고급 Python : 클래스를 정의 할 때 적용 할 9 가지 모범 사례
코드를 더 읽기 쉽고 유지 관리하기 쉽게 만드는 방법
핵심에서 Python은 객체 지향 프로그래밍 (OOP) 언어입니다. OOP 언어이기 때문에 Python은 객체 중심의 다양한 기능을 지원하여 데이터와 기능을 처리합니다. 예를 들어 데이터 구조는 일부 다른 언어에서 객체로 간주되지 않는 기본 유형 (예 : 정수 및 문자열)을 포함한 모든 객체입니다. 또 다른 예로, 함수는 모든 객체이며, 정의 된 다른 객체 (예 : 클래스 또는 모듈)의 속성 일뿐입니다.
기본 제공 데이터 유형을 사용하고 사용자 지정 클래스를 만들지 않고도 여러 함수를 작성할 수 있지만 프로젝트 범위가 커지면 코드를 유지 관리하기가 더 어려워 질 수 있습니다. 이러한 개별 부분에는 공유 된 테마가 없으며 많은 정보가 관련되어 있지만 이들 간의 연결을 관리하는 데 많은 번거 로움이 있습니다.
이러한 시나리오에서는 관련 정보를 그룹화하고 프로젝트의 구조 설계를 개선 할 수 있도록 고유 한 클래스를 정의하는 것이 좋습니다. 더 중요한 것은 코드 조각이 덜 조각 된 코드를 다루게되므로 코드베이스의 장기적인 유지 관리 가능성이 향상된다는 것입니다. 그러나 한 가지 문제가 있습니다. 이것은 사용자 정의 클래스를 정의하는 이점이 관리 오버 헤드보다 클 수 있도록 클래스 선언이 올바른 방식으로 수행 된 경우에만 해당됩니다.
이 기사에서는 사용자 정의 클래스에 적용 할 수있는 9 가지 중요한 모범 사례를 검토하고자합니다.
1. 좋은 이름
자신 만의 클래스를 정의 할 때 코드베이스에 새로운 아기를 추가하는 것입니다. 수업에 아주 좋은 이름을 지정해야합니다. 클래스 이름의 유일한 제한은 합법적 인 Python 변수의 규칙 (예 : 숫자로 시작할 수 없음)이지만 클래스 이름을 지정하는 데 선호되는 방법이 있습니다.
- 발음하기 쉬운 명사를 사용하십시오.팀 프로젝트에서 작업하는 경우 특히 중요합니다. 그룹 프레젠테이션 중에 "이 경우에는 Zgnehst 클래스의 인스턴스를 만듭니다."라고 말하는 사람이되고 싶지 않을 것입니다. 또한 발음하기 쉽다는 것은 이름이 너무 길어서는 안된다는 의미이기도합니다. 클래스 이름을 정의하기 위해 3 개 이상의 단어를 사용해야하는 경우는 거의 생각할 수 없습니다. 한 단어가 가장 좋고 두 단어가 좋고 세 단어가 한계입니다.
- 저장된 데이터와 의도 한 기능을 반영합니다.마치 우리의 실제 생활과 같습니다. 소년에게는 소년 이름이 주어집니다. 남자 아이 이름을 보면 아이들이 남자 일 것으로 예상합니다. 클래스 이름 (또는 일반적으로 다른 변수)에도 적용됩니다. 규칙은 간단합니다 — 사람들을 놀라게하지 마십시오. 학생의 정보를 다루는 경우 수업 이름은 Student로 지정해야합니다. KiddosAtCampus는 가장 상식적인 말이 아닙니다.
- 명명 규칙을 따르십시오.GoodName과 같은 클래스 이름에는 대문자 낙타 스타일을 사용해야합니다. 다음은 goodName, Good_Name, good_name 및 GOodnAme와 같은 비 전통적인 클래스 이름의 불완전한 목록입니다. 명명 규칙을 따르는 것은 의도를 명확하게하는 것입니다. 사람들이 코드를 읽을 때 GoodName과 같은 이름을 가진 객체가 클래스라고 안전하게 가정 할 수 있습니다.
