가됩니다. 예를 들어 4 월 13 일 데이터 세트에는 특정주의 누적 데이터를 나타내는 각 행이있는 925 개의 행이 있습니다. 그러나 4 월 14 일에 데이터 세트에 958 개의 행이 있었으며 이는 34 개의 새 행 (데이터 세트에 총 34 개의 상태가 있으므로)이 4 월 14 일에 추가되었음을 의미합니다.
위의 그림에서 동일한 State 이름을 볼 수 있지만 다른 열의 변경 사항을 관찰하십시오. 새로운 사례에 대한 데이터는 매일 데이터 세트에 추가됩니다. 이러한 형태의 데이터는 스프레드 추세를 파악하는 데 유용 할 수 있습니다. 처럼-
시간 경과에 따른 케이스 수의 증가입니다.
시계열 분석 수행
그러나 우리는 이전 데이터를 제외하고 최신 데이터 만 분석하는 데 관심이 있습니다. 따라서 필요하지 않은 행을 삭제하겠습니다.
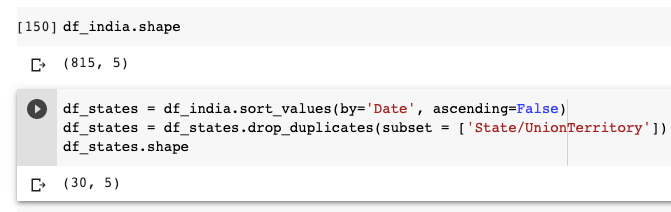
먼저 데이터를 날짜별로 내림차순으로 정렬하겠습니다. 상태 이름을 사용하여 데이터를 그룹화하여 중복 값을 제거하십시오.
df_states 데이터 프레임에 30 개의 행만 있다는 것을 알 수 있습니다. 이는 각 상태에 대한 최신 통계를 보여주는 고유 한 행이 있음을 의미합니다. 날짜 열을 사용하여 데이터 프레임을 정렬 할 때 데이터 프레임을 날짜별로 내림차순으로 정렬하고 (코드에서 ascending = False 확인) remove_duplicates는 값의 첫 번째 항목을 저장하고 모든 중복 항목을 제거합니다.
이제 데이터 시각화에 대해 이야기하겠습니다. Plotly를 사용하여 위의 데이터 프레임을 시각화합니다.
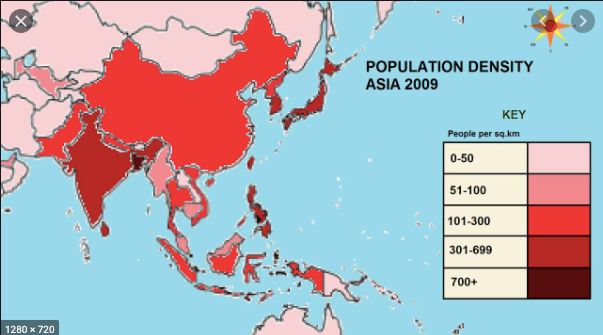
히스토그램, 막대 그래프, 산점도는 패턴과 추세를 효율적으로 설명하지만 지리 데이터를 다루기 때문에 등치 맵을 선호합니다.
등치 맵은 무엇입니까?
Plotly에 따르면 Choropleth 맵은 데이터 변수와 관련하여 색상이 지정되거나 음영 처리 된 분할 된 지리적 영역을 나타냅니다. 이러한지도는 지리적 영역에 대한 가치를 빠르고 쉽게 표시 할 수있는 방법을 제공하며 트렌드와 패턴도 공개합니다.
출처 — Youtube
위 이미지에서 영역은 인구 밀도에 따라 색상이 지정됩니다. 색이 어두울수록 특정 지역의 인구가 더 많다는 것을 의미합니다. 이제 데이터 세트와 관련하여 확인 된 사례를 기반으로 등치 맵을 생성 할 것입니다. 확진 자 수가 많을수록 특정 부위의 색이 어두워집니다.
