Jupyter is now a full-fledged IDE
Literate programming is now a reality through nbdev and the new visual debugger for Jupyter.

Notebooks have always been a tool for incremental development of software ideas. Data scientists use Jupyter to journal their work, explore and experiment with novel algorithms, quickly sketch new approaches and immediately observe the outcomes.
However, when the time is ripe, software developers turn to classical IDEs (Integrated Development Environment), such as Visual Studio Code and Pycharm, to convert the ideas into libraries and frameworks. But is there a way to transform Jupyter into a full-fledged IDE, where raw concepts are translated into robust and reusable modules?
To this end, developers from several institutions, including QuantStack, Two Sigma, Bloomberg and fast.ai developed two novel tools; nbdev and a visual debugger for Jupyter.
Literate Programming and nbdev
In 1983, Donald Knuth came up with a new programming paradigm call literate programming. In his own words literate programming is “a methodology that combines a programming language with a documentation language, thereby making programs more robust, more portable, more easily maintained, and arguably more fun to write than programs that are written only in a high-level language. The main idea is to treat a program as a piece of literature, addressed to human beings rather than to a computer”.
Jeremy Howard and Sylvain Gugger, fascinated by that design presented nbdev later last year. This framework allows you to compose your code in the familiar Jupyter Notebook environment, exploring and experimenting with different approaches before reaching an effective solution for a given problem. Then, using certain keywords, nbdev permits you to extract the useful functionality into a full-grown python library.
More specifically, nbdev complements Jupyter by adding support for:
- automatic creation of python modules from notebooks, following best practices
- editing and navigation of the code in a standard IDE
- synchronization of any changes back into the notebooks
- automatic creation of searchable, hyperlinked documentation from the code
- pip installers readily uploaded to PyPI
- testing
- continuous-integration
- version control conflict handling
nbdev enables software developers and data scientists to develop well-documented python libraries, following best practices without leaving the Jupyter environment. nbdev is on PyPI so to install it you just run:
pip install nbdevFor an editable install, use the following:
git clone https://github.com/fastai/nbdev
pip install -e nbdevTo get started, read the excellent blog post by its developers, describing the notion behind nbdev and follow the detailed tutorial in the documentation.
The missing piece
Though nbdev covers most of the tools needed for an IDE-like development inside Jupyter, there is still a piece missing; a visual debugger.
Therefore, a team of developers from several institutions announced yesterday the first public release of the Jupyter visual debugger. The debugger offers most of what you would expect from an IDE debugger:
- a variable explorer, a list of breakpoints and a source preview
- the possibility to navigate the call stack (next line, step in, step out etc.)
- the ability to set breakpoints intuitively, next to the line of interest
- flags to indicate where the current execution has stopped
To take advantage of this new tool we need a kernel implementing the Jupyter debug protocol in the back-end. Hence, the first step is to install such a kernel. The only one that implements it so far is xeus-python. To install it just run:
conda install xeus-python -c conda-forgeThen, run Jupyter Lab and on the sidebar search for the Extension Manager and enable it, if you haven’t so far.
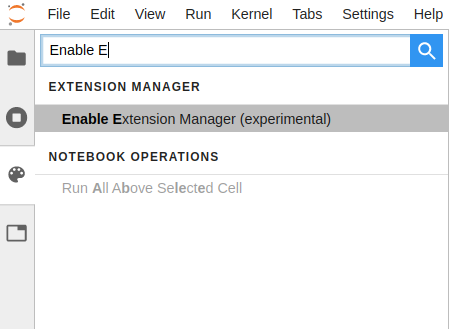
A new button will appear on the sidebar. To install the debugger just go to the newly enabled Extension Manager button and search for the debugger extension.
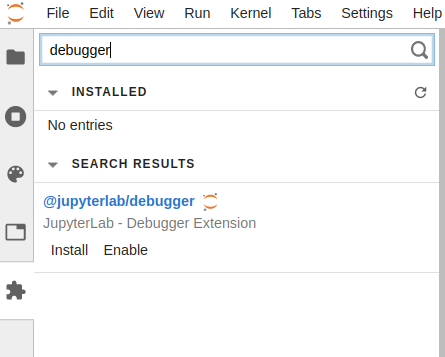
After installing it Jupyter Lab will ask you to perform a build to include the latest changes. Accept it, and, after a few seconds, you are good to go.