속성 및 함수에 적용되는 명명 규칙 및 규칙도 있습니다. 아래 섹션에서 해당되는 경우 간략하게 언급하지만 전체 원칙은 동일합니다. 유일한 경험 법칙은 간단합니다. 사람들을 놀라게하지 마십시오.
2. 명시 적 인스턴스 속성
대부분의 경우 자체 인스턴스 초기화 방법 (예 :__init__). 이 메서드에서는 새로 생성 된 클래스 인스턴스의 초기 상태를 설정합니다. 하지만 Python은 커스텀 클래스로 인스턴스 속성을 정의 할 수있는 위치를 제한하지 않습니다. 즉, 인스턴스가 생성 된 후 이후 작업에서 추가 인스턴스 속성을 정의 할 수 있습니다. 다음 코드는 가능한 시나리오를 보여줍니다.
위와 같이 인스턴스를 만들 수 있습니다.학생학생의 이름과 성을 지정하여 수업. 나중에 인스턴스 메서드를 호출 할 때 (즉,verify_registration_status),학생인스턴스의 상태 속성이 설정됩니다. 그러나 이것은 원하는 패턴이 아닙니다. 전체 클래스에 다양한 인스턴스 속성을 분산하면 인스턴스 객체가 어떤 데이터를 보유하고 있는지 클래스가 명확하게 할 수 없기 때문입니다. 따라서 모범 사례는 인스턴스의 속성을__init__메소드를 사용하면 아래와 같이 코드 리더가 클래스의 데이터 구조를 알 수있는 단일 위치를 갖게됩니다.
처음에 설정할 수없는 인스턴스 속성의 경우 다음과 같은 자리 표시 자 값으로 설정할 수 있습니다.없음. 그다지 문제가되지 않지만이 변경 사항은 일부 인스턴스 메서드를 호출하여 해당 인스턴스 속성을 설정하는 것을 잊었을 때 발생할 수있는 오류를 방지하는데도 도움이됩니다.AttributeError(‘학생’개체에‘status_verified’속성이 없습니다.).
이름 지정 규칙과 관련하여 속성은 소문자를 사용하여 이름을 지정하고 뱀 케이스 스타일을 따라야합니다. 즉, 여러 단어를 사용하는 경우 밑줄로 연결해야합니다. 또한 모든 이름에는 보유한 데이터에 대한 의미있는 표시가 있어야합니다 (예 :이름~보다 낫다fn).
3. 속성 사용-그러나 간결하게
어떤 사람들은 자바와 같은 다른 OOP 언어의 기존 배경으로 Python 코딩을 배우고 인스턴스 속성에 대한 getter 및 setter를 만드는 데 사용됩니다. 이 패턴은 Python에서 속성 데코레이터를 사용하여 모방 할 수 있습니다. 다음 코드는 속성 데코레이터를 사용하여 getter 및 setter를 구현하는 기본 형식을 보여줍니다.
이 속성이 생성되면 내부 함수를 사용하여 구현되지만 점 표기법을 사용하여 일반 속성으로 사용할 수 있습니다.
아시다시피 속성 구현을 사용하는 이점에는 적절한 값 설정 (정수가 아닌 문자열이 사용되는지 확인) 및 읽기 전용 액세스 (setter 메서드를 구현하지 않음)가 포함됩니다. 그러나 속성을 간결하게 사용해야합니다. 사용자 정의 클래스가 아래와 같이 보이면 매우 산만해질 수 있습니다. 속성이 너무 많습니다!
대부분의 경우 이러한 속성은 인스턴스 속성으로 대체 될 수 있으므로 이러한 속성에 액세스하여 직접 설정할 수 있습니다. 논의 된대로 속성 사용의 이점 (예 : 값 확인)에 대한 특정 요구 사항이없는 경우 속성을 사용하는 것이 Python에서 속성을 만드는 것보다 선호됩니다.
4. 의미있는 문자열 표현 정의
파이썬에서는 이름 앞뒤에 이중 밑줄이있는 함수를 특수 또는 매직 메서드라고하며 어떤 사람들은이를 dunder 메서드라고합니다. 그들은 다음을 포함하여 통역사의 기본 작업에 특별한 용도가 있습니다.__init__이전에 다룬 방법입니다. 두 가지 특별한 방법,__repr__과__str__는 사용자 정의 클래스의 적절한 문자열 표현을 만드는 데 필수적이며 코드 판독기에게 클래스에 대한보다 직관적 인 정보를 제공합니다.
