The topic for today is on data validation and settings management using Python type hinting. We are going to use a Python package called pydantic which enforces type hints at runtime. It provides user-friendly errors, allowing you to catch any invalid data. Based on the official documentation, Pydantic is
“… primarily a parsing library, not a validation library. Validation is a means to an end: building a model which conforms to the types and constraints provided.
In other words, pydantic guarantees the types and constraints of the output model, not the input data.”
There are three sections in this tutorial:
Setup
Implementation
Conclusion
Let’s proceed to the next section and start installing the necessary modules.
1. Setup
It is highly recommended to create a virtual environment before you proceed with the installation.
Basic installation
Open up a terminal and run the following command to install pydantic
pip install pydantic
Upgrade existing package
If you already have an existing package and would like to upgrade it, kindly run the following command:
pip install -U pydantic
Anaconda
For Anaconda users, you can install it as follows:
conda install pydantic -c conda-forge
Optional dependencies
pydantic comes with the following optional dependencies based on your needs:
email-validator — Support for email validation.
typing-extensions — Support use of Literal prior to Python 3.8.
python-dotenv — Support for dotenv file with settings.
In this section, we are going to explore some of the useful functionalities available in pydantic.
Defining an object in pydantic is as simple as creating a new class which inherits from theBaseModel. When you create a new object from the class, pydantic guarantees that the fields of the resultant model instance will conform to the field types defined on the model.
Import
Add the following import declaration at the top of your Python file.
from datetime import datetime from typing import List, Optional from pydantic import BaseModel
User class
Declare a new class which inherits the BaseModel as follow:
class User(BaseModel): id: int username : str password : str confirm_password : str alias = 'anonymous' timestamp: Optional[datetime] = None friends: List[int] = []
pydantic uses the built-in type hinting syntax to determine the data type of each variable. Let’s explore one by one what happens behind the scenes.
id — An integer variable represents an ID. Since the default value is not provided, this field is required and must be specified during object creation. Strings, bytes, or floats will be coerced to integer if possible; otherwise, an exception will be raised.
username — A string variable represents a username and is required.
password — A string variable represents a password and is required.
confirm_password — A string variable represents a confirmation password and is required. It will be used for data validation later on.
alias — A string variable represents an alias. It is not required and will be set to anonymous if it is not provided during object creation.
timestamp — A date/time field, which is not required. Default to None. pydantic will process either a unix timestamp int or a string representing the date/time.
friends — A list of integer inputs.
Object instantiation
The next step is to instantiate a new object from the User class.
You should get the following output when you print out the user variable. You can notice that id has been automatically converted to an integer, even though the input is a string. Likewise, bytes are automatically converted to integers, as shown by the friends field.
Classes that inherit the BaseModel will have the following methods and attributes:
dict() — returns a dictionary of the model’s fields and values
json() — returns a JSON string representation dictionary
copy() — returns a deep copy of the model
parse_obj() — a utility for loading any object into a model with error handling if the object is not a dictionary
parse_raw() — a utility for loading strings of numerous formats
parse_field() — similar to parse_raw() but meant for files
from_orm() — loads data into a model from an arbitrary class
schema() — returns a dictionary representing the model as JSON schema
schema_json() — returns a JSON string representation of schema()
construct() — a class method for creating models without running validation
__fields_set__ — Set of names of fields which were set when the model instance was initialized
__fields__ — a dictionary of the model’s fields
__config__ — the configuration class for the model
Let’s change the input for id to a string as follows:
data = {'id': 'a random string', 'username': 'wai foong', 'password': 'Password123', 'confirm_password': 'Password123', 'timestamp': '2020-08-03 10:30', 'friends': [1, '2', b'3']}user = User(**data)
You should get the following error when you run the code.
value is not a valid integer (type=type_error.integer)
ValidationError
In order to get better details on the error, it is highly recommended to wrap it inside a try-catch block, as follows:
from pydantic import BaseModel, ValidationError# ... codes for User classdata = {'id': 'a random string', 'username': 'wai foong', 'password': 'Password123', 'confirm_password': 'Password123', 'timestamp': '2020-08-03 10:30', 'friends': [1, '2', b'3']}try: user = User(**data) except ValidationError as e: print(e.json())
It will print out the following JSON, which indicates that the input for id is not a valid integer.
[ { "loc": [ "id" ], "msg": "value is not a valid integer", "type": "type_error.integer" } ]
Field types
pydantic provides support for most of the common types from the Python standard library. The full list is as follows:
bool
int
float
str
bytes
list
tuple
dict
set
frozenset
datetime.date
datetime.time
datetime.datetime
datetime.timedelta
typing.Any
typing.TypeVar
typing.Union
typing.Optional
typing.List
typing.Tuple
typing.Dict
typing.Set
typing.FrozenSet
typing.Sequence
typing.Iterable
typing.Type
typing.Callable
typing.Pattern
ipaddress.IPv4Address
ipaddress.IPv4Interface
ipaddress.IPv4Network
ipaddress.IPv6Address
ipaddress.IPv6Interface
ipaddress.IPv6Network
enum.Enum
enum.IntEnum
decimal.Decimal
pathlib.Path
uuid.UUID
ByteSize
Constrained types
You can enforce your own restriction via the Constrained Types. Let’s have a look at the following example:
from pydantic import ( BaseModel, NegativeInt, PositiveInt, conint, conlist, constr )class Model(BaseModel): # minimum length of 2 and maximum length of 10 short_str: constr(min_length=2, max_length=10) # regex regex_str: constr(regex=r'^apple (pie|tart|sandwich)$') # remove whitespace from string strip_str: constr(strip_whitespace=True)
# value must be greater than 1000 and less than 1024 big_int: conint(gt=1000, lt=1024)
# value is multiple of 5 mod_int: conint(multiple_of=5)
# must be a positive integer pos_int: PositiveInt
# must be a negative integer neg_int: NegativeInt
# list of integers that contains 1 to 4 items short_list: conlist(int, min_items=1, max_items=4)
Strict types
If you are looking for rigid restrictions which pass validation if and only if the validated value is of the respective type or is a subtype of that type, you can use the following strict types:
StrictStr
StrictInt
StrictFloat
StrictBool
The following example illustrates the proper way to enforce StrictBool in your inherited class.
from pydantic import BaseModel, StrictBool,class StrictBoolModel(BaseModel): strict_bool: StrictBool
The string ‘False’ will raise ValidationError as it will only accept either True or False as input.
Validator
Furthermore, you can create your own custom validators using the validator decorator inside your inherited class. Let’s have a look at the following example which determine if the id is of four digits and whether the confirm_password matches the password field.
from datetime import datetime from typing import List, Optional from pydantic import BaseModel, ValidationError, validatorclass User(BaseModel): id: int username : str password : str confirm_password : str alias = 'anonymous' timestamp: Optional[datetime] = None friends: List[int] = [] @validator('id') def id_must_be_4_digits(cls, v): if len(str(v)) != 4: raise ValueError('must be 4 digits') return v @validator('confirm_password') def passwords_match(cls, v, values, **kwargs): if 'password' in values and v != values['password']: raise ValueError('passwords do not match') return v
3. Conclusion
Let’s recap what we have learned today.
We started off with a detailed explanation on Pydantic which helps to parse and validate data.
Next, we created a virtual environment and installed Pydantic via pip or conda. It also includes support for three additional dependencies based on our use cases.
Once we were done with the installation, we explored in-depth the basic functionalities provided by the package. The basic building block is to create a new class which inherits from BaseModel.
We learned that Pydantic provides support for most of the common data types under Python standard library. We tested out both the Constrained Types and Strict Types which helps to enforce our own custom restrictions.
Lastly, you played around with the validator decorator to allow only four digits input for id, and the confirm_password must match the password field.
Thanks for reading this piece. Hope to see you again in the next article!
When Python first appeared in 1991, it was seen more as an “at your own risk” computing language. Today it is the predominant language for data science, machine learning, and software development.
A key reason behind Python’s popularity is its flexibility when it comes to adding new features and technologies like magic commands.
So, what exactly is a magic command in Python?
Magic commands are enhancements or shortcuts over the usual Python syntax designed to facilitate routine tasks.
These special commands enable us to easily control the behavior of the IPython system and solve various common problems in standard data analysis, for example, running an external script or calculating the execution time of a piece of code.
In this tutorial, I will teach you some very useful spells. These will help you to become better programming wizards.
Line magic — is denoted by a single % prefix and operates on a single line of input
Cell magic — is denoted by a double %% prefix and operates on the entire cell or multiple lines of input.
Let’s look at some of the most popular magic commands.
Run an External Script
Suppose you are working on a new project on Jupyter, and you wish to use a script that you wrote earlier. Rather than copying the entire code into a Jupyter cell, you can use some Python magic.
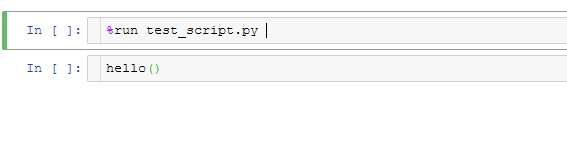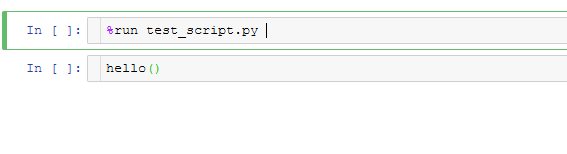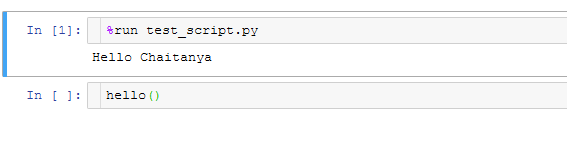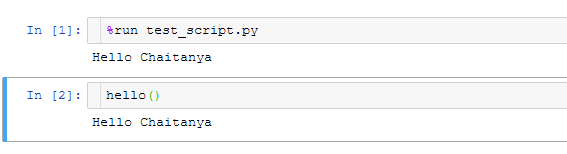
Any script can be run inside the environment of our IPython session using the %run command.
Suppose I have a file called test_script.py with the following code:
To run it, we use:
%run test_script.py
The script will run in an empty namespace with no imports or variables defined.
The behavior is identical to running the program on a command line using python test_script.py.
Note: You can provide access to already defined variables using %run -i.
All of the variables defined in the executed script are now accessible in the IPython shell.
For example, see how I reuse a function defined in the external script:
Source: Author
If needed, we can also pass arguments. Here, we pass a single integer argument along with our command.
Python is one of the most popular programming languages of the 21st Century. It is a general-purpose language used for Web Development, Artificial Intelligence, Machine Learning, Data Science, Mobile Application development, and some Video Games.
All the latest technology trends in today’s world are directly or indirectly using Python language. That is the most common reason why beginners want to learn that language.
Python — Programming Hotshot!
Python is a hot trend. People usually run after trends in Software Industry. I am not suggesting that Python is not a good programming language but it is kind of hyped.
The best thing about Python is its simplicity and ability to do tasks with less code. You can perform a task of 10–20 lines of code in some other language with almost half the number of lines of code in Python.
Even though Machine Learning and AI can be done in other programming languages, still, python is best to do so.
What’s wrong with Python
Python is too simple. It lacks Important elements of object-oriented programming. An experienced programmer will learn Python for specific needs while having command over the OOPs concept.
A beginner might have to think twice before following the herd mentality in the software industry. There are plenty of reasons why a beginner should not choose Python as their first programming language —
1. Python object creation does not need a Type
To some level, it makes coding easier. But, in my opinion, it is terrible for new programmers. They should be aware of the types of whatever objects they create, and this becomes much harder in Python language.
2. Python lacks private class members
The key to the OOPs concept is Encapsulation and Information hiding. A class should have its private members. But in Python, this is nearly impossible. (The pseudo-private members in Python, ‘__foo’ don’t make much sense.)
3. Member functions in Python are purely virtual
In Python, there is no need for Interfaces. Interfaces are important for new programmers, to understand the notion of encapsulation. But in Python, writing interfaces is just not encouraged (By the language itself).
4. Library for almost everything
There are over 137,000 Python libraries present today. Libraries are a set of useful functions that eliminate the need for writing codes from scratch. This is not a good practice for someone who is new to coding as this will drastically reduce their learning curve.
5. Issues with Thread
The original (or official) Python implementation, CPython, has a global interpretation lock. So, there are no real concurrent threads. Furthermore, the concurrency part of code in Python is just not as strong as C++ or Java.
6. Speed is an illusion
As we know Python is written in C language, so are most of its libraries. Usually, the libraries of a programming language are written in the same language but in the case of Python, most of the libraries are written in C and C++.
7. Indentation instead of curly braces
Many developers love Python’s indentation. However, code with curly braces would be better for beginners. It provides a much clearer view and also completely differentiates the blocks of code, which is easily understandable for them.
def say_hello(): print("Tab") # I use tab to make indentation here print("Space") # I use space to make indentation here Do you see the differences between tabs and spaces?
8. Dealing with Runtime Errors
Python is a dynamically typed language. It requires more testing and has errors that only show up at runtime due to dynamic nature. This could be really frustrating and discouraging for beginners.
9. What’s your Interest
If you are interested in becoming a mobile application or game developer then Python might not be the right technology for you!