To test the debugger, we create a new xpython notebook and compose a simple function. We run the function as usual and observe the result. To enable the debugger, press the associated button on the top right of the window.
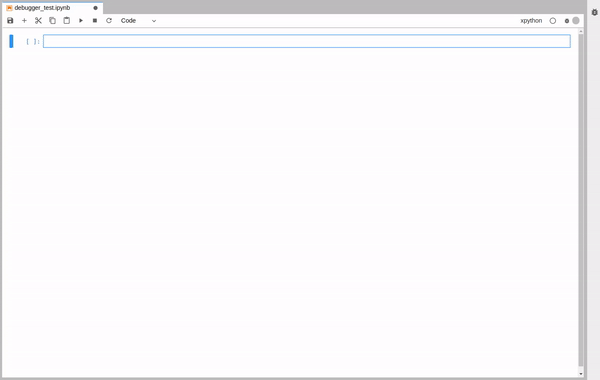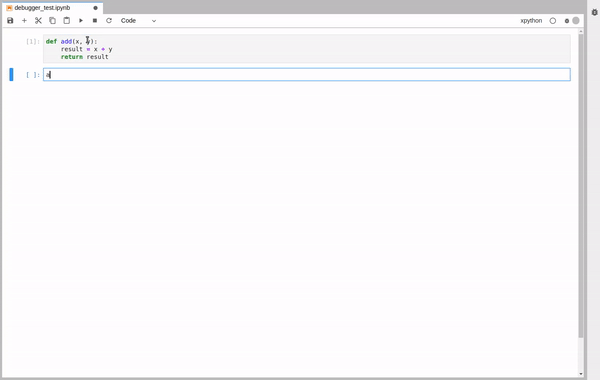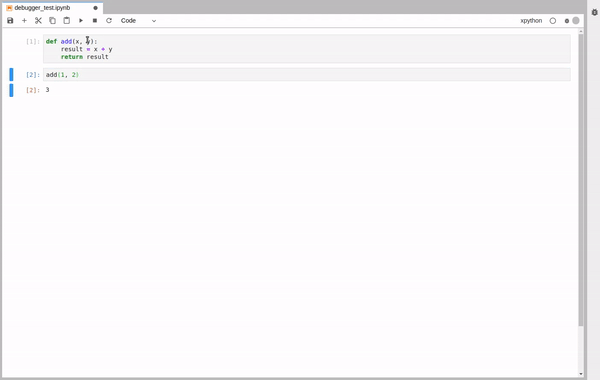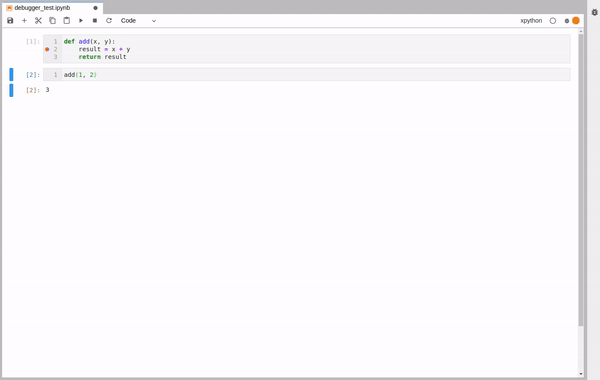
Now, we are ready to run the function again. Only this time the execution will stop at the breakpoint we set and we will be able to explore the state of the program.