그들 사이의 주요 차이점은__repr__메소드는 문자열을 정의합니다.이를 사용하여 다음을 호출하여 객체를 다시 만들 수 있습니다.eval (repr ( "repr")), 동안__str__메소드는 더 설명적이고 더 많은 사용자 정의를 허용하는 문자열을 정의합니다. 즉, 정의 된 문자열이__repr__방법은 개발자가 보는 동안__str__방법은 일반 사용자가 볼 수 있습니다. 다음은 예를 보여줍니다.
양해 해주십시오.__repr__메서드 구현 (7 행), f- 문자열은!아르 자형올바른 형식의 문자열로 인스턴스를 구성하는 데 필요하기 때문에 따옴표로 이러한 문자열을 표시합니다. ! r 형식이 없으면 문자열은학생 (John, Smith)을 구성하는 올바른 방법이 아닙니다.학생예. 이러한 구현이 문자열을 어떻게 보여 주는지 살펴 보겠습니다. 특히__repr__대화 형 인터프리터에서 개체에 액세스 할 때 메서드가 호출되고__str__메서드는 개체를 인쇄 할 때 기본적으로 호출됩니다.
5. 인스턴스, 클래스 및 정적 메서드
클래스에서 우리는 인스턴스, 클래스, 정적 메서드의 세 종류의 메서드를 정의 할 수 있습니다. 관심있는 기능에 어떤 방법을 사용해야하는지 고려해야합니다. 다음은 몇 가지 일반적인 지침입니다.
예를 들어 메서드가 개별 인스턴스 개체와 관련된 경우 인스턴스의 특정 속성에 액세스하거나 업데이트해야합니다.이 경우 인스턴스 메서드를 사용해야합니다. 이러한 메서드에는 다음과 같은 서명이 있습니다.def do_something (self) :, 여기서본인인수는 메서드를 호출하는 인스턴스 개체를 참조합니다. 에 대해 더 알고본인인수, 당신은 참조 할 수 있습니다내 이전 기사이 주제에.
메서드가 개별 인스턴스 개체와 관련이없는 경우 클래스 또는 정적 메서드 사용을 고려해야합니다. 두 방법 모두 적용 가능한 데코레이터로 쉽게 정의 할 수 있습니다.classmethod과staticmethod. 이 두 가지의 차이점은 클래스 메서드를 사용하면 클래스와 관련된 속성에 액세스하거나 업데이트 할 수 있지만 정적 메서드는 인스턴스 또는 클래스 자체와 독립적이라는 것입니다. 클래스 메서드의 일반적인 예는 편리한 인스턴스화 메서드를 제공하는 반면 정적 메서드는 단순히 유틸리티 함수일 수 있습니다. 다음 코드는 몇 가지 예를 보여줍니다.
비슷한 방식으로 클래스 속성을 만들 수도 있습니다. 앞에서 논의한 인스턴스 속성과 달리 클래스 속성은 모든 인스턴스 객체에서 공유되며 개별 인스턴스 객체와 독립적 인 일부 특성을 반영해야합니다.
6. 개인 속성을 사용한 캡슐화
프로젝트를위한 사용자 정의 클래스를 작성할 때 특히 다른 사람들이 클래스를 사용할 것으로 예상되는 경우 캡슐화를 고려해야합니다. 클래스의 기능이 커지면 일부 함수 또는 속성은 클래스 내의 데이터 처리에만 관련됩니다. 즉, 클래스 외부에서는 이러한 함수가 호출되지 않으며 클래스의 다른 사용자는 이러한 함수의 구현 세부 사항에 대해 신경 쓰지 않습니다. 이러한 시나리오에서는 캡슐화를 고려해야합니다.