Python is also not memory-efficient due to its dynamic and late-binding nature. So if your application demands speed and memory efficiency then you have to look for alternatives.
10. Deployment and Debugging challenges
One of the main issues with Python is when applications start growing, deployment becomes an issue, and also it is very difficult to debug production code for any issues.
Conclusion
If you choose Python as your first language to study, you might form some very bad coding styles (lots of public member variables, lack of interfaces, etc), and you might end up with a poor understanding of Object-Oriented Programming.
It is better to start with C++ or Java to develop a better understanding of the OOPs concept.
The truth is, there can never be a perfect programming language for everything.
Python is a good programming language, but you should consider learning it after commanding at least one Object-oriented programming language. Also, learn it if you are specifically seeking a career in Machine Learning, AI, or Data Science.
I’m Shubham Pathania. I’m a .NET developer working in the finance domain. I find C# a great language to use, and it’s also backed by a great ecosystem. I love solving complex problems and want to continue talking about the tech I use.
If you found this article helpful or thought-provoking, leave a comment, and let’s connect over LinkedIn!
Microsoft’s Visual Studio Code is arguably one of the best IDEs for developers. The same is true for Data Scientists. There are numerous tools and extensions in the VS Code that enable users with great user experience.
Often, you will require packages and modules that are not available by default installation. Some libraries or applications specify a particular version of a library to be used. Virtual environments are useful in these cases.
You can setup Python using Python distributions using Anaconda.
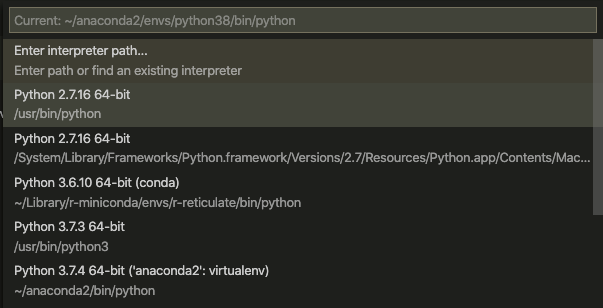
To manage your environment, in VS Code, you can select an environment of your choice from the Command Palette ( ⇧⌘P ) > Python: Select Interpreter.
Python: Select Interpreter
Selecting a Python environment
Workspaces
Workspace Settings are stored inside your workspace and only apply when the workspace is opened. They override the global user settings. This way each of the Data Science workspaces can be custom configured.
Jupyter Notebooks
Jupyter
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text.
Developed as a successor to IPython with REPL (Read-Evaluate-Print-Loop) shell, Jupyter Notebooks are the computational notebook of choice for Data Science.
The Jupyter extension is not being maintained currently, and the Python plugin from Microsoft officially includes native support for Jupyter Notebooks.
Install Jupyter
Install Jupyter in your workspace using pip install jupyter
To create a new Jupyter notebook — use the Command Palette ( ⇧⌘P ) > Create New Blank Jupyter Notebook.
Open a new Jupyter Notebook
The Jupyter server will be set to local, and a python kernel is selected based on your workspace settings.
Jupyter Notebook toolbar
Extensions
Extensions are an integral part of the Visual Studio Code experience for developers. They range from visual effects to integration with other services. You can modify your interface as much as you wish to enhance productivity, for example —Bracket Pair Colorizer helps you find that one missing or extra bracket with colors, or Trailing spaces can help you find the extraneous spaces, which is really helpful in python.
For a list of extensions that can improve your experience on Visual Studio Code, I found the following medium post really helpful.
Version control is essential for any developer or project, helping facilitate working on different modules and versions by across teams. Git, the distributed version control system for tracking changes in your source code is neatly integrated into Visual Studio Code.
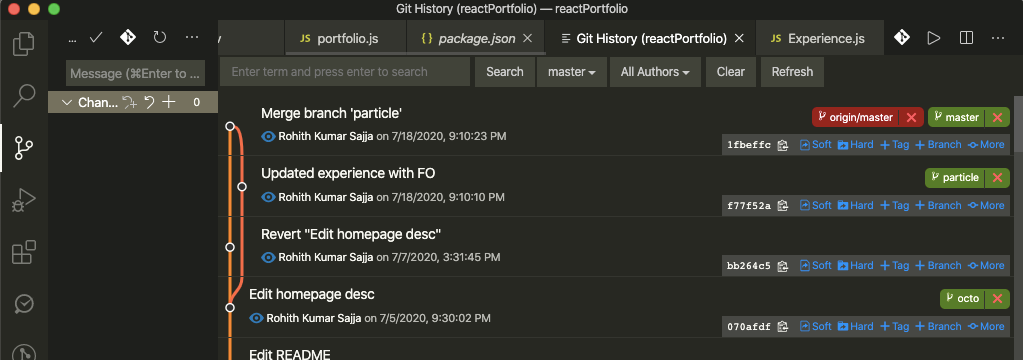
Git History (git log)
To get started with Git on VS Code, download and install the official extension names — GitHub Pull Requests and Issues. Or you can install the extension GitLens. GitLens helps you to visualize code authorship via Git blame annotations and code lens, and navigate and explore Git repositories.
Anyone with any programming experience should be familiar with the if…else statement. Basically, it creates a logical branch by examining a particular condition. When the condition is evaluated to be true, the program will execute the operations in the if clause, otherwise executing those in the else clause. Notably, the code in these two clauses will be mutually exclusive, which means that when the code in the if clause gets executed, the code in the else clause will be skipped altogether and vice versa.
Between different languages, there are variations in syntactical details. For example, Kotlin requires that you use parentheses for the condition evaluations, while parentheses are optional in Swift and Python. Both Kotlin and Swift use curly braces for each if and else clauses, but Python uses colons and indentations to denote the scope. Other languages have some other variances, but nothing is surprising to tech-savvy outsiders who are not experts in these particular languages.
In most of these languages, the if and else clauses only exist in the if…elsestatement, and they don’t appear anywhere else in the language. However, Python is unusual in this regard, because there are three other usages of the else clauses. In this article, we’ll review what they are and how we can use them with some realistic examples.
The “for” Statement
We know that iteration is one of the most common operations that we do in the program as an important way to enable automation. Specifically, we mostly use the for loop, and perform particular actions by going over some sort of iterables, such as lists, dictionaries, sets, and many others. The most basic format is shown below.
Basic Form of “for” Loop
We can append an else clause following the for loop. At what condition does the else clause get executed? Here’s the rule.
The code in the else clause will execute only when the for loop completes all the iterations. If the for loop is prematurely stopped by a break statement, the else clause will be skipped too.
Sounds confusing? Sure, is. The else clause is indeed tricky when it’s outside the context of the if…else statement. Let’s understand this usage with a simple code example.
“For…else” Statement
As shown above, when the ordered items are are available, the else clause gets executed, showing that the group order is possible. When any item is found to be unavailable, the execution will run into the break statement (Line 6), which will result in the skip of the else clause.
The “while” Statement
The while statement is particularly useful when a condition is subject to change at a later time during execution. Specifically, while the condition is true, the code in the while cause will execute until the condition becomes false. Let’s see an example first.
“While” Statement
As shown above, the code in the while clause continues to execute until the saving balance isn’t greater than zero. As indicated by the subsection title, we can also have an else clause with the while statement. Here’s the rule:
The code in the else clause will execute only when the while loop exits normally because the condition evaluates false. If the while loop is prematurely stopped by a break statement, the else clause will be skipped too.
I know that it’s confusing as well. It’s better understood through a more realistic example. I’ll just simply append the else clause to the above example with a few tweaks.
“While…else” Statement
As shown above, we now set an alert level, below which, we’ll stop the withdrawal activities by executing the break statement. As you can see, when the alert level is set to 100, the while loop exits normally because the final balance reaches zero. However, when the alert level is set to 500, after the third withdrawal, the balance becomes 400, which will trigger the code execution in the if statement, and thus the break statement will make the while loop stop execution prematurely, by doing which, the else clause won’t execute.
The “try” Statement
Exception handling is a tricky task in coding. When you don’t do it, your program is very fragile. However, if you do it too much, the readability of your code is severely reduced. Thus, you need to find a balance for how much and when you need to handle exceptions. Certainly, the current article isn’t about handling exceptions in Python. Instead, let’s just talk about the feature of exception handling. Specifically, we will use the try…except statement to handle an exception in Python. Let’s see an example:
Basic Form of the “try…except” Statement
As shown above, we simply try to cast a string to an integer. When a string is able to be cast, all of the code in the try clause executes. However, when we cast a string that isn’t integer compatible, the exception is raised and handled by the code in the except clause. Pretty straightforward exception handling, right? Since this article is talking about else clauses, you can bet that we can also use an else clause in the try…except statement, and you’re absolutely right about that. Let’s see the rule:
The code in the else clause will execute only when the try clause completes normally without encountering any exceptions.
This is probably the easiest one to understand among these three else clause usages. Nevertheless, consider the following code for its specific usage.
“Try…except…else” Statement
In the above code, we move the print function that was originally in the try clause to the else clause. For these two function calls, as you can see, the else clause executes only when there is no ValueError exception raised, consistent with its intended usage.
Notably, minimizing the code in the try clause is significant, because it will inform us exactly of what code can cause exceptions, in which case, it’s the int() function. Thus, the else clause has added benefits in making our code cleaner compared to the previous two usages.
Conclusions
In this article, we reviewed three other else clauses besides the most well-known usage of else clause in the if statement. Here’s a quick recap of these three usages.
When the else clause is used in the for and while statement, the code in the else clause won’t execute if the preceding clause (for or while) encounters a break statement. Otherwise, it will execute following the preceding clause.
When the else clause is used in the try…except statement, the code in the else clause won’t execute if any exception is raised during the execution of the try clause. It will only run when the try clause raises no exceptions.
Among these three, people may be the most familiar with the else clause in the try…except statement. Regarding the other two, they can be very confusing to new Python coders. Even for those more seasoned ones, if you don’t use these under appreciated features, they can still be confusing. Thus, my advice is to know these features, which will allow you to read others’ code who may happen to use them. If you’re using these features yourself, you may want to make sure that your code readers (e.g., in a team project) can appreciate these features, too.
In a nicely written article, Set Your Jupyter Notebook up Right with this Extension[1], William Koerhsen describes how to use Jupyter notebook extensions to improve productivity by creating a notebook template. This template serves as the starting point for each of your data science journeys. We have all found ourselves typing the same boilerplate code at the start of a new investigation.
The essence of [1] is that you can put a Javascript file into a particular folder used by Jupyter’s nbextensions system, and it will be called by Jupyter each time a new notebook is created. In his article, he creates a new notebook with some basic, common Python boilerplate, and also enables a hook that forces you to rename the notebook from the default “Untitled.ipynb”. He has a companion article, Jupyter Notebook Extensions[2] that shows how to install Jupyter notebook extensions.
There is another interesting article at DrivenData.org, Cookiecutter Data Science[3] that details a helpful organization for Data Science projects.
In my particular case, the notebook template that I use expands on both [1] and [3]. It adds in some code that I know I should include but am often too lazy to add in to a one-off notebook (I’m talking about you, unittest!) Too many times I have started a project that I thought I would only use once, but ended up using multiple times, or expanded the project beyond what I initially envisioned. To avoid an unruly mess, it helps me to have some common structure that I can fill in as needed.
Although all the hard work of figuring out notebook extensions and reverse engineering Jupyter startup code has been done by W Koehrsen, manually editing the Javascript file to add each cell in the template is somewhat tedious. For any template notebook more than a few lines, there is a good chance of introducing a syntax error into the javascript file.
This article (and the code in the corresponding github repository) simplifies this process by (semi-)automatically generating the main.js file from a template Jupyter notebook. It is only semi-automatic as you must manually save your template as a .py file before running the code in notebook-template-generator.ipynb with Jupyter.
Prerequisites
If you don’t yet have Jupyter Extensions, check out this article: [2] or just run the following code in a command prompt: pip install jupyter_contrib_nbextensions && jupyter contrib nbextensions install --user and then start a new notebook server and navigate to the extensions tab). Having worked in the security space for a long time, I don't run as an administrator on my machine, so adding '--user' is necessary, at least in my case.
You will need to grab a copy of the “setup” folder from the GitHub repository referenced in [1], which is here. You can find the path where the setup directory needs to go by running the notebook-template-generator notebook; if the path does not exist it will show the path where it expects it. On my Mac using virtualenv, it ends up here: ~/development/Python/Virtualenvs/py37/lib/python3.7/site-packages/jupyter_contrib_nbextensions/nbextensions/setup This is in my home directory because I used the "--user" option when I installed jupyter nbextensions.
The GitHub repository for this article with notebook-template.ipynb and notebook-setup-generator.ipynb is here.
Running
Open both notebook-template.ipynb and notebook-setup-generator.ipynb with Jupyter. Edit notebook-template.ipynb to contain whatever you would like in a basic Jupyter notebook. Under the File menu, choose “Download as…” and pick “Python (.py)”. On macOS, this will be saved as notebook-template.py.html in the ~/Downloads directory (change get_notebook_template_path() if you want to put it somewhere else).
Next, go to notebook-setup-generator.ipynb and select Run All from the Cell menu. If all goes well, it will ask you if you would like to overwrite the existing setup/main.js file. The next time you create a new Jupyter notebook, it will be populated with a fresh copy of the cells from your version of notebook-template.ipynb.