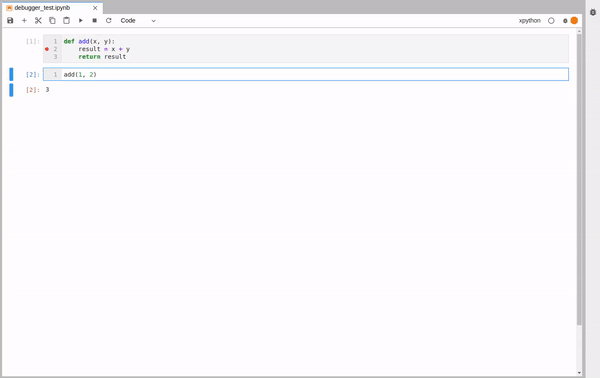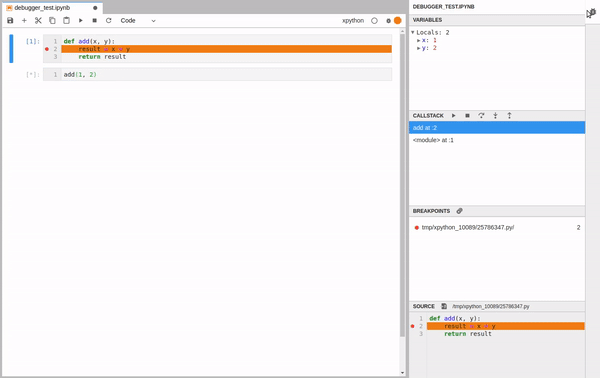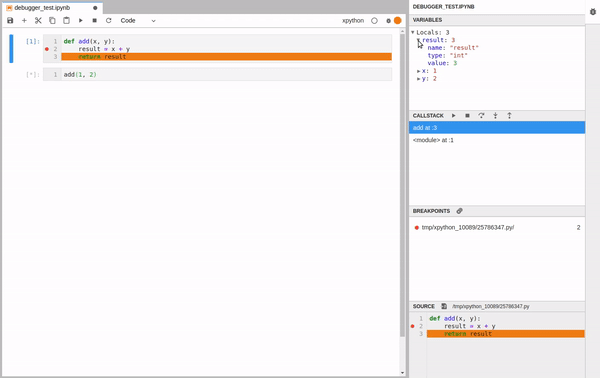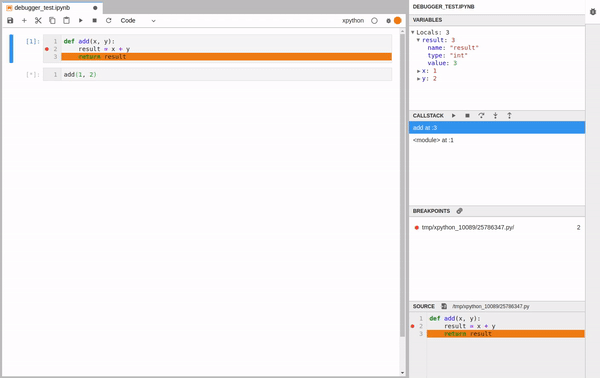
We see that the program stopped at the breakpoint. Opening the debugger panel we see the variables, a list of breakpoints, the call stack navigation and the source code.
The new visual debugger for Jupyter offers everything you would expect from an IDE debugger. It is still in development, thus, new functionality is expected. Some of the features that its developers plan to release in 2020 are:
- Support for rich mime type rendering in the variable explorer
- Support for conditional breakpoints in the UI
- Enable the debugging of Voilà dashboards, from the JupyterLab Voilà preview extension
- Enable debugging with as many kernels as possible
Conclusion
Jupyter notebooks have always been a great way to explore and experiment with your code. However, software developers usually turn to a full-fledged IDE, copying the parts that work, to produce a production-ready library.
This is not only inefficient but also a loss on the Jupyter offering; literate programming. Moreover, notebooks provide an environment for better documentation, including graphs, images and videos, and sometimes better tools, such as auto-complete functionality.
nbdev and the visual debugger are two projects that aim at closing the gap between notebooks and IDEs. In this story, we saw what nbdev is and how it makes literate programming a reality. Furthermore, we discovered how a new project, the visual debugger for Jupyter, provides the missing piece.
My name is Dimitris Poulopoulos and I’m a machine learning researcher at BigDataStack and PhD(c) at the University of Piraeus, Greece. I have worked on designing and implementing AI and software solutions for major clients such as the European Commission, Eurostat, IMF, the European Central Bank, OECD, and IKEA. If you are interested in reading more posts about Machine Learning, Deep Learning and Data Science, follow me on Medium, LinkedIn or @james2pl on twitter.
'Data Analytics(en)' 카테고리의 다른 글
| Please Stop Doing These 5 Things in Pandas (0) | 2020.09.27 |
|---|---|
| Interactive spreadsheets in Jupyter (0) | 2020.09.26 |
| Pandas DataFrame (Python): 10 useful tricks (0) | 2020.09.25 |
| Introducing Bamboolib — a GUI for Pandas (0) | 2020.09.25 |
| Handling exceptions in Python a cleaner way, using Decorators (0) | 2020.09.25 |