캡슐화를 적용하는 한 가지 중요한 방법은 규칙에 따라 밑줄 또는 두 개의 밑줄을 접두사로 속성 및 함수에 추가하는 것입니다. 미묘한 차이점은 밑줄이있는 항목은보호, 두 개의 밑줄이있는 항목은은밀한, 생성 후 이름 변경이 포함됩니다. 이 두 범주를 구별하는 것은이 기사의 범위를 벗어납니다.내 이전 기사 중 하나그들을 덮었습니다.
본질적으로 속성과 함수의 이름을 이렇게 지정하면 IDE (예 : PyCharm과 같은 통합 개발 환경)에 실제 개인 속성이 존재하지 않더라도 클래스 외부에서 액세스하지 않을 것임을 알립니다. 파이썬. 즉, 우리가 선택하면 여전히 액세스 할 수 있습니다.
위의 코드는 캡슐화의 간단한 예를 보여줍니다. 학생의 경우 평균 GPA를 아는 데 관심이있을 수 있으며 다음을 사용하여 점수를 얻을 수 있습니다.get_mean_gpa방법. 사용자는 평균 GPA가 어떻게 계산되는지 알 필요가 없습니다. 따라서 함수 이름 앞에 밑줄을 추가하여 관련 방법을 보호 할 수 있습니다.
이 모범 사례의 핵심 사항은 사용자가 코드를 사용하는 데 필요한 최소한의 공용 API 만 노출한다는 것입니다. 내부적으로 만 사용되는 경우 보호 또는 개인 방법으로 만드십시오.
7. 별도의 우려 사항 및 분리
프로젝트를 개발하면서 더 많은 데이터를 처리하고 있다는 사실을 알게되었으며, 하나의 클래스를 고수하는 경우 클래스가 번거로울 수 있습니다. 예를 들어 계속하겠습니다.학생수업. 학생들이 학교에서 점심을 먹고 각자 식사 비용을 지불하는 데 사용할 수있는 식사 계정을 가지고 있다고 가정합니다. 이론적으로는 계정 관련 데이터 및 기능을 다룰 수 있습니다.학생아래와 같이 클래스.
위의 코드는 계정 잔액을 확인하고 계정에 돈을로드하는 데 대한 의사 코드를 보여줍니다. 둘 다학생수업. 분실 된 카드 일시 중지, 계정 통합과 같이 계정과 관련 될 수있는 더 많은 작업이 있다고 상상해보십시오. 이러한 작업을 모두 구현하면학생클래스가 점점 커지면서 점차 유지하기가 더 어려워집니다. 대신 이러한 책임을 분리하고학생이러한 계정 관련 기능에 대해 무책임한 클래스 — 다음과 같은 디자인 패턴디커플링.
위의 코드는 추가로 데이터 구조를 설계하는 방법을 보여줍니다.계정수업. 보시다시피 모든 계정 관련 작업을계정수업. 학생의 계정 정보를 검색하려면학생클래스는 정보를 검색하여 기능을 처리합니다.계정수업. 클래스와 관련된 더 많은 기능을 구현하려면 간단히 업데이트 할 수 있습니다.계정수업 만.
디자인 패턴의 주요 요점은 개별 수업에 별도의 문제가 있기를 원한다는 것입니다. 이러한 책임을 분리하면 더 작은 코드 구성 요소를 다루게되므로 클래스가 더 작아지고 향후 변경이 더 쉬워집니다.
8. 최적화를 위해 __slots__ 고려
클래스가 데이터 만 저장하기위한 데이터 컨테이너로 주로 사용되는 경우__ 슬롯 __수업의 성능을 최적화합니다. 속성 액세스 속도를 높일뿐만 아니라 메모리도 절약하므로 수천 개 이상의 인스턴스 객체를 만들어야하는 경우 큰 이점이 될 수 있습니다. 그 이유는 일반 클래스의 경우 인스턴스 속성이 내부적으로 관리되는 사전을 통해 저장되기 때문입니다. 대조적으로,__ 슬롯 __, 인스턴스 속성은 내부적으로 C를 사용하여 구현 된 어레이 관련 데이터 구조를 사용하여 저장되며 성능은 훨씬 더 높은 효율성으로 최적화됩니다.