Additional Notes
I have tested this on macOS 10.14.3 with Python 3.7.2 in a virtual environment. The parser in generate_setup_javascript() is very basic, so it’s possible that complicated notebook-template.ipynb files will not be parsed correctly.
In Koehrsen’s original Javascript function promptName, it checks to see if the new notebook is called “Untitled”; if so, it prompts you to rename it. I have that commented out in the js_postamble string in notebook-setup-generator.ipynb as it is painful when debugging your template, but feel free to re-enable it when you are happy with your template.
Learning is one of the overcommunicated but underleveraged tools of the common entrepreneur.
Everyone talks about methods of learning, but few people find realistic and authentic techniques that actually yield a net profit in the information and application categories.
Elon Musk has broken through that barrier with learning techniques that have proven successful not just once, but time and time again.
A good argument could be made that Musk has leveraged his learning by becoming a disruptor. He and his companies have shifted entire industries, including the transportation sector, the energy sector, and the space sector.
He recently announced at a press conference that his plans for his biotech company Neuralink are progressing quite nicely, hinting at yet another sector which his hands will likely shift in the coming years.
Yes, Musk is a once-in-a-lifetime genius. Likely on the same levels as Nikola Tesla, Albert Einstein, Isaac Newton. He has a different way of viewing problems than the average entrepreneur.
Of course, he reads hundreds of books. He works with top-level thinkers. He has astronomical levels of funding to put towards his every whim. But that’s not what makes him a great learner.
His learning methods aren’t that regal. In fact, his two rules for how to learn anything faster can be implemented by anyone at any time. Including you.
You, too, can be a rocket scientist, if you wanted. Here’s how.
Identify the different parts of the tree
When it comes to learning, Musk is quick to note that he believes that most people can learn more than they currently know.
When it comes to the average entrepreneur, Musk claims that they often don’t break through their perceived limits and try to learn beyond their current capacity. Or, as he goes on to clarify, they don’t know how to outline their information in a way that leads to further revelation.
In a conversation on Reddit, Musk discussed his approach to learning and the structure he uses as such:
“One bit of advice: it is important to view knowledge as sort of a semantic tree — make sure you understand the fundamental principles, i.e. the trunk and big branches, before you get into the leaves/details or there is nothing for them to hang on to.”
From this, we begin to see Elon Musk’s first rule of learning:
Rule #1 — Make sure you’re building a tree of knowledge
What does this mean for you practically? It helps the common entrepreneur understand that not everything is weighed with equal gravitas or importance.
When it comes to learning, there is a difference between material that ends up hanging from a branch and the material that makes up the base of the trunk of your tree.
It’s the periphery vs. the central.
Musk is a master of understanding what is at the core of each of the sectors his entrepreneurial ventures sit in.
He starts there, ensuring that he has the best possible grasp on the “trunk” material before moving off into the minutiae of the branches and the leaves.
Many of us do the opposite. We load up on periphery facts while never fully understanding how or why they connect back to the trunk. This outward-facing-in method leaves many of our brains overcrowded with misidentified and, ultimately, unimportant knowledge.
That’s not learning. It’s cramming.
The result of our efforts is a tree with a toothpick trunk and an overload of teeming branches, threatening to snap off as we try to cram one more idea or thought within our brains.
If you want to learn anything faster, you need to start with the materials that make up the trunk. It might be a tad slower at the onset, but without a sturdy trunk, you won’t have the base to support any additional learning and skill.
Connections power your learning
The brilliance of Elon Musk’s learning strategy isn’t necessarily in his ability to understand core central concepts.
Many entrepreneurs over generations have had solids grasp on core tenets and principles.
Musk’s brilliance is found in his second rule of learning, which underlines his ability to build vast and towering trees of intellect across multiple sectors.
Rule #2 — You can’t remember what you can’t connect
This is how Musk was able to span sectors and shift entire industries seemingly overnight.
He started with solid roots and dense trunks, and then as he began to grow his knowledge upward, he began connecting branches and leaves together with other branches and leaves from other trees.
Musk never learns a piece of information at random. Everything he intakes, he connects back to some deeper, more solid base.
Most learners today are not master gardeners, but stick collectors. We walk around life, picking up tidbits here and tidbits there until our arms are full of sticks.
Once we have a good bunch of sticks, we do what comes naturally whenever there is a pile of sticks lying around. We burn them.
We think the size of our fires equals the size of our learning. But we are slow to realize what Elon Musk has built his entire learning structure on: that fires burn out.
Musk plants trees, in rich soil, that grow to be thick and abundant centers of learning.
You can do the same. You just need to embrace his two rules. Build the trunk first, then work tirelessly on making connections.
Exponential growth
Like any new system, it might take you a bit to get the hang of it. You might actually feel like you are learning slower than you did previously. That’s okay. What you’re actually doing is building the foundation for exponential growth.
Henry Ford once said, “If you always do what you’ve always done, you’ll always get what you’ve always got.”
If you want to learn anything faster, try the Elon Musk approach, but be warned. You may end up becoming a rocket scientist far faster than you previously thought possible.
Did you know what your reading right now is data. It may just seem like a few words to you but on the back end everything you read online is data that can be taken, picked apart, and manipulated with. Simplified this is what a Web Scraper is. They go through the code that was created to make a website (HTML code) or database and take the data they want. Virtually any website can be scraped . Some sites do involve measures that stop these scrapers from taking their data, but if your good enough you can essentially scrape 99% of websites online.
If you didn’t know what a Web Scraper is, well now you have an idea and we can get to the point of why your reading this article. Money. Web Scraping can be a unique way to make money that isn’t as difficult as it sounds. In fact all the methods and examples I'm going to show you took less than 50 lines of code to make, and can be learned in only a couple of hours. So with that said let me show you...
3 ways to make Money Using Web Scraping
1. Creating Bots
A bot is just a technical term for a program that does a specific action. Depending what you make this action to be, you can sell it to those who don’t have the technical abilities to make it themselves.
To show how you can create a bot and sell it, I created an Airbnb bot. This bot allows the user to input a location and it will return all the houses that Airbnb offers at that location including the price, rating, number of guests allowed, bedrooms, beds, and baths. All of this being done by web scraping the data of each posting on the Airbnb website.
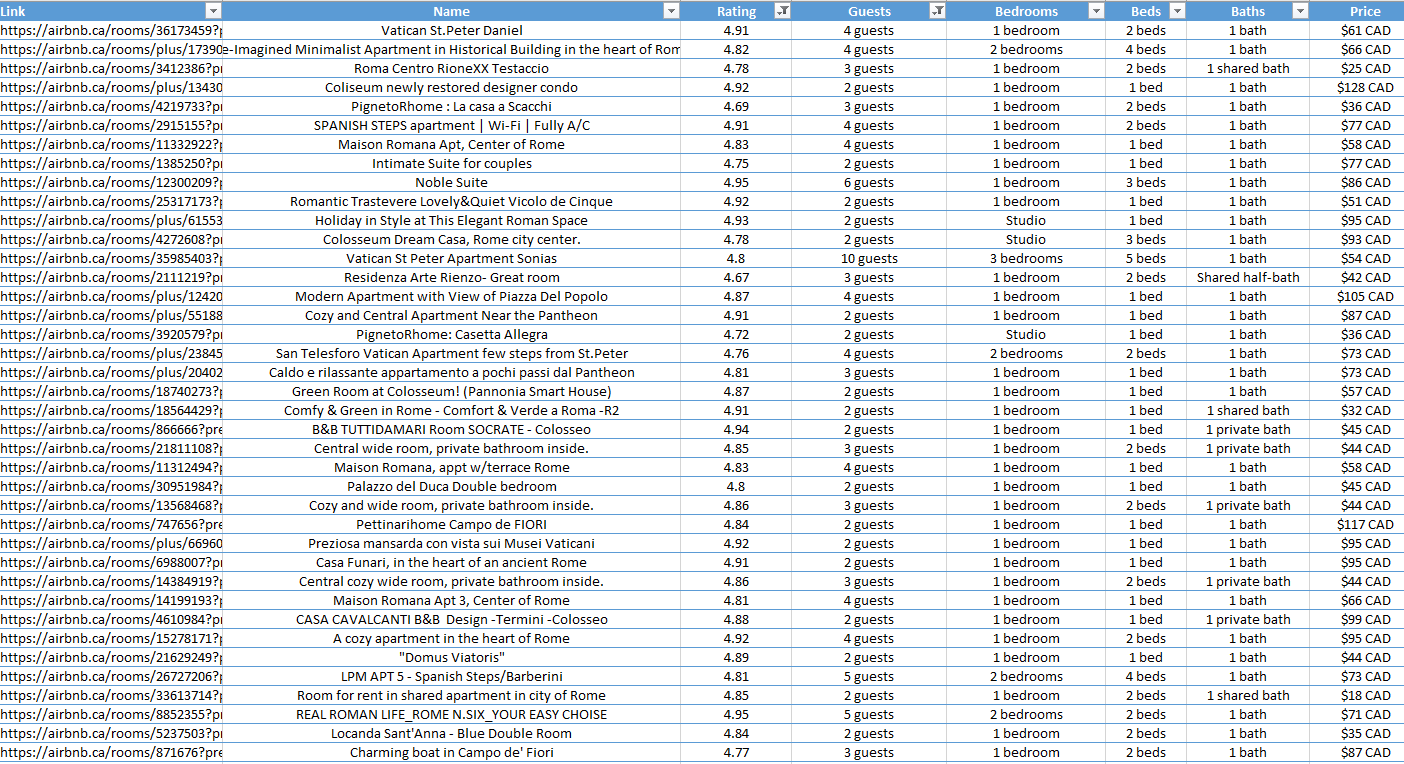
To demonstrate the bot in action I’m going to input a location. Lets say I want to search for Airbnb’s in Rome, Italy. I simply input Rome into the bot, and it returns 272 unique Airbnb’s within seconds in an organized excel spreadsheet.
It is now much easier to see all the houses/features and their comparisons to other postings. It is also much easier to filter through. I live in a family of 4 and if we were to go to Rome we would look for an Airbnb with at least 2 beds at a decent price. Now with this clean organized spreadsheet, excel makes it extremely easy to filter to match my needs. And out of 272 results 7 returned with my matching needs.
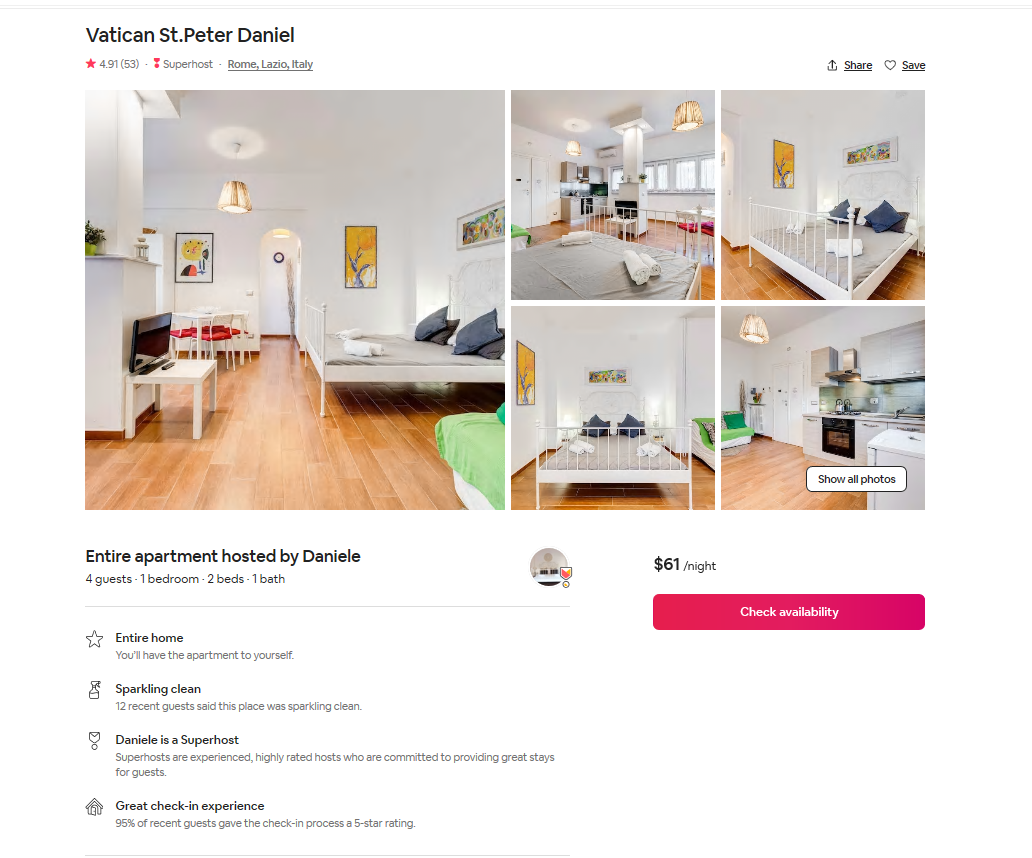
Within these 7 the one I would pick is the Vatican St.Peter Daniel, it has a very good rating and is cheapest out of the 7 with a cost of $61 per night. So after I pick the one I want, I would simply copy the link of the posting into a browser and book it then.