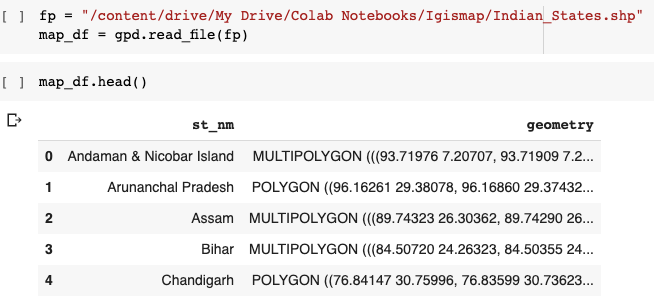
인도지도를 렌더링하려면 상태 좌표가있는 shapefile이 필요합니다. 인도 용 shapefile을 다운로드 할 수 있습니다.여기.
Wikipedia에 따르면shapefile형식은 지리 정보 시스템 (GIS)을위한 지리 공간 벡터 데이터 형식입니다.
shapefile로 작업하기 전에 GeoPandas를 설치해야합니다. GeoPandas는 지리 공간 데이터 작업을 쉽게 만들어주는 Python 패키지입니다.
pip install geopandas import geopandas as gpd
데이터 프레임에 상태 이름과 벡터 형식의 좌표가 있음을 알 수 있습니다. 이제이 shapefile을 필요한JSON체재.
import json#Read data to json.merged_json = json.loads(map_df.to_json())
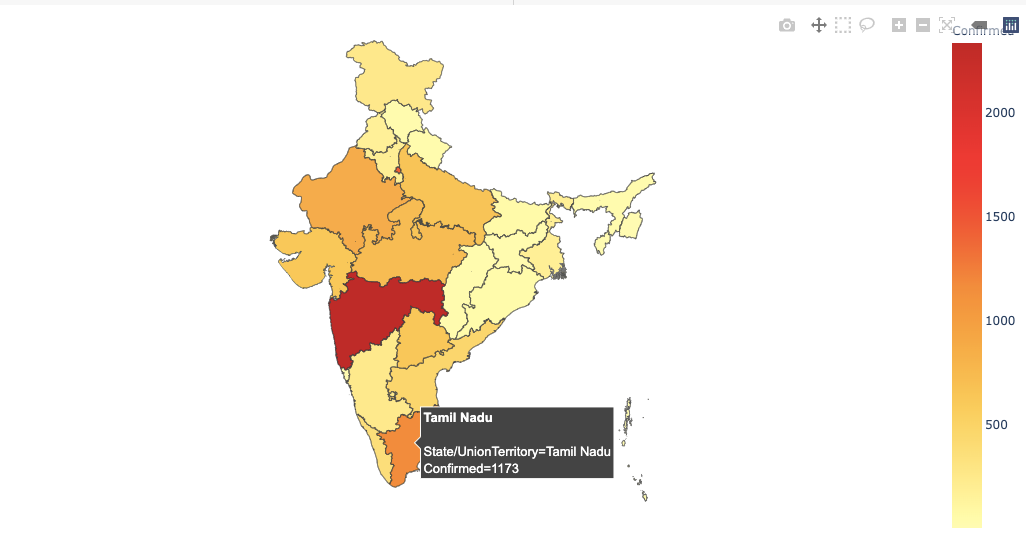
다음으로 Plotly Express를 사용하여 등치 맵을 만들 것입니다. 'px.choropleth함수. 등치 맵을 만들려면 기하학적 정보가 필요합니다.
이것은 GeoJSON 형식 (위에서 생성 한)으로 제공 될 수 있으며 각 기능에는 고유 한 식별 값이 있습니다 (예 : st_nm)
2. 미국 주 및 세계 국가를 포함하는 Plotly 내의 기존 도형
GeoJSON 데이터, 즉 (위에서 만든 merged_json)은Geojson인수 및 측정 메트릭이색깔인수px.choropleth.
모든 등치 맵에는위치주 / 국가를 매개 변수로 사용하는 인수입니다. 인도의 여러 주에 대한 등치 맵을 만들고 있으므로 State 열을 인수에 전달합니다.
첫 번째 매개 변수는 데이터 프레임 자체이며 확인 된 값에 따라 색상이 달라집니다. 우리는명백한인수fig.updtae_geos ()기본지도와 프레임을 숨기려면 False로 설정합니다. 우리는 또한 설정fitbounds = "위치"세계지도를 자동으로 확대하여 관심 영역을 표시합니다.