위의 코드는 우리가 어떻게 구현하는지에 대한 간단한 예를 보여줍니다.__ 슬롯 __수업에서. 특히 모든 속성을 시퀀스로 나열하면 더 빠른 액세스와 적은 메모리 소비를 위해 데이터 저장소에서 일대일 일치가 생성됩니다. 방금 언급했듯이 일반 클래스는 속성 액세스를 위해 사전을 사용하지만__ 슬롯 __구현되었습니다. 다음 코드는 그러한 사실을 보여줍니다.
사용에 대한 자세한 설명__ 슬롯 __에 대한 좋은 답변에서 찾을 수 있습니다.스택 오버플로, 그리고 당신은 공식에서 더 많은 정보를 찾을 수 있습니다선적 서류 비치. 더 빠른 액세스와 절약 된 메모리의 이점에 관해서는최근 매체 기사아주 좋은 시연이 있습니다. 여기에 대해 자세히 설명하지 않겠습니다. 그러나 한 가지 주목할 점은__ 슬롯 __부작용이 있습니다. 이는 추가 속성을 동적으로 생성하지 못하게합니다. 어떤 사람들은 클래스의 속성을 제어하는 메커니즘으로이를 제안하지만 디자인 방식이 아닙니다.
9. 문서
마지막으로, 수업 문서에 대해 이야기해야합니다. 가장 중요한 것은 문서 작성이 코드를 대체하는 것이 아니라는 점을 이해해야한다는 것입니다. 수많은 문서를 작성한다고해서 코드의 성능이 향상되는 것은 아니며 반드시 코드를 더 읽기 쉽게 만드는 것도 아닙니다. 코드를 명확히하기 위해 독 스트링에 의존해야하는 경우 코드에 문제가있을 가능성이 큽니다. 나는 당신의 코드가 그 자체로 모든 것을 말해야한다고 진정으로 믿습니다. 다음 코드는 일부 프로그래머가 할 수있는 실수를 보여줍니다. 불필요한 주석을 사용하여 잘못된 코드를 보완합니다 (즉,이 경우 의미없는 변수 이름). 반대로 좋은 이름을 가진 좋은 코드는 주석이 필요하지 않습니다.
댓글과 독 스트링 작성에 반대한다는 말은 아니지만 실제로 사용 사례에 따라 다릅니다. 여러 사람이 코드를 사용하거나 두 번 이상 사용하는 경우 (예 : 코드에 액세스하는 유일한 사람이지만 여러 번) 좋은 댓글 작성을 고려해야합니다. 자신이나 팀원이 코드를 읽는 데 도움을 줄 수 있지만, 코드가 주석에서 말한대로 정확하게 작동한다고 가정해서는 안됩니다. 즉, 좋은 코드를 작성하는 것이 항상 명심해야 할 최우선 순위입니다.
최종 사용자가 코드의 특정 부분을 사용하는 경우 해당 사용자가 관련 코드베이스에 익숙하지 않기 때문에 독 스트링을 작성하는 것이 좋습니다. 그들이 알고 싶은 것은 관련 API를 사용하는 방법 뿐이며, docstring은 도움말 메뉴의 기초를 형성합니다. 따라서 프로그램 사용 방법에 대한 명확한 지침을 제공하는 것은 프로그래머의 책임입니다.
결론
이 기사에서는 자신의 클래스를 정의 할 때 고려해야 할 중요한 요소를 검토했습니다. Python이나 일반적인 프로그래밍을 처음 접한다면 지금까지 논의한 모든 측면을 완전히 이해하지 못할 수도 있습니다. 괜찮습니다. 더 많이 코딩할수록 클래스를 정의하기 전에 이러한 원칙을 염두에 두는 것의 중요성을 더 많이 알게 될 것입니다. 좋은 디자인은 나중에 개발 시간을 많이 절약 할 수 있기 때문에 클래스 작업을 할 때 이러한 지침을 계속해서 연습하십시오.