Looking for places to stay can be an extremly daunting task when going on vacation, I’m sure most of us have felt that at one time or another. Because of this there are those that are willing to pay just to make this process easier. With this bot I made the process easier. You just saw me book a room with all my matching needs at a good price within 5 minutes.
Trust me people are willing to pay to make their lives just a bit easier.
2. Reselling
One of the most common uses of web scraping, is getting prices off websites. There are those who create web scraping programs that run everyday and return the price of a specific product, and when the price drops to a certain amount the program will automatically buy the product before its sold out. Then since the demand for the product will be higher than the supply they resell the product at a higher price to make a profit. This is just one example of the many reselling tactics that web scrapers use.
Another one which I will show you an example of can save you a lot of money and make a lot for you too.
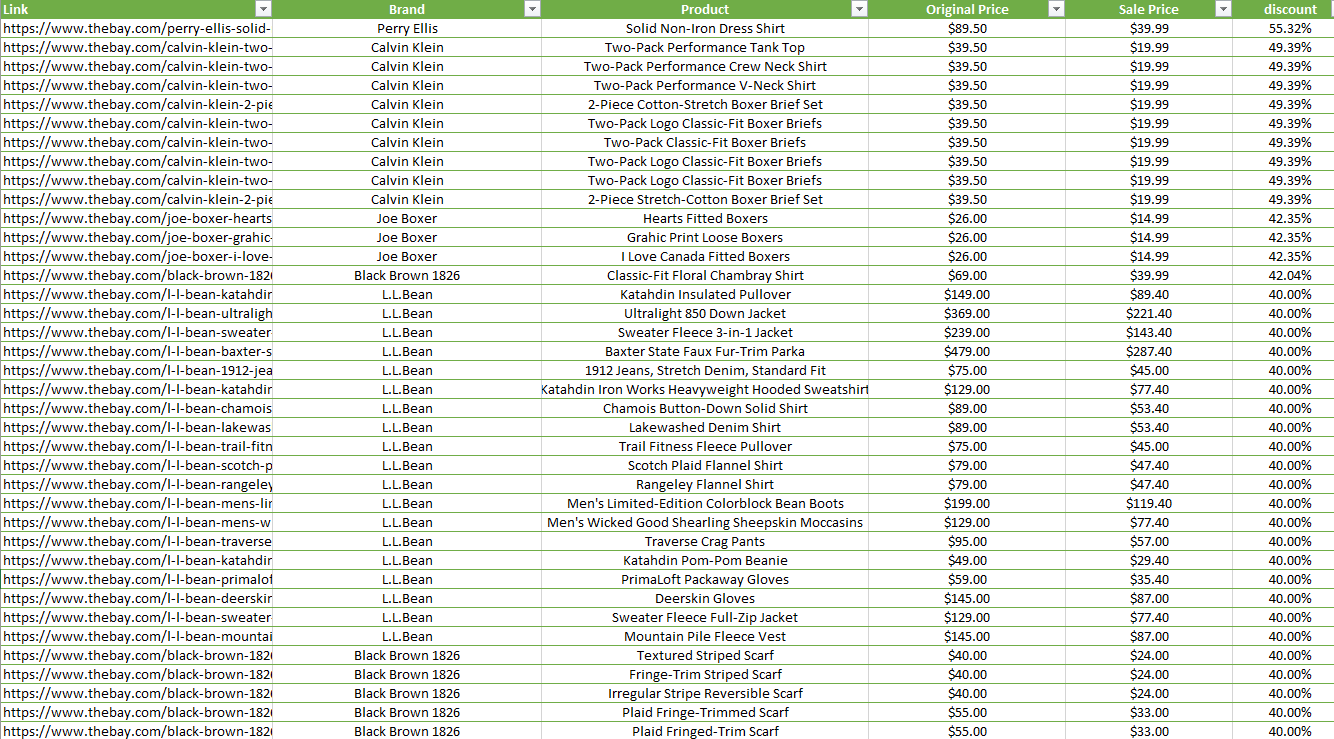
Every retail website has limited deals and sales, where they will display the original price and the sale price. But what they don’t do is show how much is actually discounted off the original price. For example if a watch originally costs $350 and the sale price is $300 you would think $50 off would be a lot of money but it’s actually only a 14.2% discount. Now if a T-shirt originally costs $50 and the sale price is $40, you might see $10 being not that much off the original price, but in fact the discount is larger than the watch at 20%. Therefore you can save/make money by buying the products with the highest discounted %.
Using Hudson's’ Bay, a department store that has numerous of sales on all kinds of brands, were going to use web scraping to get the original and sale price of all the products and find the product with the highest discount.
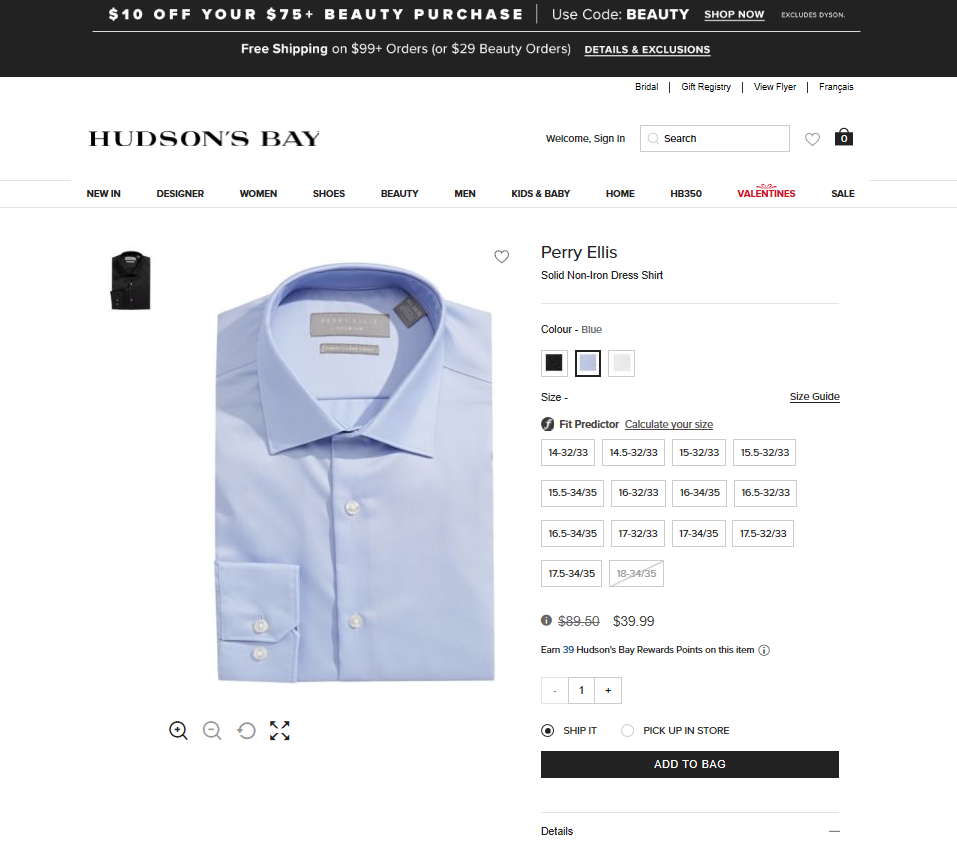
After scraping the website it returned over 900 products and as you can see there is only 1 product out of the 900 with over a 50% discount. That would be the Perry Ellis Solid Non-Iron Dress Shirt.
This sale price is only a limited time offer, so the price for this shirt will eventually go back up to around $90. So if I were to buy it now at $40 than sell it at $30 below its original at $60 when the limited sale ends, I would still make a profit of $20.
This is a method where if you find the right niche to do this is in, there is a potential to make a large amount of money.
3. Selling Data
There are millions of datasets online that are free and accessible to everyone. This data is often easily gathered and thereby offered to anyone who wants to use them. On the other hand some data is not as easy to get, and takes either time or a lot of work to put in a nice clean dataset. This has become the evolution of selling data. There are companies that focus on getting data that may be hard to obtain and structuring that data into a nice clean spreadsheet or dashboard that others can use at a certain cost.
BigDataBall is a sports data website that sells player logs, play-by-play data, and other stats at a price of $30 for a single seasons worth of data. The reason they can ask for this price is not because there the only ones that have this data, but there one of the only websites out there that offer this data in a very structured and clean dashboard that is easy to read.
Now what I’m going to do is get the same data as BigDataBall has for free and I’m going to put it into a structured dataset like the ones I did before.
Like I said before they aren’t the only ones with this type of data. Basketball-Reference.com has all the same data but its not structured meaning its data is all over the place and hard to read, and you simply cannot just download the dataset you want. This is where web scraping comes in. I’m going to web scrape the website of all the players logs for each game and put it into a structured dataset like BigDataBall.
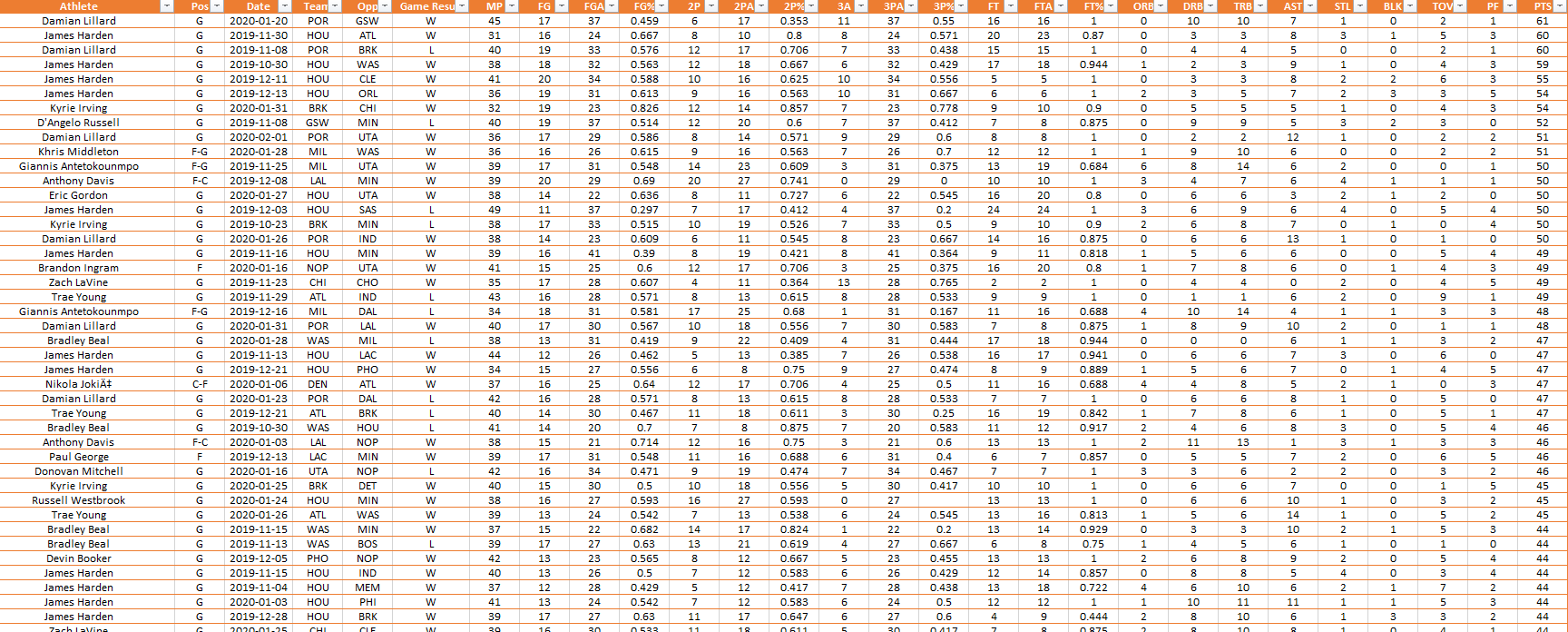
Structured Dataset of all the NBA Player Logs
After web scraping Basketball-Reference.com we got over 16000 player logs for the season so far. You can see why this data in a nice clean format can be monetized, because no one in their right mind would manually get 16000 logs of data and put it into their own dataset. But with the help of web scraping we were able to get this data in a couple of minutes and save ourselves $30.
Needless to say though you can do what BigDataBall does. Find data that is hard to obtain manually, let your computer do the work, and than sell it to those interested in having that data in a structured dataset.
Conclusion
In the world where everyone wants to make money Web Scraping has become a very unique and new way to make money on the side. Where if you apply it to the right situations it can make you a ton of money, and it is easier to do than most people think.
Who doesn’t want to get an extra hour of sleep in the morning but alas you have to do the same daily tasks of your office. The life of a data analyst is all about executing SQL queries to extract the data from the database, saving the result set into a CSV file, doing data manipulation on the file, and representing the findings.
We often do some tasks daily where we have to pull out the data from the database, do some data manipulation on excel, and then final data in the right format we have to send it to other teams for making appropriate decisions based on that. Doing the same thing on every day basis will become a tedious task and frankly speaking it will not add any value to your skills.
Here in this article, we will see how we can automate that using python. So, let’s get started:
The prerequisite is, you need to have anaconda or any similar IDE installed in your system where you can run your python code.
Firstly we need to create a connection to our database from where we want to extract the data. Here I will be creating a connection to Vertica(for MySQL database use: import mysql.connector). Below is the code you will be needed in order to create a connection to the database.
from vertica_python import connectconn_info = {'host': '123.45.67.89', 'port': 5433, 'user': 'Username', 'password': 'password', 'database': 'Schema_name', 'read_timeout': 600, # 10 minutes timeout on queries 'unicode_error': 'strict', # default throw error on invalid UTF-8 results 'ssl': False # SSL is disabled by default }connection = connect(**conn_info)
Here host will be the IP address of the server where the database resides. Once you execute this code your connection will be set up and you will be good to go to our next step which is to create a cursor. The cursor is used to execute a statement to communicate with the database. It is used to execute SQL statements, call procedures, and fetch all data from the result set.
cursor = connection.cursor()
Once we have our cursor we can execute our SQL query.
cursor.execute("Select * from table_name")
Here cursor.execute will compile your select query and throw out syntax error if you have any error in your SQL statement. After this, we need to fetch all the records from the result set and save the data into a CSV file.
import csv with open('output.csv','w') as f: writer = csv.writer(f) writer.writerow([i[0] for i in cursor.description]) for row in cursor.fetchall(): writer.writerow(row)
For saving our result set into a CSV file we need to open the file in write mode(It will overwrite the file if it exists else will create a new file).
Cursor.description will be used to fetch the header of the data. For loop is used here to write the data row by row into a CSV file. The output file will be found in your current working directory.
After fetching the data we will create a pivot table to represent the final output. To create the pivot table we need to fetch the data into a pandas DataFrame.
If you are starting with Big Data it is common to feel overwhelmed by the large number of tools, frameworks and options to choose from. In this article, I will try to summarize the ingredients and the basic recipe to get you started in your Big Data journey. My goal is to categorize the different tools and try to explain the purpose of each tool and how it fits within the ecosystem.
First let’s review some considerations and to check if you really have aBig Data problem. I will focus on open source solutions that can be deployed on-prem. Cloud providers provide several solutions for your data needs and I will slightly mention them. If you are running in the cloud, you should really check what options are available to you and compare to the open source solutions looking at cost, operability, manageability, monitoring and time to market dimensions.
Big Data Ecosystem
Data Considerations
(If you have experience with big data, skip to the next section…)
Big Data is complex, do not jump into it unless you absolutely have to. To get insights, start small, maybe use Elastic Search and Prometheus/Grafana to start collecting information and create dashboards to get information about your business. As your data expands, these tools may not be good enough or too expensive to maintain. This is when you should start considering a data lake or data warehouse; and switch your mind set to start thinkingbig.
Check the volume of your data, how much do you have and how long do you need to store for. Check the temperature! of the data, it loses value over time, so how long do you need to store the data for? how many storage layers(hot/warm/cold) do you need? can you archive or delete data?
Other questions you need to ask yourself are: What type of data are your storing? which formats do you use? do you have any legal obligations? how fast do you need to ingest the data? how fast do you need the data available for querying? What type of queries are you expecting? OLTP or OLAP? What are your infrastructure limitations? What type is your data? Relational? Graph? Document? Do you have an schema to enforce?
I could write several articles about this, it is very important that you understand your data, set boundaries, requirements, obligations, etc in order for this recipe to work.
4Vs of Big Data
Data volume is key, if you deal with billions of events per day or massive data sets, you need to apply Big Data principles to your pipeline. However, there is not a single boundary that separates “small” from “big” data and other aspects such as the velocity, your team organization, the size of the company, the type of analysis required, the infrastructure or the business goals will impact your big data journey. Let’s review some of them…
OLTP vs OLAP
Several years ago, businesses used to have online applications backed by a relational database which was used to store users and other structured data(OLTP). Overnight, this data was archived using complex jobs into a data warehouse which was optimized for data analysis and business intelligence(OLAP). Historical data was copied to the data warehouse and used to generate reports which were used to make business decisions.
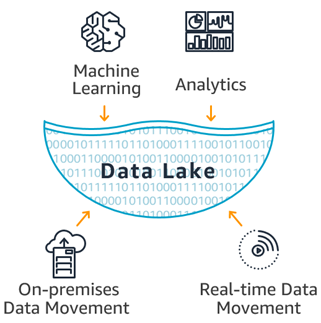
Data Warehouse vs Data Lake
As data grew, data warehouses became expensive and difficult to manage. Also, companies started to store and process unstructured data such as images or logs. With Big Data, companies started to create data lakes to centralize their structured and unstructured data creating a single repository with all the data.
In short, a data lake it’s just a set of computer nodes that store data in a HAfile system and a set of tools to process and get insights from the data. Based on Map Reduce a huge ecosystem of tools such Spark were created to process any type of data using commodity hardware which was more cost effective.The idea is that you can process and store the data in cheap hardware and then query the stored files directly without using a database but relying on file formats and external schemas which we will discuss later. Hadoop uses the HDFS file system to store the data in a cost effective manner.
For OLTP, in recent years, there was a shift towards NoSQL, using databases such MongoDB or Cassandra which could scale beyond the limitations of SQL databases. However, recent databases can handle large amounts of data and can be used for both , OLTP and OLAP, and do this at a low cost for both stream and batch processing; even transactional databases such as YugaByteDB can handle huge amounts of data. Big organizations with many systems, applications, sources and types of data will need a data warehouse and/or data lake to meet their analytical needs, but if your company doesn’t have too many information channels and/or you run in the cloud, a single massive database could suffice simplifying your architecture and drastically reducing costs.
Hadoop or No Hadoop
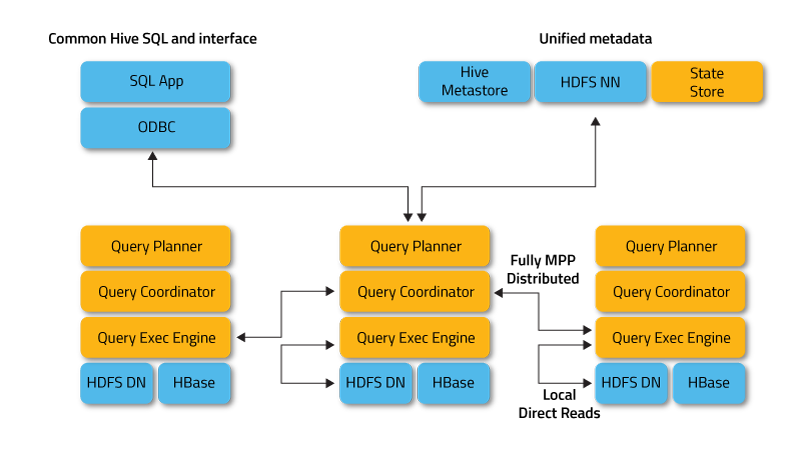
Since its release in 2006, Hadoop has been the main reference in the Big Data world. Based on the MapReduce programming model, it allowed to process large amounts of data using a simple programming model. The ecosystem grew exponentially over the years creating a rich ecosystem to deal with any use case.
Recently, there has been some criticism of the Hadoop Ecosystem and it is clear that the use has been decreasing over the last couple of years. New OLAP engines capable of ingesting and query with ultra low latency using their own data formats have been replacing some of the most common query engines in Hadoop; but the biggest impact is the increase of the number of Serverless Analytics solutions released by cloud providers where you can perform any Big Data task without managing any infrastructure.
Simplified Hadoop Ecosystem
Given the size of the Hadoop ecosystem and the huge user base, it seems to be far from dead and many of the newer solutions have no other choice than create compatible APIs and integrations with the Hadoop Ecosystem. Although HDFS is at the core of the ecosystem, it is now only used on-prem since cloud providers have built cheaper and better deep storage systems such S3 or GCS. Cloud providers also provide managed Hadoop clusters out of the box. So it seems, Hadoop is still alive and kicking but you should keep in mind that there are other newer alternatives before you start building your Hadoop ecosystem. In this article, I will try to mention which tools are part of the Hadoop ecosystem, which ones are compatible with it and which ones are not part of the Hadoop ecosystem.
Batch vs Streaming
Based on your analysis of your data temperature, you need to decide if you need real time streaming, batch processing or in many cases, both.
In a perfect world you would get all your insights from live data in real time, performing window based aggregations. However, for some use cases this is not possible and for others it is not cost effective; this is why many companies use both batch and stream processing. You should check your business needs and decide which method suits you better. For example, if you just need to create some reports, batch processing should be enough. Batch is simpler and cheaper.
The latest processing engines such Apache Flink or Apache Beam, also known as the 4th generation of big data engines, provide a unified programming model for batch and streaming data where batch is just stream processing done every 24 hours. This simplifies the programming model.
A common pattern is to have streaming data for time critical insights like credit card fraud and batch for reporting and analytics. Newer OLAP engines allow to query both in an unified way.
ETL vs ELT
Depending on your use case, you may want to transform the data on load or on read. ELT means that you can execute queries that transform and aggregate data as part of the query, this is possible to do using SQL where you can apply functions, filter data, rename columns, create views, etc. This is possible with Big Data OLAP engines which provide a way to query real time and batch in an ELT fashion. The other option, is to transform the data on load(ETL) but note that doing joins and aggregations during processing it’s not a trivial task. In general, data warehouses use ETL since they tend to require a fixed schema (star or snowflake) whereas data lakes are more flexible and can do ELT and schema on read.
Each method has its own advantages and drawbacks. In short, transformations and aggregation on read are slower but provide more flexibility. If your queries are slow, you may need to pre join or aggregate during processing phase. OLAP engines discussed later, can perform pre aggregations during ingestion.
Team Structure and methodology
Finally, your company policies, organization, methodologies, infrastructure, team structure and skills play a major role in your Big Data decisions. For example, you may have a data problem that requires you to create a pipeline but you don’t have to deal with huge amount of data, in this case you could write a stream application where you perform the ingestion, enrichment and transformation in a single pipeline which is easier; but if your company already has a data lake you may want to use the existing platform, which is something you wouldn’t build from scratch.
Another example is ETL vs ELT. Developers tend to build ETL systems where the data is ready to query in a simple format, so non technical employees can build dashboards and get insights. However, if you have a strong data analyst team and a small developer team, you may prefer ELT approach where developers just focus on ingestion; and data analysts write complex queries to transform and aggregate data. This shows how important it is to consider your team structure and skills in your big data journey.
It is recommended to have a diverse team with different skills and backgrounds working together since data is a cross functional aspect across the whole organization. Data lakes are extremely good at enabling easy collaboration while maintaining data governance and security.
Ingredients
After reviewing several aspects of the Big Data world, let’s see what are the basic ingredients.
Data (Storage)
The first thing you need is a place to store all your data. Unfortunately, there is not a single product to fit your needs that’s why you need to choose the right storage based on your use cases.
For real time data ingestion, it is common to use an append log to store the real time events, the most famous engine is Kafka. An alternative is ApachePulsar. Both, provide streaming capabilities but also storage for your events. This is usually short term storage for hot data(remember about data temperature!) since it is not cost efficient. There are other tools such Apache NiFi used to ingest data which have its own storage. Eventually, from the append log the data is transferred to another storage that could be a database or a file system.
Massive Databases
Hadoop HDFS is the most common format for data lakes, however; large scale databases can be used as a back end for your data pipeline instead of a file system; check my previous article on Massive Scale Databasesfor more information. In summary, databases such Cassandra, YugaByteDB or BigTable can hold and process large amounts of data much faster than a data lake can but not as cheap; however, the price gap between a data lake file system and a database is getting smaller and smaller each year; this is something that you need to consider as part of your Hadoop/NoHadoop decision. More and more companies are now choosing a big data database instead of a data lake for their data needs and using deep storage file system just for archival.
To summarize the databases and storage options outside of the Hadoop ecosystem to consider are:
Cassandra: NoSQL database that can store large amounts of data, provides eventual consistency and many configuration options. Great for OLTP but can be used for OLAP with pre computed aggregations (not flexible). An alternative is ScyllaDB which is much faster and better for OLAP (advanced scheduler)
YugaByteDB: Massive scale Relational Database that can handle global transactions. Your best option for relational data.
MongoDB: Powerful document based NoSQL database, can be used for ingestion(temp storage) or as a fast data layer for your dashboards
ElasticSearch: Distributed inverted index that can store large amounts of data. Sometimes ignored by many or just used for log storage, ElasticSearch can be used for a wide range of use cases including OLAP analysis, machine learning, log storage, unstructured data storage and much more. Definitely a tool to have in your Big Data ecosystem.
Remember the differences between SQL and NoSQL, in the NoSQL world, you do not model data, you model your queries.
DB comparison
Hadoop Databases
HBase is the most popular data base inside the Hadoop ecosystem. It can hold large amount of data in a columnar format. It is based on BigTable.
For data lakes, in the Hadoop ecosystem, HDFS file system is used. However, most cloud providers have replaced it with their own deep storage system such S3 or GCS.
These file systems or deep storage systems are cheaper than data bases but just provide basic storage and do not provide strong ACID guarantees.