'Data Analytics(ko)' 카테고리의 다른 글
| Change The Way You Write Python Code With One Extra Character -번역 (0) | 2020.10.26 |
|---|---|
| Data-Preprocessing with Python -번역 (0) | 2020.10.25 |
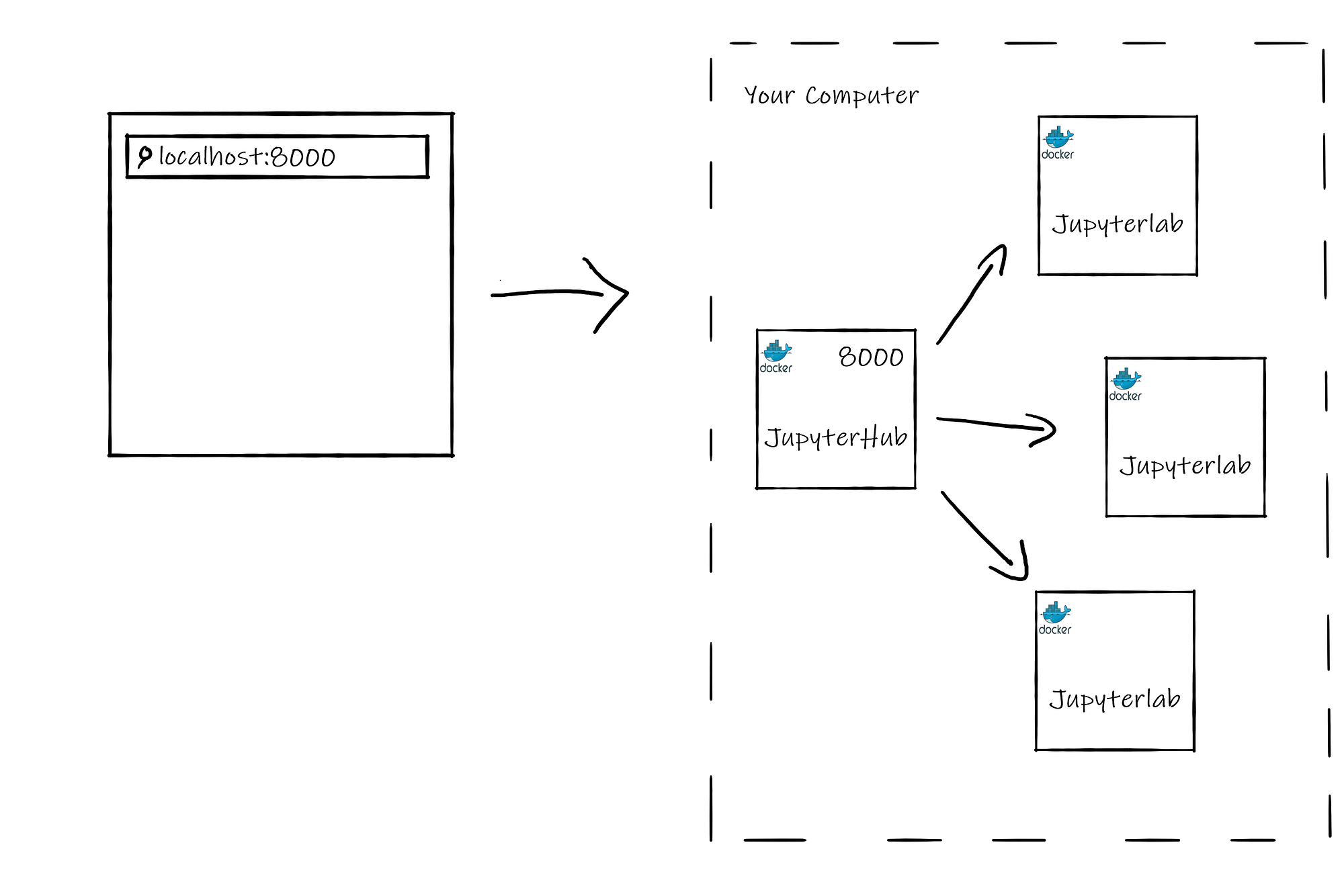
| Tutorial: Stop Running Jupyter Notebooks from your Command Line! -번역 (0) | 2020.10.23 |
| 7 Python Tricks You Should Know -번역 (0) | 2020.10.22 |
| Advanced Python: Consider These 10 Elements When You Define Python Functions -번역 (0) | 2020.10.21 |











{kind=link}