You will need to choose the right storage for your use case based on your needs and budget. For example, you may use a database for ingestion if you budget permit and then once data is transformed, store it in your data lake for OLAP analysis. Or you may store everything in deep storage but a small subset of hot data in a fast storage system such as a relational database.
File Formats
Another important decision if you use a HDFS is what format you will use to store your files. Note that deep storage systems store the data as files and different file formats and compression algorithms provide benefits for certain use cases. How you store the data in your data lake is critical and you need to consider the format, compression and especially how you partition your data.
Some things to consider when choosing the format are:
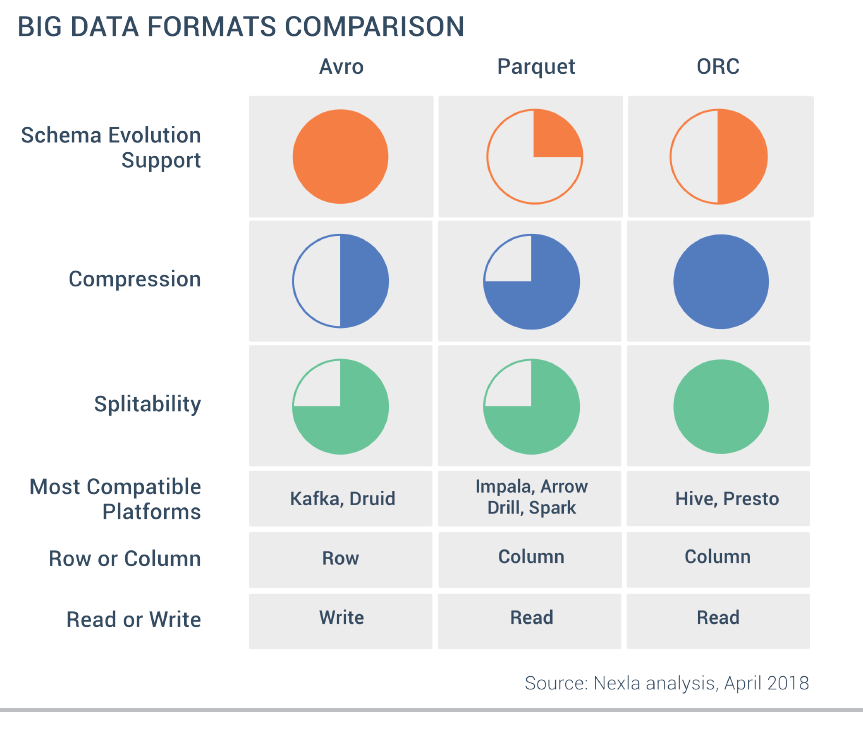
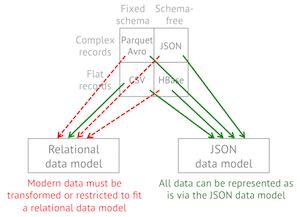
The structure of your data: Some formats accept nested data such JSON, Avro or Parquet and others do not. Even, the ones that do, may not be highly optimized for it. Avro is the most efficient format for nested data, I recommend not to use Parquet nested types because they are very inefficient. Process nested JSON is also very CPU intensive. In general, it is recommended to flat the data when ingesting it.
Performance: Some formats such Avro and Parquet perform better than other such JSON. Even between Avro and Parquet for different use cases one will be better than others. For example, since Parquet is a column based format it is great to query your data lake using SQL whereas Avro is better for ETL row level transformation.
Easy to read: Consider if you need people to read the data or not. JSON or CSV are text formats and are human readable whereas more performant formats such parquet or Avro are binary.
Compression: Some formats offer higher compression rates than others.
Schema evolution: Adding or removing fields is far more complicated in a data lake than in a database. Some formats like Avro or Parquet provide some degree of schema evolution which allows you to change the data schema and still query the data. Tools such Delta Lake format provide even better tools to deal with changes in Schemas.
Compatibility: JSON or CSV are widely adopted and compatible with almost any tool while more performant options have less integration points.
As we can see, CSV and JSON are easy to use, human readable and common formats but lack many of the capabilities of other formats, making it too slow to be used to query the data lake. ORC and Parquet are widely used in the Hadoop ecosystem to query data whereas Avro is also used outside of Hadoop, especially together with Kafka for ingestion, it is very good for row level ETL processing. Row oriented formats have better schema evolution capabilities than column oriented formats making them a great option for data ingestion.
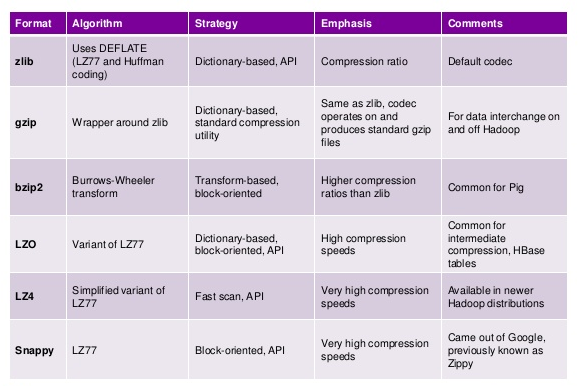
Lastly, you need to also consider how to compress the data in your files considering the trade off between file size and CPU costs. Some compression algorithms are faster but with bigger file size and others slower but with better compression rates. For more details check this article.
Compression options
I recommend using snappy for streaming data since it does not require too much CPU power. For batch bzip2 is a great option.
Again, you need to review the considerations that we mentioned before and decide based on all the aspects we reviewed. Let’s go through some use cases as an example:
Use Cases
You need to ingest real time data and storage somewhere for further processing as part of an ETL pipeline. If performance is important and budget is not an issue you could use Cassandra. The standard approach is to store it in HDFS using an optimized format as AVRO.
You need to process your data and storage somewhere to be used by a highly interactive user facing application where latency is important (OLTP), you know the queries in advance. In this case use Cassandra or another database depending on the volume of your data.
You need to serve your processed data to your user base, consistency is important and you do not know the queries in advance since the UI provides advanced queries. In this case you need a relational SQL data base, depending on your side a classic SQL DB such MySQL will suffice or you may need to use YugaByteDB or other relational massive scale database.
You need to store your processed data for OLAP analysis for your internal team so they can run ad-hoc queries and create reports. In this case, you can store the data in your deep storage file system in Parquet or ORC format.
You need to use SQL to run ad-hoc queries of historical data but you also need dashboards that need to respond in less than a second. In this case you need a hybrid approach where you store a subset of the data in a fast storage such as MySQL database and the historical data in Parquet format in the data lake. Then, use a query engine to query across different data sources using SQL.
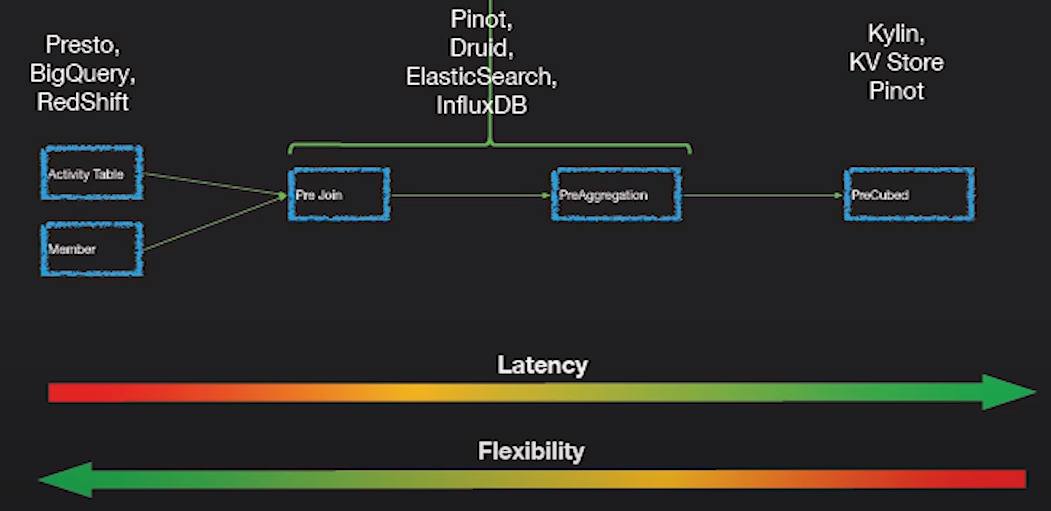
You need to perform really complex queries that need to respond in just a few milliseconds, you also may need to perform aggregations on read. In this case, use ElasticSearch to store the data or some newer OLAP system like Apache Pinot which we will discuss later.
You need to search unstructured text. In this case use ElasticSearch.
Infrastructure
Your current infrastructure can limit your options when deciding which tools to use. The first question to ask is: Cloud vs On-Prem. Cloud providers offer many options and flexibility. Furthermore, they provide Serverless solutions for your Big Data needs which are easier to manage and monitor. Definitely, the cloud is the place to be for Big Data; even for the Hadoop ecosystem, cloud providers offer managed clusters and cheaper storage than on premises. Check my other articles regarding cloud solutions.
If you are running on premises you should think about the following:
Where do I run my workloads? Definitely Kubernetes or Apache Mesosprovide a unified orchestration framework to run your applications in a unified way. The deployment, monitoring and alerting aspects will be the same regardless of the framework you use. In contrast, if you run on bare metal, you need to think and manage all the cross cutting aspects of your deployments. In this case, managed clusters and tools will suit better than libraries and frameworks.
What type of hardware do I have? If you have specialized hardware with fast SSDs and high-end servers, then you may be able to deploy massive databases like Cassandra and get great performance. If you just own commodity hardware, the Hadoop ecosystem will be a better option. Ideally, you want to have several types of servers for different workloads; the requirements for Cassandra are far different from HDFS.
Monitoring and Alerting
The next ingredient is essential for the success of your data pipeline. In the big data world, you need constant feedback about your processes and your data. You need to gather metrics, collect logs, monitor your systems, create alerts, dashboards and much more.
Use open source tools like Prometheus and Grafana for monitor and alerting. Use log aggregation technologies to collect logs and store them somewhere like ElasticSearch.
Grafana Monitoring
Leverage on cloud providers capabilities for monitoring and alerting when possible. Depending on your platform you will use a different set of tools. For Cloud Serverless platform you will rely on your cloud provider tools and best practices. For Kubernetes, you will use open source monitor solutions or enterprise integrations. I really recommend this website where you can browse and check different solutions and built your own APM solution.
Another thing to consider in the Big Data world is auditability and accountability. Because of different regulations, you may be required to trace the data, capturing and recording every change as data flows through the pipeline. This is called data provenance or lineage. Tools like Apache Atlas are used to control, record and govern your data. Other tools such Apache NiFi supports data lineage out of the box. For real time traces, check Open Telemetry or Jaeger. There are also a lot of cloud services suchDatadog.
Apache Rangerprovides a unified security monitoring framework for your Hadoop platform. Provides centralized security administration to manage all security related tasks in a central UI. It provides authorization using different methods and also full auditability across the entire Hadoop platform.
People
Your team is the key to success. Big Data Engineers can be difficult to find. Invest in training, upskilling, workshops. Remove silos and red tape, make iterations simple and use Domain Driven Design to set your team boundaries and responsibilities.
For Big Data you will have two broad categories:
Data Engineers for ingestion, enrichment and transformation. These engineers have a strong development and operational background and are in charge of creating the data pipeline. Developers, Administrators, DevOps specialists, etc will fall in this category.
Data Scientist: These can be BI specialists, data analysts, etc. in charge of generation reports, dashboards and gathering insights. Focused on OLAP and with strong business understanding, these people gather the data which will be used to make critical business decisions. Strong in SQL and visualization but weak in software development. Machine Learning specialists may also fall into this category.
Budget
This is an important consideration, you need money to buy all the other ingredients, and this is a limited resource. If you have unlimited money you could deploy a massive database and use it for your big data needs without many complications but it will cost you. So each technology mentioned in this article requires people with the skills to use it, deploy it and maintain it. Some technologies are more complex than others, so you need to take this into account.
Recipe
Now that we have the ingredients, let’s cook our big data recipe. In a nutshell the process is simple; you need to ingest data from different sources, enrich it, store it somewhere, store the metadata(schema), clean it, normalize it, process it, quarantine bad data, optimally aggregate data and finally store it somewhere to be consumed by downstream systems.
Let’s have a look a bit more in detail to each step…
Ingestion
The first step is to get the data, the goal of this phase is to get all the data you need and store it in raw format in a single repository. This is usually owned by other teams who push their data into Kafka or a data store.
For simple pipelines with not huge amounts of data you can build a simple microservices workflow that can ingest, enrich and transform the data in a single pipeline(ingestion + transformation), you may use tools such Apache Airflow to orchestrate the dependencies. However, for Big Data it is recommended that you separate ingestion from processing, massive processing engines that can run in parallel are not great to handle blocking calls, retries, back pressure, etc. So, it is recommended that all the data is saved before you start processing it. You should enrich your data as part of the ingestion by calling other systems to make sure all the data, including reference data has landed into the lake before processing.
There are two modes of ingestion:
Pull: Pull the data from somewhere like a database, file system, a queue or an API
Push: Applications can also push data into your lake but it is always recommended to have a messaging platform as Kafka in between. A common pattern is Change Data Capture(CDC) which allows us to move data into the lake in real time from databases and other systems.
As we already mentioned, It is extremely common to useKafka or Pulsaras a mediator for your data ingestion to enable persistence, back pressure, parallelization and monitoring of your ingestion. Then, use Kafka Connect to save the data into your data lake. The idea is that your OLTP systems will publish events to Kafka and then ingest them into your lake. Avoid ingesting data in batch directly through APIs; you may call HTTP end-points for data enrichment but remember that ingesting data from APIs it’s not a good idea in the big data world because it is slow, error prone(network issues, latency…) and can bring down source systems. Although, APIs are great to set domain boundaries in the OLTP world, these boundaries are set by data stores(batch) or topics(real time) in Kafka in the Big Dataworld. Of course, it always depends on the size of your data but try to use Kafka or Pulsar when possible and if you do not have any other options; pull small amounts of data in a streaming fashion from the APIs, not in batch. For databases, use tools such Debezium to stream data to Kafka (CDC).
To minimize dependencies, it is always easier if the source system push data to Kafka rather than your team pulling the data since you will be tightly coupled with the other source systems. If this is not possible and you still need to own the ingestion process, we can look at two broad categories for ingestion:
Un Managed Solutions: These are applications that you develop to ingest data into your data lake; you can run them anywhere. This is very common when ingesting data from APIs or other I/O blocking systems that do not have an out of the box solution, or when you are not using the Hadoop ecosystem. The idea is to use streaming libraries to ingest data from different topics, end-points, queues, or file systems. Because you are developing apps, you have full flexibility. Most libraries provide retries, back pressure, monitoring, batching and much more. This is a code yourself approach, so you will need other tools for orchestration and deployment. You get more control and better performance but more effort involved. You can have a single monolith or microservices communicating using a service bus or orchestrated using an external tool. Some of the libraries available are Apache Camel or Akka Ecosystem(Akka HTTP + Akka Streams + Akka Cluster + Akka Persistence + Alpakka). You can deploy it as a monolith or as microservices depending on how complex is the ingestion pipeline. If you use Kafka or Pulsar, you can use them as ingestion orchestration tools to get the data and enrich it. Each stage will move data to a new topic creating a DAGin the infrastructure itself by using topics for dependency management. If you do not have Kafka and you want a more visual workflow you can use Apache Airflow to orchestrate the dependencies and run the DAG. The idea is to have a series of services that ingest and enrich the date and then, store it somewhere. After each step is complete, the next one is executed and coordinated by Airflow. Finally, the data is stored in some kind of storage.
Managed Solutions: In this case you can use tools which are deployed in your cluster and used for ingestion. This is common in the Hadoop ecosystem where you have tools such Sqoop to ingest data from your OLTP databases and Flume to ingest streaming data. These tools provide monitoring, retries, incremental load, compression and much more.
NiFi is one of these tools that are difficult to categorize. It is a beast on its own. It can be used for ingestion, orchestration and even simple transformations. So in theory, it could solve simple Big Data problems. It is a managed solution. It has a visual interface where you can just drag and drop components and use them to ingest and enrich data. It has over 300 built in processors which perform many tasks and you can extend it by implementing your own.
NiFi workflow
It has its own architecture, so it does not use any database HDFS but it has integrations with many tools in the Hadoop Ecosystem. You can call APIs, integrate with Kafka, FTP, many file systems and cloud storage. You can manage the data flow performing routing, filtering and basic ETL. For some use cases, NiFi may be all you need.
However, NiFi cannot scale beyond a certain point, because of the inter node communication more than 10 nodes in the cluster become inefficient. It tends to scale vertically better, but you can reach its limit, especially for complex ETL. However, you can integrate it with tools such Spark to process the data. NiFi is a great tool for ingesting and enriching your data.
Modern OLAP engines such Druid or Pinot also provide automatic ingestion of batch and streaming data, we will talk about them in another section.
You can also do some initial validation and data cleaning during the ingestion, as long as they are not expensive computations or do not cross over the bounded context, remember that a null field may be irrelevant to you but important for another team.
The last step is to decide where to land the data, we already talked about this. You can use a database or a deep storage system. For a data lake, it is common to store it in HDFS, the format will depend on the next step; if you are planning to perform row level operations, Avro is a great option. Avro also supports schema evolution using an external registry which will allow you to change the schema for your ingested data relatively easily.
Metadata
The next step after storing your data, is save its metadata (information about the data itself). The most common metadata is the schema. By using an external metadata repository, the different tools in your data lake or data pipeline can query it to infer the data schema.
If you use Avro for raw data, then the external registry is a good option. This way you can easily de couple ingestion from processing.
Once the data is ingested, in order to be queried by OLAP engines, it is very common to use SQL DDL. The most used data lake/data warehouse tool in the Hadoop ecosystem is Apache Hive, which provides a metadata store so you can use the data lake like a data warehouse with a defined schema. You can run SQL queries on top of Hive and connect many other tools such Spark to run SQL queries using Spark SQL. Hive is an important tool inside the Hadoop ecosystem providing a centralized meta database for your analytical queries. Other tools such Apache Tajo are built on top of Hive to provide data warehousing capabilities in your data lake.
Apache Impalais a native analytic database for Hadoop which provides metadata store, you can still connect to Hive for metadata using Hcatalog.
Apache Phoenix has also a metastore and can work with Hive. Phoenix focuses on OLTP enabling queries with ACID properties to the transactions. It is flexible and provides schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store. ApacheDruid or Pinotalso provide metadata store.
Processing
The goal of this phase is to clean, normalize, process and save the data using a single schema. The end result is a trusted data set with a well defined schema.
Generally, you would need to do some kind of processing such as:
Validation: Validate data and quarantine bad data by storing it in a separate storage. Send alerts when a certain threshold is reached based on your data quality requirements.
Wrangling and Cleansing: Clean your data and store it in another format to be further processed, for example replace inefficient JSON with Avro.
Normalization and Standardization of values
Rename fields
…
Remember, the goal is to create a trusted data set that later can be used for downstream systems. This is a key role of a data engineer. This can be done in a stream or batch fashion.
The pipeline processing can be divided in three phases in case of batch processing:
Pre Processing Phase: If the raw data is not clean or not in the right format, you need to pre process it. This phase includes some basic validation, but the goal is to prepare the data to be efficiently processed for the next stage. In this phase, you should try to flatten the data and save it in a binary format such Avro. This will speed up further processing. The idea is that the next phase will perform row level operations, and nested queries are expensive, so flattening the data now will improve the next phase performance.
Trusted Phase: Data is validated, cleaned, normalized and transformed to a common schema stored in Hive. The goal is to create a trusted common data set understood by the data owners. Typically, a data specification is created and the role of the data engineer is to apply transformations to match the specification. The end result is a data set in Parquet format that can be easily queried. It is critical that you choose the right partitions and optimize the data to perform internal queries. You may want to partially pre compute some aggregations at this stage to improve query performance.
Reporting Phase: This step is optional but often required. Unfortunately, when using a data lake, a single schema will not serve all use cases; this is one difference between a data warehouse and data lake. Querying HDFS is not as efficient as a database or data warehouse, so further optimizations are required. In this phase, you may need to denormalize the data to store it using different partitions so it can be queried more efficiently by the different stakeholders. The idea is to create different views optimized for the different downstream systems (data marts). In this phase you can also compute aggregations if you do not use an OLAP engine (see next section). The trusted phase does not know anything about who will query the data, this phase optimizes the data for the consumers. If a client is highly interactive, you may want to introduce a fast storage layer in this phase like a relational database for fast queries. Alternatively you can use OLAP engines which we will discuss later.
For streaming the logic is the same but it will run inside a defined DAG in a streaming fashion. Spark allows you to join stream with historical data but it has some limitations. We will discuss later on OLAP engines, which are better suited to merge real time with historical data.
Processing Frameworks
Some of the tools you can use for processing are:
Apache Spark: This is the most well known framework for batch processing. Part of the Hadoop ecosystem, it is a managed cluster which provides incredible parallelism, monitoring and a great UI. It also supports stream processing (structural streaming). Basically Spark runs MapReduce jobs in memory increasing up to 100x times regular MapReduce performance. It integrates with Hive to support SQL and can be used to create Hive tables, views or to query data. It has lots of integrations, supports many formats and has a huge community. It is supported by all cloud providers. It can run on YARN as part of a Hadoop cluster but also in Kubernetes and other platforms. It has many libraries for specific use cases such SQL or machine learning.
Apache Flink: The first engine to unify batch and streaming but heavily focus on streaming. It can be used as a backbone for microservices like Kafka. It can run on YARN as part of a Hadoop cluster but since its inception has been also optimized for other platforms like Kubernetes or Mesos. It is extremely fast and provides real time streaming, making it a better option than Spark for low latency stream processing, especially for stateful streams. It also has libraries for SQL, Machine Learning and much more.
Apache Storm: Apache Storm is a free and open source distributed real-time computation system.It focuses on streaming and it is a managed solution part of the Hadoop ecosystem. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
Apache Samza: Another great stateful stream processing engine. Samza allows you to build stateful applications that process data in real-time from multiple sources including Apache Kafka. Managed solution part of the Hadoop Ecosystem that runs on top of YARN.
Apache Beam: Apache Beam it is not an engine itself but a specification of an unified programming model that brings together all the other engines. It provides a programming model that can be used with different languages, so developers do not have to learn new languages when dealing with big data pipelines. Then, it plugs different back ends for the processing step that can run on the cloud or on premises. Beam supports all the engines mentioned before and you can easily switch between them and run them in any platform: cloud, YARN, Mesos, Kubernetes. If you are starting a new project, I really recommend starting with Beam to be sure your data pipeline is future proof.
By the end of this processing phase, you have cooked your data and is now ready to be consumed!, but in order to cook the chef must coordinate with his team…
Orchestration
Data pipeline orchestration is a cross cutting process which manages the dependencies between all the other tasks. If you use stream processing, you need to orchestrate the dependencies of each streaming app, for batch, you need to schedule and orchestrate the jobs.
Tasks and applications may fail, so you need a way to schedule, reschedule, replay, monitor, retry and debug your whole data pipeline in an unified way.
Newer frameworks such Dagster or Prefect add more capabilities and allow you to track data assets adding semantics to your pipeline.
Some of the options are:
Apache Oozie: Oozie it’s a scheduler for Hadoop, jobs are created as DAGs and can be triggered by time or data availability. It has integrations with ingestion tools such as Sqoop and processing frameworks such Spark.
Apache Airflow: Airflow is a platform that allows to schedule, run and monitor workflows. Uses DAGs to create complex workflows. Each node in the graph is a task, and edges define dependencies among the tasks. Airflow scheduler executes your tasks on an array of workers while following the specified dependencies described by you. It generates the DAG for you maximizing parallelism. The DAGs are written in Python, so you can run them locally, unit test them and integrate them with your development workflow. It also supports SLAs and alerting. Luigi is an alternative to Airflow with similar functionality but Airflow has more functionality and scales up better than Luigi.
Dagsteris a newer orchestrator for machine learning, analytics, and ETL. The main different is that you can track the inputs and outputs of the data, similar to Apache NiFicreating a data flow solution. You can also materialize other values as part of your tasks. It can also run several jobs in parallel, it is easy to add parameters, easy to test, provides simple versioning and much more. It is still a bit immature and due to the fact that it needs to keep track the data, it may be difficult to scale, which is a problem shared with NiFi.
Prefectis similar to Dagster, provides local testing, versioning, parameter management and much more. What makes Prefect different from the rest is that aims to overcome the limitations of Airflowexecution engine such as improved scheduler, Parametrized workflows, dynamic workflows, versioning and improved testing. It has an core open source workflow management system and also a cloud offering which requires no setup at all.
Apache NiFi: NiFi can also schedule jobs, monitor, route data, alert and much more. It is focused on data flow but you can also process batches. It runs outside of Hadoop but can trigger Spark jobs and connect to HDFS/S3.
In short, if your requirement is just orchestrate independent tasks that do not require to share data use Airflow or Ozzie. For data flow applications that require data lineage and tracking use NiFi for non developers or Dagster or Prefect for developers.
Data Quality
One important aspect in Big Data, often ignore is data quality and assurance. Companies loose every year tons of money because of data quality issues. The problem is that this is still an immature field in data science, developers have been working on this area for decades and they have great test frameworks and methodologies such BDD or TDD, but how do you test your pipeline?
There are two common problems in this field:
Misunderstood requirements: Quite often the transformation and orchestration logic can become very complex. Business Analyst may write requirements using their domain language which needs to be interpreted by developers who often make mistakes and plan, develop, test and deploy solutions who are technically correct but with the wrong requirements. These type of errors are very costly.
Data Validation: Pipeline testing is quite different from code. When developing software you test functions, it is black box testing, deterministic. For a given input you always get the same output. For data assets, testing is more complex: you need to assert data types, values, constraints and much more. Moreover, you need to apply aggregations to verify the data set to make sure that the number of rows or columns are corrects. For example, it is very hard to detect if one day you get a 10% drop on your data size, or if certain values correctly populated.
Companies are still at its infancy regarding data quality and testing, this creates a huge technical debt. I really recommend checking this article for more information.
To mitigate these issue, try to follow DDD principles and make sure that boundaries are set and a common language is used. Use frameworks that support data lineage like NiFi or Dagster.
Some tools focused on data quality are:
Apache Griffin: Part of the Hadoop Ecosystem, this tool offers an unified process to measure your data quality from different perspectives, helping you build trusted data assets. It provides a DSL that you can use to create assertions for your data and verify them as part of your pipeline. It is integrated with Spark. You can add rules and assertions for your data set and then run the validation as a Spark job. The problem with Griffin is the fact that the DSL can become difficult to manage(JSON) and it is hard to interpret by non- technical people which means it does not solve the misunderstood requirements issue.
Apache Griffin Processes
Great Expectations:This is a newer tool written in Python and focused on data quality, pipeline testing and quality assurance. It can be easily integrated with Airflow or other orchestration tools and provide automated data validation. What set this tool apart is the fact that is human readable and can be used by data analyst, BAs and developers. It provides a intuitive UI but also full automation so you can run the validations as part of your production pipeline and view the results in a nice UI. The assertions can be written by non technical people using Notebooks which provide documentation and formal requirements that developers can easily understand, translate to code and use for testing. BAs or testers write the data assertions (Expectations) which are transformed to human readable test in the UI so everyone can see them and verify them. It can also do data profiling to generate some assertions for you. It can connect directly to your databases or file systems on-prem or in the cloud. It is very easy to use and to manage. The expectations can be committed to the source code repository and then integrated in your pipeline. Great Expectations creates a common language and framework for all parties involved in data quality, making it veryeasy to automate and test your pipeline with minimal effort.
Great expectations UI
Query your data
Now that you have your cooked recipe, it is time to finally get the value from it. By this point, you have your data stored in your data lake using some deep storage such HDFS in a queryable format such Parquet or in a OLAP database.
There are a wide range of tools used to query the data, each one has its advantages and disadvantages. Most of them focused on OLAP but few are also optimized for OLTP. Some use standard formats and focus only on running the queries whereas others use their own format/storage to push processing to the source to improve performance. Some are optimized for data warehousing using star or snowflake schema whereas others are more flexible. To summarize these are the different considerations:
Data warehouse vs data lake
Hadoop vs Standalone
OLAP vs OLTP
Query Engine vs. OLAP Engines
We should also consider processing engines with querying capabilities.
Processing Engines
Most of the engines we described in the previous section can connect to the metadata server such as Hive and run queries, create views, etc. This is a common use case to create refined reporting layers.
Spark SQL provides a way to seamlessly mix SQL queries with Spark programs, so you can mix the DataFrame API with SQL. It has Hive integration and standard connectivity through JDBC or ODBC; so you can connect Tableau, Looker or any BI tool to your data through Spark.
Apache Flink also provides SQL API. Flink’s SQL support is based on Apache Calcite which implements the SQL standard. It also integrates with Hive through the HiveCatalog. For example, users can store their Kafka or ElasticSearch tables in Hive Metastore by using HiveCatalog, and reuse them later on in SQL queries.
Query Engines
This type of tools focus on querying different data sources and formats in an unified way. The idea is to query your data lake using SQL queries like if it was a relational database, although it has some limitations. Some of these tools can also query NoSQL databases and much more. These tools provide a JDBC interface for external tools, such as Tableau or Looker, to connect in a secure fashion to your data lake. Query engines are the slowest option but provide the maximum flexibility.
Apache Pig: It was one of the first query languages along with Hive. It has its own language different from SQL. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets. It is now in decline in favor of newer SQL based engines.
Presto: Released as open source by Facebook, it’s an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes. Presto allows querying data where it lives, including Hive, Cassandra, relational databases and file systems. It can perform queries on large data sets in a manner of seconds. It is independent of Hadoop but integrates with most of its tools, especially Hive to run SQL queries.
Apache Drill: Provides a schema-free SQL Query Engine for Hadoop, NoSQL and even cloud storage. It is independent of Hadoop but has many integrations with the ecosystem tools such Hive. A single query can join data from multiple datastores performing optimizations specific to each data store. It is very good at allowing analysts to treat any data like a table, even if they are reading a file under the hood. Drill supports fully standard SQL. Business users, analysts and data scientists can use standard BI/analytics tools such as Tableau, Qlik and Excel to interact with non-relational datastores by leveraging Drill’s JDBC and ODBC drivers. Furthermore, developers can leverage Drill’s simple REST API in their custom applications to create beautiful visualizations.
Drill model
OLTP Databases
Although, Hadoop is optimized for OLAP there are still some options if you want to perform OLTP queries for an interactive application.
HBasehas very limited ACID properties by design, since it was built to scale and does not provides ACID capabilities out of the box but it can be used for some OLTP scenarios.
Apache Phoenix is built on top of HBase and provides a way to perform OTLP queries in the Hadoop ecosystem. Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce. It also can store metadata and it supports table creation and versioned incremental alterations through DDL commands. It is quite fast, faster than using Drill or other query engine.
You may use any massive scale database outside the Hadoop ecosystem such as Cassandra, YugaByteDB, ScyllaDB for OTLP.
Finally, it is very common to have a subset of the data, usually the most recent, in a fast database of any type such MongoDB or MySQL. The query engines mentioned above can join data between slow and fast data storage in a single query.
Distributed Search Indexes
These tools provide a way to store and search unstructured text data and they live outside the Hadoop ecosystem since they need special structures to store the data. The idea is to use an inverted index to perform fast lookups. Besides text search, this technology can be used for a wide range of use cases like storing logs, events, etc. There are two main options:
Solr: it is a popular, blazing-fast, open source enterprise search platform built on Apache Lucene. Solr is reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. It is great for text search but its use cases are limited compared to ElasticSearch.
ElasticSearch: It is also a very popular distributed index but it has grown into its own ecosystem which covers many use cases like APM, search, text storage, analytics, dashboards, machine learning and more. It is definitely a tool to have in your toolbox either for DevOps or for your data pipeline since it is very versatile. It can also store and search videos and images.
ElasticSearch can be used as a fast storage layer for your data lake for advanced search functionality. If you store your data in a key-value massive database, like HBase or Cassandra, which provide very limited search capabilities due to the lack of joins; you can put ElasticSearch in front to perform queries, return the IDs and then do a quick lookup on your database.
It can be used also for analytics; you can export your data, index it and then query it using Kibana, creating dashboards, reports and much more, you can add histograms, complex aggregations and even run machine learning algorithms on top of your data. The Elastic Ecosystem is huge and worth exploring.
OLAP Databases
In this category we have databases which may also provide a metadata store for schemas and query capabilities. Compared to query engines, these tools also provide storage and may enforce certain schemas in case of data warehouses (star schema). These tools use SQL syntax and Spark and other frameworks can interact with them.
Apache Hive: We already discussed Hive as a central schema repository for Spark and other tools so they can use SQL, but Hive can also store data, so you can use it as a data warehouse. It can access HDFS or HBase. When querying Hive it leverages on Apache Tez, Apache Spark, or MapReduce, being Tez or Spark much faster. It also has a procedural language called HPL-SQL.
Apache Impala: It is a native analytic database for Hadoop, that you can use to store data and query it in an efficient manner. It can connect to Hive for metadata using Hcatalog. Impala provides low latency and high concurrency for BI/analytic queries on Hadoop (not delivered by batch frameworks such as Apache Hive). Impala also scales linearly, even in multitenant environments making a better alternative for queries than Hive. Impala is integrated with native Hadoop security and Kerberos for authentication, so you can securely managed data access. It uses HBase and HDFS for data storage.
Apache Tajo: It is another data warehouse for Hadoop. Tajo is designed for low-latency and scalable ad-hoc queries, online aggregation, and ETL on large-data sets stored on HDFS and other data sources. It has integration with HiveMetastore to access the common schemas. It has many query optimizations, it is scalable, fault tolerant and provides a JDBC interface.
Apache Kylin: Apache Kylin is a newer distributed Analytical Data Warehouse. Kylin is extremely fast, so it can be used to complement some of the other databases like Hive for use cases where performance is important such as dashboards or interactive reports, it is probably the best OLAP data warehouse but it is more difficult to use, another problem is that because of the high dimensionality, you need more storage. The idea is that if query engines or Hive are not fast enough, you can create a “Cube” in Kylin which is a multidimensional table optimized for OLAP with pre computed values which you can query from your dashboards or interactive reports. It can build cubes directly from Spark and even in near real time from Kafka.
OLAP Engines
In this category, I include newer engines that are an evolution of the previous OLAP databases which provide more functionality creating an all-in-one analytics platform. Actually, they are a hybrid of the previous two categories adding indexing to your OLAP databases. They live outside the Hadoop platform but are tightly integrated. In this case, you would typically skip the processing phase and ingest directly using these tools.
They try to solve the problem of querying real time and historical data in an uniform way, so you can immediately query real-time data as soon as it’s available alongside historical data with low latency so you can build interactive applications and dashboards. These tools allow in many cases to query the raw data with almost no transformation in an ELT fashion but with great performance, better than regular OLAP databases.
What they have in common is that they provided a unified view of the data, real time and batch data ingestion, distributed indexing, its own data format, SQL support, JDBC interface, hot-cold data support, multiple integrations and a metadata store.
Apache Druid: It is the most famous real time OLAP engine. It focused on time series data but it can be used for any kind of data. It uses its own columnar format which can heavily compress the data and it has a lot of built in optimizations like inverted indices, text encoding, automatic data roll up and much more. Data is ingested in real time using Tranquility or Kafka which has very low latency, data is kept in memory in a row format optimized for writes but as soon as it arrives is available to be query just like previous ingested data. A background task in in charge of moving the data asynchronously to a deep storage system such HDFS. When data is moved to deep storage it is converted into smaller chunks partitioned by time called segments which are highly optimized for low latency queries. Each segment has a timestamp, several dimensions which you can use to filter and perform aggregations; and metrics which are pre computed aggregations. For batch ingestion, it saves data directly into Segments. It support push and pull ingestion. It has integrations with Hive, Spark and even NiFi. It can use Hive metastore and it supports Hive SQL queries which then are converted to JSON queries used by Druid. The Hive integration supports JDBC so you can connect any BI tool. It also has its own metadata store, usually MySQL. It can ingest vast amounts of data and scale very well. The main issue is that it has a lot of components and it is difficult to manage and deploy.
Druid architecture
Apache Pinot: It is a newer alternative to Druid open sourced by LinkedIn. Compared to Druid, it offers lower latency thanks to the Startree index which offer partial pre computation, so it can be used for user facing apps(it’s used to get the LinkedIn feeds). It uses a sorted index instead of inverted index which is faster. It has an extendable plugin architecture and also has many integrations but does not support Hive. It also unifies batch and real time, provides fast ingestion, smart index and stores the data in segments. It is easier to deploy and faster compared to Druid but it is a bit immature at the moment.
Apache Pinot
ClickHouse: Written in C++, this engine provides incredible performance for OLAP queries, especially aggregations. It looks like a relational database so you can model the data very easily. It is very easy to set up and has many integrations.
ClickHouse
Check this article which compares the 3 engines in detail. Again, start small and know your data before making a decision, these new engines are very powerful but difficult to use. If you can wait a few hours, then use batch processing and a data base such Hive or Tajo; then use Kylin to accelerate your OLAP queries to make them more interactive. If that’s not enough and you need even lower latency and real time data, consider OLAP engines. Druid is more suitable for real-time analysis. Kylin is more focused on OLAP cases. Druid has good integration with Kafka as real-time streaming; Kylin fetches data from Hive or Kafka in batches; although real time ingestion is planned for the near future.
Finally, Greenplum is another OLAP engine with more focus on AI.
Presto/Drill provide more flexibility, Kylin great latency, Druid and Pinot, the best of both worlds.
Finally, for visualization you have several commercial tools such Qlik, Looker or Tableau. For Open Source, check SuperSet, an amazing tool that support all the tools we mentioned, has a great editor and it is really fast. Metabase or Falcon are other great options.
Conclusion
We have talked a lot about data: the different shapes, formats, how to process it, store it and much more. Remember: Know your data and your business model. Use an iterative process and start building your big data platform slowly; not by introducing new frameworks but by asking the right questions and looking for the best tool which gives you the right answer.
Review the different considerations for your data, choose the right storage based on the data model (SQL), the queries(NoSQL), the infrastructure and your budget. Remember to engage with your cloud provider and evaluate cloud offerings for big data(buy vs. build). It is very common to start with a Serverless analysis pipeline and slowly move to open source solutions as costs increase.
Data Ingestion is critical and complex due to the dependencies to systems outside of your control; try to manage those dependencies and create reliable data flows to properly ingest data. If possible have other teams own the data ingestion. Remember to add metrics, logs and traces to track the data. Enable schema evolution and make sure you have setup proper security in your platform.
Use the right tool for the job and do not take more than you can chew. Tools like Cassandra, Druid or ElasticSearch are amazing technologies but require a lot of knowledge to properly use and manage. If you just need to OLAP batch analysis for ad-hoc queries and reports, use Hive or Tajo. If you need better performance, add Kylin. If you also need to join with other data sources add query engines like Drill or Presto. Furthermore, if you need to query real time and batch use ClickHouse, Druid or Pinot.
Feel free to get in touch if you have any questions or need any advice.
I hope you enjoyed this article. Feel free to leave a comment or share this post. Follow mefor future post.